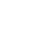这届比赛的题目数量总共有八道,比之前少了两道,而且 Python 组题目的难度比去年下降了不少,同时也是所有组里面难度最低的。不知道是不是为了照顾参赛的选手水平。去年 Python 组的题太难了,我到现在还有好几道不会的题🫢😥。
A:穿越时空之门
考察:字符串、枚举

解题思路
从 1 枚举到 2024,遇到符合条件的数就计数器加一,最后输出计数器即可。
代码
ans = 0def check(x): # 判断是否符合条件 s1, s2 = sum(int(i) for i in bin(x)[2:]), 0 while x: s2 += x % 4 x //= 4 return s1 == s2for i in range(1, 2025): ans += check(i)print(ans) # 63
最后答案为: 63
B:数字串个数
考察:容斥原理、快速幂取余

解题思路
根据条件一:该数字串只能由数字 1 ~ 9 组成。
根据条件二:要减去不包含数字 3 或 7 的。用容斥原理做,集合总大小为:9^10000,减去两个8^10000,由于多减了一个两个都不含的,再加上一个 7^10000。
快速幂取模可以用 Python 的内置函数 pow 实现。
代码
mod = 10**9 + 7# 157509472print((pow(9, 10000, mod) - 2 * pow(8, 10000, mod) + pow(7, 10000, mod)) % mod)
最后答案为:157509472
C:连连看
考察:枚举、哈希表


解题思路
由于要寻找横纵坐标差的绝对值相同的格子对的数量,所以有左上、右上、左下、右下四个方向。
如果使用枚举的方式来统计的话,时间复杂度是 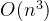 会超时,所以这里可以用一个哈希表来记录从左上到右下,或者从左下到右上方向的同一斜线方向上某个值出现的次数。然后由于同一斜向上每两个值相同,但位置不同的元素都能组成一对,所以用 c[x] 代表这一方向上 x 出现的个数,
会超时,所以这里可以用一个哈希表来记录从左上到右下,或者从左下到右上方向的同一斜线方向上某个值出现的次数。然后由于同一斜向上每两个值相同,但位置不同的元素都能组成一对,所以用 c[x] 代表这一方向上 x 出现的个数,![2C^2_{ c[x]}](https://latex.csdn.net/eq?2C%5E2_%7Bc%5Bx%5D%7D) 就是格子对数。
就是格子对数。
然后再枚举不同斜线方向上的 c 并累加就行。
这里用一个函数来计算左上到右下方向上的,从左下到右上方向上的再把数组每一行逆序一下再计算就行了。
代码
from collections import *n, m = map(int, input().split())a = [list(map(int, input().split())) for _ in range(n)]def acc(a): # 统计从左上到右下方向上的格子对数量 res = 0 for k in range(-(n - 1), m): i, j = -k * (k < 0), k * (k > 0) # 该方向上第一个位置 c = Counter() while i < n and j < m: c[a[i][j]] += 1 i += 1; j += 1 for v in c.values(): res += v * (v - 1) return resprint(acc(a) + acc([a[i][::-1] for i in range(n)]))
测试样例
样例一
输入:
3 21 22 33 2
输出:
6
样例二
输入:
3 33 2 32 3 23 2 3
输出:
20
D:神奇闹钟
考察:时间处理

解题思路
可以使用 Python 标准库中的 datetime 模块来解决此题。
本题中的输入是标准的 iso 格式日期时间,所以可以直接解析为 datetime 对象。
计算上一次响的时间:用总的分钟数减去对时间间隔求余的余数得到上次响的分钟数,再加上起始时间,转化为 datetime 对象,最后输出即可。
代码
from datetime import *bg = datetime.fromisoformat('1970-01-01 00:00:00')for _ in range(int(input())): date, time, dif = input().split() dt = datetime.fromisoformat(date + ' ' + time) nows = int((dt - bg).total_seconds()) // 60 # 分钟数 nows -= nows % int(dif) print(bg + timedelta(minutes=nows))
测试样例
样例一
输入:
22016-09-07 18:24:33 102037-01-05 01:40:43 30
输出:
2016-09-07 18:20:002037-01-05 01:30:00
E:蓝桥村的真相
考察:分类讨论、找规律


