您现在的位置是:【C++】string类的模拟实现 >>正文
【C++】string类的模拟实现
德薄能鲜网919人已围观
简介目录1、string类的模拟实现1.1 经典的string类问题1.2 浅拷贝1.3 深拷贝1.4 String类拷贝构造与operator=的传统与现代写法1.4.1传统写法1.4.2现代写...
目录
1、string类的模拟实现
1.1 经典的string类问题
1.2 浅拷贝
1.3 深拷贝
1.4 String类拷贝构造与operator=的传统与现代写法
1.4.1传统写法
1.4.2现代写法
1.5string其他接口
2、 vs和g++下string结构的说明
2.1vs下string的结构
2.2g++下string的结构
3. 写时拷贝(了解)
4. 扩展阅读
1、string类的模拟实现
1.1 经典的string类问题
前文已经对string类进行了简单的介绍,大家只要能够正常使用即可。在面试中,面试官总喜欢让
应试者自己来模拟实现string类,最主要是实现string类的构造、拷贝构造、赋值运算符重载以及析
构函数。
// 为了和标准库区分,此处使用Stringclass String{ public: /*String() :_str(new char[1]) { *_str = '\0';} */ //String(const char* str = "\0") 错误示范 //String(const char* str = nullptr) 错误示范 String(const char* str = "") { // 构造String类对象时,如果传递nullptr指针,可以认为程序非法 if (nullptr == str) { assert(false); return; } _str = new char[strlen(str) + 1]; strcpy(_str, str);//将用于拷贝的字符串中数据拷贝到string中 } ~String() { if (_str) { delete[] _str;//释放空间 _str = nullptr; } }private: char* _str;};// 测试void TestString(){ String s1("hello bit!!!"); String s2(s1);}需要注意的是库中的string没有传值会默认构造空字符串,因此我们实现一样的功能要注意C++的空字符串是默认会有\0,因此“\0”这样写实际上有两个空字符串,我们只需要“”这样写,会自动加上\0,这样就是一个合格的空字符串了。
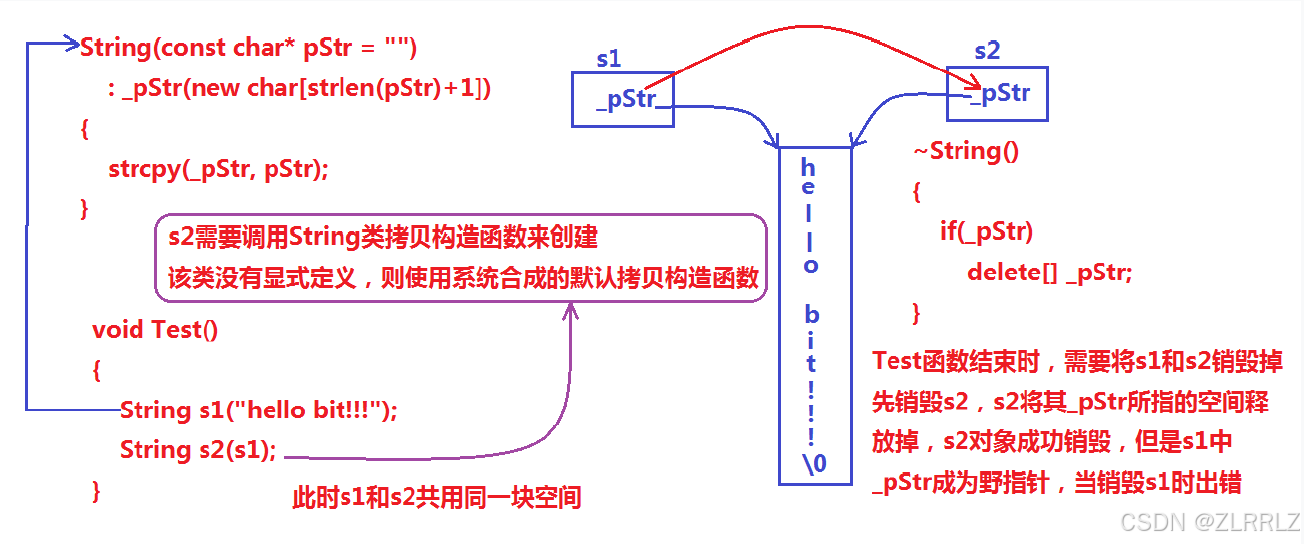
说明:上述String类没有显式定义其拷贝构造函数与赋值运算符重载,此时编译器会自动生成默认
的,当用s1构造s2时,编译器会调用默认的拷贝构造。最终导致的问题是,s1、s2共用同一块内
存空间,在释放时同一块空间被释放多次而引起程序崩溃,这种拷贝方式,称为浅拷贝。
1.2 浅拷贝
浅拷贝:也称位拷贝,s是指编译器只是将对象中的值按照字节一个一个拷贝过来。如果对象中管理资源,最后就会导致多个对象共享同一份资源,当一个对象销毁时就会将该资源释放掉,而此时另一些对象不知道该资源已经被释放,以为还有效,所以当继续对资源进项操作时,就会发生发生了访问违规。
就像一个家庭中有两个孩子,但父母只买了一份玩具,两个孩子愿意一块玩,则万事大吉,万一不想分享就你争我夺,玩具损坏。

可以采用深拷贝解决浅拷贝问题,即:每个对象都有一份独立的资源,不要和其他对象共享。
就像父母给每个孩子都买一份玩具,各自玩各自的就不会有问题了。

1.3 深拷贝
如果一个类中涉及到资源的管理,其拷贝构造函数、赋值运算符重载以及析构函数必须要显式给出,否则由编译器实现,内置类型会进行浅拷贝,程序会出错。一般情况都是按照深拷贝方式提供。所谓深拷贝就是先为目标对象申请单独的空间,然后将要拷贝的数据拷贝到新开辟的空间中

1.4 String类拷贝构造与operator=的传统与现代写法
1.4.1传统写法
