kafka安装配置(超详细,傻瓜式安装)
先自我介绍,浙江大学毕业,去过华为、字节跳动等大厂,目前阿里P7。
知道大多数程序员,想要提高技能经常自己摸索成长,但不系统的自学效果低效又长,而且很容易遇到天花板技术停滞不前!
因此,收集整理了《2024年最新大数据全套学习资料》,初衷也很简单我只是希望能帮助那些想自学又不知道从哪里学习的朋友。
零基础资料适合小白学习c;也有适合3年以上经验的小伙伴深入学习提升的高级课程,95%以上的大数据知识点,真正的系统化!
因为有很多文件这里只有一些目录的截图,全套包括大厂面经、学习笔记、源代码讲义、实战项目、大纲路线、讲解视频,而且以后会继续更新。
如果你需要这些信息添加V获取:vip204888 (备注大数据)
正文。
如果你需要这些信息可以添加V获取:vip204888 (备注大数据)正文。
source /etc/proflie。创建data文件夹进入zookeeper。
mkdir data。 进入data。 cd data。
vim myid。写入2。
2。
然后在进入zookeeper的conf下。修改zoo_修改zooo_sample.cfg名称改为zooooooo.cfg。
mv zoo_sample.cfg zoo.cfg。修改zoo.cfg。
vim zoo.cfg。添加。
server.2=bigdata1:2888:388server.3=bigdata2:2888:388server.4=bigdata3:2888:3888。修改。
dataDir=/opt/module/zookeeper-3.5.7/data。分发zookeeper。scp -r /opt/module/zookeeper-3.5.7/ root@bigdata2:/opt/module/。
scp -r /opt/module/zookeeper-3.5.7/ root@bigdata3:/opt/module/。
修改bigdata2和bigdata3中zookeper下data中myid的值分别改为3和4。与下面的对应。
server.2=bigdata1:2888:388server.3=bigdata2:2888:388server.4=bigdata3:2888:3888。
修改名称使环境变量中的名称与module下的名称一致。 在module下:mv apache-zookeeper-3.5.7-bin zookeeper-3.5.7。
mv kafka_2.12-2.4.1 kafka-2.12。
启动zookeeper。
三台都开始了。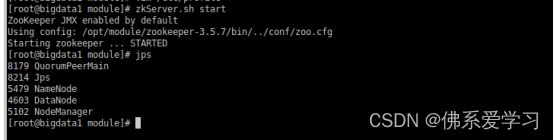
启动后,jps查看过程 QuorumPeerMain。
zkServer.sh start。
配置kafka的环境变量。三台都配。vim /etc/profile。
#kafkaexport KAFKA_HOME=/opt/module/kafka-2.12export PATH=$PATH:$KAFKA_HOME/bin。刷新环境变量。
source /etc/profile。
使用kafka-server-start.sh --version查看kafka的版本。
kafka-server-start.sh --version。
三,使用。在kafkaconfig中修改server.properties文件。
vim /opt/module/kafka-2.12/config/server.properties。
#节点id不同的节点用不同的数字表示。
网上学习资料很多但是,如果所学知识不系统,当你遇到问题时,你只需要尝试#xff0c;#xff00不再深入研究c;所以很难实现真正的技术改进。
需要这个系统数据的朋友,可以添加V获取:vip204888 (备注大数据)
一个人可以走得很快,但是一群人可以走得更远!无论你是从事IT行业的老鸟,还是对IT行业感兴趣的新人,欢迎加入我们的圈子(技术交流、学习资源、职场吐槽、大厂推送、面试辅导),让我们一起学习成长!
研究,所以很难实现真正的技术改进。**。**。
需要这个系统数据的朋友,可以添加V获取:vip204888 (备注大数据)
[外链图片转存中...(img-j1oegpy2-171305093100)。一个人可以走得很快,但是一群人可以走得更远!无论你是从事IT行业的老鸟,还是对IT行业感兴趣的新人,欢迎加入我们的圈子(技术交流、学习资源、职场吐槽、大厂推送、面试辅导),让我们一起学习成长!
Copyright 2022 © 德薄能鲜网 All Rights Reserved