class String//传统写法{ public: String(const char* str = "") { // 构造String类对象时,如果传递nullptr指针,可以认为程序非法 if (nullptr == str) { assert(false); return; } _str = new char[strlen(str) + 1]; strcpy(_str, str); } String(const String& s) : _str(new char[strlen(s._str) + 1]) { strcpy(_str, s._str); } String& operator=(const String& s) { if (this != &s) { char* pStr = new char[strlen(s._str) + 1]; strcpy(pStr, s._str); delete[] _str; _str = pStr; } return *this; } ~String() { if (_str) { delete[] _str; _str = nullptr; } }private: char* _str;};传统写法就是按照我们的直观感觉写,拷贝构造我们开辟对应大小的空间然后将数据拷贝过去就行了;赋值重载我们同样开辟对应空间。然后释放旧空间(因为=也支持自己对自己赋值,所以释放旧空间这一步会释放掉对象的空间,因此对于这种情况我们需要处理一下,如果自己给自己赋值,我们不需要做任何处理,直接返回。)
1.4.2现代写法
class String//现代写法{ public: String(const char* str = "") { if (nullptr == str) { assert(false); return; } _str = new char[strlen(str) + 1]; strcpy(_str, str); } String(const String& s) : _str(nullptr) { String strTmp(s._str); swap(_str, strTmp._str); } // 对比下和上面的赋值那个实现比较好? String& operator=(String s) { swap(_str, s._str); return *this; } /* String& operator=(const String& s) { if(this != &s) { String strTmp(s); swap(_str, strTmp._str); } return *this; } */ ~String() { if (_str) { delete[] _str; _str = nullptr; } }private: char* _str;};我们在写拷贝构造传统写法时,我们发现拷贝构造本质上我们可以看做是让新对象管理一块空间,这块空间里面都是拷贝好的值。现代写法以默认构造用String s中数据构造了一个临时对象,然后交换了目标对象与临时对象内部的_str,将tmp管理的空间交给了目标对象。复用了已完成的逻辑。
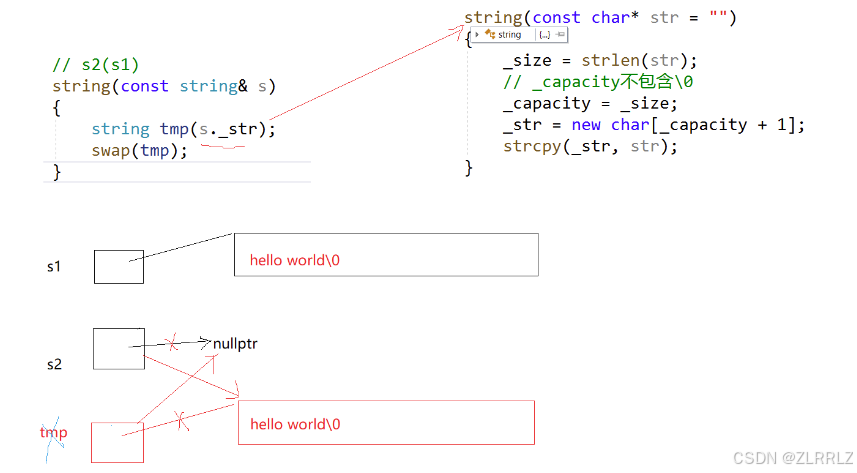
对于赋值重载,我们知道=对于用来赋值的对象不影响,我们只是利用它的数据,并且被赋值的对象的值会被覆盖掉。
现代写法利用传参过程中会自动构造一个临时对象的特点,这个临时对象中有我们所需要的数据,
我们将其与要构造的对象内部的_str交换,这样要构造的string就有了所需要的数据,而就旧空间就交给了临时对象处理,因为临时对象出来函数域会自动调用析构,释放资源,因此我们就不需要再管旧空间了。
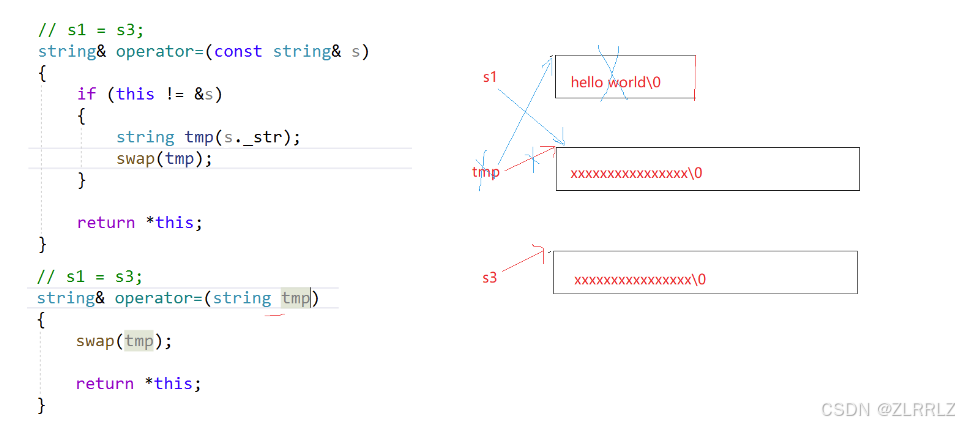
总结:现代写法巧妙的利用了默认构造临时对象,临时对象自动析构的特点,复用了已完成的代码(默认构造),将我们所需要完成的大量工作巧妙地交给编译器完成,提高了效率和资源利用率。
1.5string其他接口
string底层是数组结构,因此实现迭代器结构,我们可以直接封装原生指针实习。
#define _CRT_SECURE_NO_WARNINGS 1#pragma once#include<iostream>#include<string>#include<assert.h>using namespace std;namespace zlr{ class string { public: typedef char* iterator; typedef const char* const_iterator; iterator begin()//封装原生指针实现 { return _str; } iterator end() { return _str + _size; } const_iterator begin() const { return _str; } const_iterator end() const { return _str + _size; } /*string() :_str(new char[1]{ '\0'}) ,_size(0) ,_capacity(0) { }*/ // 短小频繁调用的函数,可以直接定义到类里面,默认是inline string(const char* str = "") { _size = strlen(str); // _capacity不包含\0 _capacity = _size; _str = new char[_capacity + 1]; strcpy(_str, str); } // 深拷贝问题 // s2(s1) /*string(const string& s) { _str = new char[s._capacity + 1]; strcpy(_str, s._str); _size = s._size; _capacity = s._capacity; }*/ void swap(string& s)//交换管理的资源和数据 { std::swap(_str, s._str); std::swap(_size, s._size); std::swap(_capacity, s._capacity); } // s2(s1) // 现代写法 string(const string& s) { string tmp(s._str); swap(tmp); } // s2 = s1 // s1 = s1 /*string& operator=(const string& s) { if (this != &s) { delete[] _str; _str = new char[s._capacity + 1]; strcpy(_str, s._str); _size = s._size; _capacity = s._capacity; } return *this; }*/ // s1 = s3; //string& operator=(const string& s) //{ // if (this != &s) // { // //string tmp(s._str); // string tmp(s); // swap(tmp); // } // return *this; //} // s1 = s3; string& operator=(string tmp) { swap(tmp); return *this; } ~string()//释放资源 { if (_str) { delete[] _str; _str = nullptr; _size = _capacity = 0; } } const char* c_str() const { return _str; } void clear() { _str[0] = '\0'; _size = 0; } size_t size() const { return _size; } size_t capacity() const { return _capacity; } char& operator[](size_t pos) { assert(pos < _size); return _str[pos]; } const char& operator[](size_t pos) const { assert(pos < _size); return _str[pos]; } /*void copy_on_write() { if (count > 1) { 深拷贝 } }*/ void reserve(size_t n); void push_back(char ch); void append(const char* str); string& operator+=(char ch); string& operator+=(const char* str); void insert(size_t pos, char ch); void insert(size_t pos, const char* str); void erase(size_t pos, size_t len = npos); size_t find(char ch, size_t pos = 0); size_t find(const char* str, size_t pos = 0); string substr(size_t pos = 0, size_t len = npos); private: //char _buff[16]; char* _str = nullptr; size_t _size = 0; size_t _capacity = 0; //static const size_t npos = -1; static const size_t npos; /*static const int N = 10; int buff[N];*/ }; bool operator<(const string& s1, const string& s2); bool operator<=(const string& s1, const string& s2); bool operator>(const string& s1, const string& s2); bool operator>=(const string& s1, const string& s2); bool operator==(const string& s1, const string& s2); bool operator!=(const string& s1, const string& s2); ostream& operator<<(ostream& out, const string& s); istream& operator>>(istream& in, string& s);}因为剩下的接口代码较多,我们封装在string类外。
#include"string.h"namespace zlr{ const size_t string::npos = -1; void string::reserve(size_t n) { if (n > _capacity)//判断空间是否足够 { //cout << "reserve:" << n << endl; char* tmp = new char[n + 1]; strcpy(tmp, _str); delete[] _str; _str = tmp; _capacity = n; } } void string::push_back(char ch) { if (_size == _capacity)//判断空间 { reserve(_capacity == 0 ? 4 : _capacity * 2); } _str[_size] = ch;//插入新数据 ++_size; _str[_size] = '\0';//原来的'\0'被覆盖,加上新'\0' } string& string::operator+=(char ch) { push_back(ch);//复用尾插的代码 return *this; } void string::append(const char* str) { size_t len = strlen(str); if (_size + len > _capacity) { // 大于2倍,需要多少开多少,小于2倍按2倍扩 reserve(_size + len > 2 * _capacity ? _size + len : 2 * _capacity); } strcpy(_str + _size, str); _size += len; } string& string::operator+=(const char* str) { append(str); return *this; } void string::insert(size_t pos, char ch) { assert(pos <= _size); if (_size == _capacity) { reserve(_capacity == 0 ? 4 : _capacity * 2); } // 挪动数据 size_t end = _size + 1; while (end > pos) { _str[end] = _str[end - 1]; --end; } _str[pos] = ch; ++_size; } void string::insert(size_t pos, const char* s) { assert(pos <= _size); size_t len = strlen(s); if (_size + len > _capacity) { // 大于2倍,需要多少开多少,小于2倍按2倍扩 reserve(_size + len > 2 * _capacity ? _size + len : 2 * _capacity); } size_t end = _size + len; while (end > pos + len - 1) { _str[end] = _str[end - len]; --end; } for (size_t i = 0; i < len; i++) { _str[pos + i] = s[i]; } _size += len; } void string::erase(size_t pos, size_t len) { assert(pos < _size); if (len >= _size - pos)//如果要删除的长度大于剩下的长度 //就全部删除 { _str[pos] = '\0'; _size = pos; } else { for (size_t i = pos + len; i <= _size; i++) { _str[i - len] = _str[i]; } _size -= len; } } size_t string::find(char ch, size_t pos) { assert(pos < _size); for (size_t i = pos; i < _size; i++) { if (_str[i] == ch) { return i; } } return npos; } size_t string::find(const char* str, size_t pos) { assert(pos < _size); const char* ptr = strstr(_str + pos, str); if (ptr == nullptr) { return npos; } else { return ptr - _str; } } string string::substr(size_t pos, size_t len) { assert(pos < _size); // len大于剩余字符长度,更新一下len if (len > _size - pos) { len = _size - pos; } string sub; sub.reserve(len); for (size_t i = 0; i < len; i++) { sub += _str[pos + i]; } return sub; } bool operator<(const string& s1, const string& s2)//复用库中的比较 { return strcmp(s1.c_str(), s2.c_str()) < 0; } bool operator<=(const string& s1, const string& s2) { return s1 < s2 || s1 == s2;//复用已完成的逻辑 } bool operator>(const string& s1, const string& s2) { return !(s1 <= s2); } bool operator>=(const string& s1, const string& s2) { return !(s1 < s2); } bool operator==(const string& s1, const string& s2) { return strcmp(s1.c_str(), s2.c_str()) == 0; } bool operator!=(const string& s1, const string& s2) { return !(s1 == s2); } ostream& operator<<(ostream& out, const string& s) { for (auto ch : s) { out << ch; } return out; } istream& operator>>(istream& in, string& s) { s.clear();//先清理数据 const int N = 256;//模拟库中的string的buff char buff[N]; int i = 0; char ch; //in >> ch; ch = in.get();//cin提取默认空格作为间隔符,无法提取间隔符 while (ch != ' ' && ch != '\n') { buff[i++] = ch; if (i == N-1) { buff[i] = '\0'; s += buff; i = 0; } //in >> ch; ch = in.get(); } if (i > 0) { buff[i] = '\0'; s += buff; } return in; }}2、 vs和g++下string结构的说明
注意:下述结构是在32位平台下进行验证,32位平台下指针占4个字节。
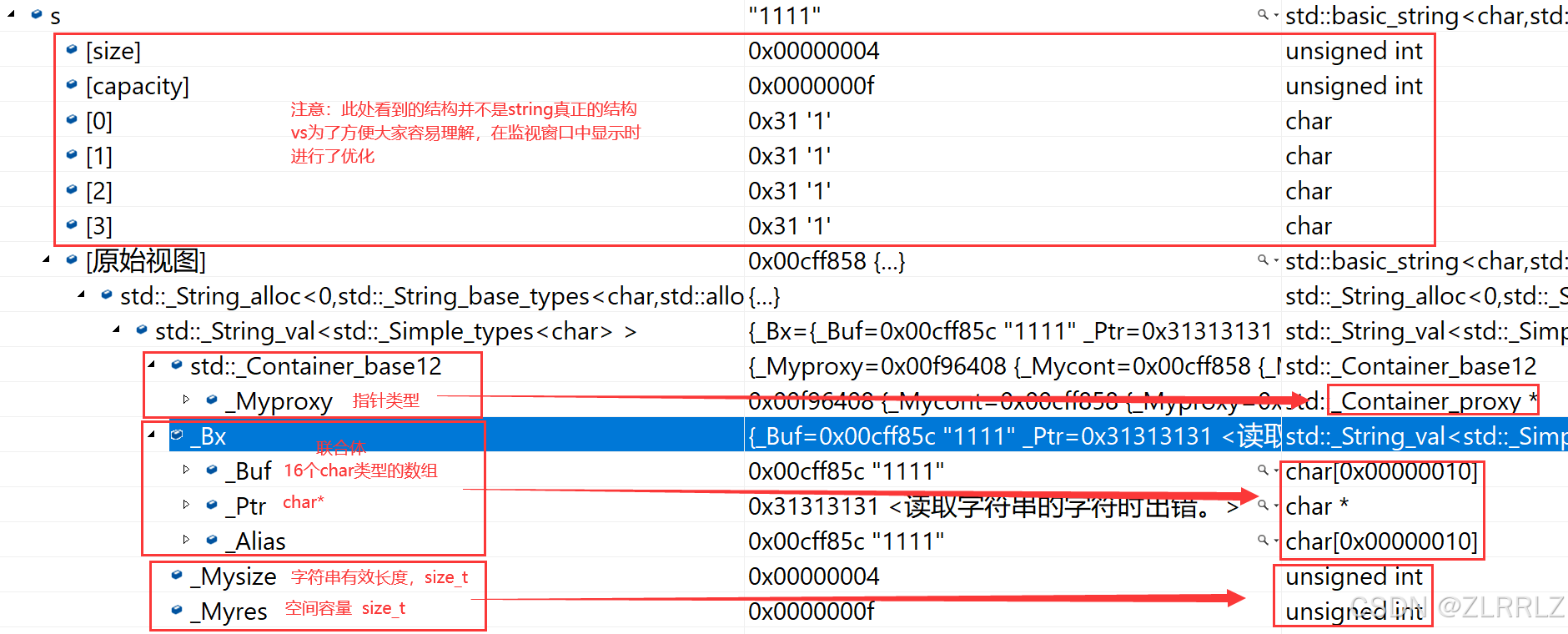
2.1vs下string的结构
string总共占28个字节,内部结构稍微复杂一点,先是有一个联合体,联合体用来定义string中字符串的存储空间:
当字符串长度小于16时,使用内部固定的字符数组来存放
当字符串长度大于等于16时,从堆上开辟空间
union _Bxty{ // storage for small buffer or pointer to larger one value_type _Buf[_BUF_SIZE]; pointer _Ptr; char _Alias[_BUF_SIZE]; // to permit aliasing} _Bx;这种设计也是有一定道理的,大多数情况下字符串的长度都小于16,那string对象创建
好之后,内部已经有了16个字符数组的固定空间,不需要通过堆创建,效率高。可以避免频繁扩容的消耗。
其次:还有一个size_t字段保存字符串长度,一个size_t字段保存从堆上开辟空间总的
容量最后:还有一个指针做一些其他事情。
故总共占16+4+4+4=28个字节。
2.2g++下string的结构
G++下,string是通过写时拷贝实现的,string对象总共占4个字节,内部只包含了一个
指针,该指针将来指向一块堆空间,内部包含了如下字段:
空间总大小
字符串有效长度
引用计数指向堆空间的指针,用来存储字符串。
struct _Rep_base{ size_type _M_length; size_type _M_capacity; _Atomic_word _M_refcount;};3. 写时拷贝(了解)
引用计数:是只用string的资源空间内创建一块空间,来记录使用同一块string对象资源的使用者的个数。
首先什么string对象都不存在的情况下,构造一个string的对象,编译器给string对象内部的引用计数空间+1,表示有一个对象在使用这块空间。
再构造一个string时,编译器使用浅拷贝,编译器不会为该对象分配空间,该对象仍然指向已有的资源空间,将这块资源的引用计数再+1,每增加一个对象,,该对象仍然管理之前同一块资源,,仅仅将引用计数的值增加1,当某个对象被销毁时,先给该计数减1,如果计数不为1,说明还有其他的对象在使用这块资源,我们不需要释放这块资源(计数减1就相当于释放了),如果计数为1,说明该对象时资源的最后一个使用者,将该资源释放。
在这个过程中如果我们对某个对象的数据进行就该,我们就需要先为该对象分配空间资源,然后将数据拷贝到新空间内,引用计数减1.
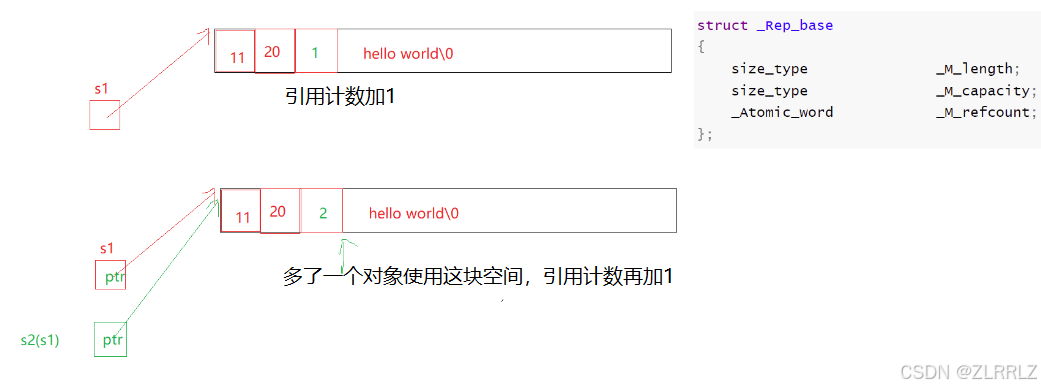
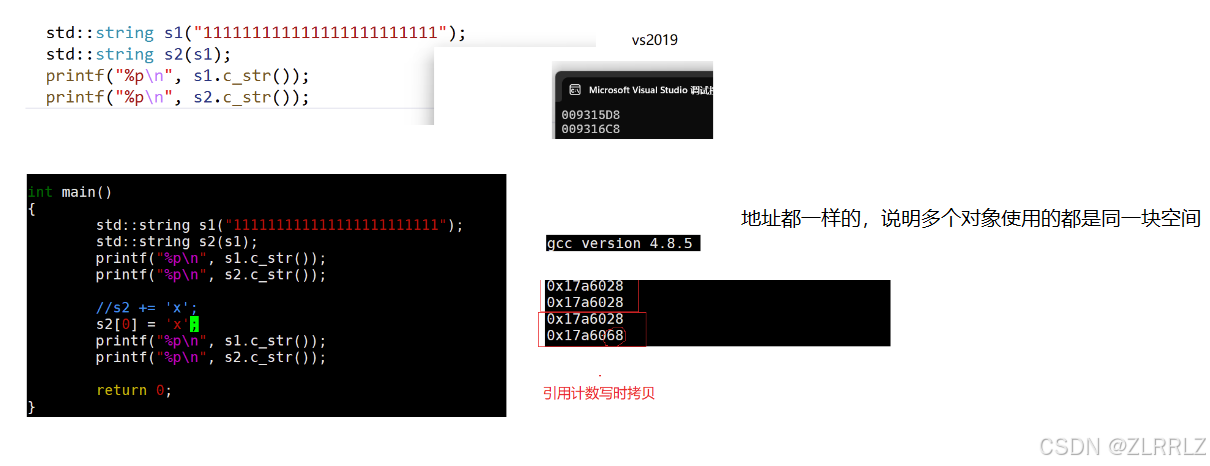

写时拷贝技术是在浅拷贝的基础之上增加了引用计数的方式来实现的。
在之前我们每构造一个对象,我们就为它分配一块空间,但是很多时候我们并不需要对这块空间做什么修改的事情,我们可能仅仅是需要获取数据或者其他比较之类事情,所以很多时候我们创建的对象的空间都可以算作浪费了。
所谓写时拷贝技术就好比就是一种拖延症,只有当程序员需要对某个对象修改数据,才会为该对象分配资源。如果程序员不需要通过某一个对象修改数据,那编译器就不分配空间资源。
总结:写时拷贝技术可以视作一种博弈,如果程序员需要就该就分配空间,不需要就不分配空间。通过这种策略可以节省资源,避免不必要的开销。但是随着C++的不断发展,已经出现新的更好的手段了,所以写时拷贝技术的影响了已经降低了。
写时拷贝
写时拷贝在读取是的缺陷
4. 扩展阅读
面试中string的一种正确写法
STL中的string类怎么了?
Tags:
相关文章
Steam新游《Rootbound》在线:探索危险世界
【C++】string类的模拟实现Brainlag Rootbound是Games开发发行的全新动作冒险游戏,现已在Steam平台上推出。这款游戏暂时不支持中文。Rootbound的背景设定在一个被神秘瘟疫侵蚀的世界里。玩家将扮演一个...
阅读更多
舒华体育“黑科技”产品将落户巴黎奥运会“中国之家”
【C++】string类的模拟实现舒华体育作为中国奥委会官方健身器材供应商和2024年奥运会中国体育代表团官方健身器材供应商,将落户巴黎奥运会“中国之家”,向世界展示中国智能制造商,让世界看到中国品牌实力。据悉,这是舒华第四次入驻奥运...
阅读更多
解锁JavaScript新姿势:Proxy与Reflect深度探秘
【C++】string类的模拟实现引言在 JavaScript 的不断发展中,ES6 引入的 Proxy 和 Reflect 为开发者们带来了全新的编程体验和强大的功能。Proxy 作为一种代理机制,能够对...
阅读更多