解题思路
分别讨论一个村民的断言为假话、真话和后面的村民的断言为假话、真话的情况。再往后的村民的断言真假都可以通过前面的断言真假推断出来。
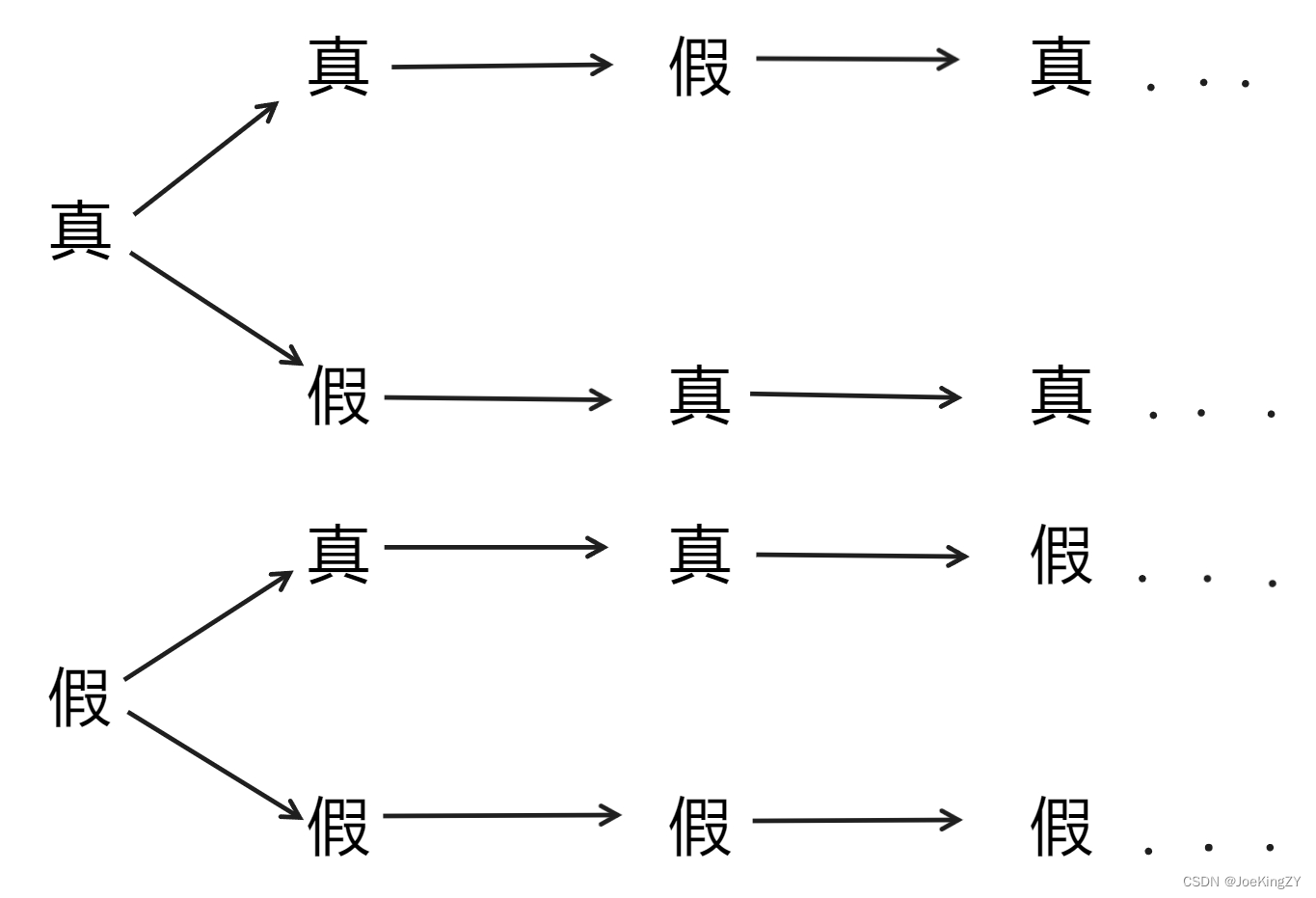
再往后就是之前的重复了。
注意上面前三个分支需要村民个数为 3 的倍数才行,这时“假”的个数为 2n;如果不为 3 的倍数,则只有最后一个情况符合条件,这时“假”的个数为 n。
代码
for _ in range(int(input())): n = int(input()) print(n * (1 + (not n % 3)))
F:魔法巡游
考察:哈希表、DP


解题思路
用两个哈希表 f1、f2 分别统计 s、t 序列中上一个包含 0、2、4 的符石作为序列末尾的最长序列长度。
注意要使用更新前的 f1 来更新 f2 和用更新前的 f2 更新 f1,所以需要对其中一个哈希表拷贝一下。
最后输出两个哈希表中的最大值即可。
代码
cin = lambda: list(map(int, input().split()))input()f1, f2 = [-1] * 5, [-1] * 5digs = (0, 2, 4)def update(s, f1, f2): for d in digs: if str(d) in s: f1[d] = max(f1[d], max(f2[i] + 1 for i in digs if str(i) in s))for s, t in zip(cin(), cin()): s, t = str(s), str(t) f2_ = f2.copy() # 拷贝 update(t, f2, f1) for d in digs: if str(d) in s and f1[d] < 0: f1[d] = max(*f1, 1) # 确保先从 s 开始走 update(s, f1, f2_) print(max(f1 + f2))
测试样例
样例一
输入:
5126 393 581 42 44204 990 240 46 52
输出:
4
样例二
输入:
510 42 44 42 2224 40 52 42 44
输出:
5
G:缴纳过路费
考察:缩点、并查集、DFS


解题思路
分析:由于要满足路径中最贵的一次收费在 [L, R] 区间内,所以收费大于 R 的路径是一定不可以经过的,而对于收费小于 L 的路径可以经过,但是不能让整条路径的收费全部小于 L,要不然路径的最大值也小于 L 了。
对此,我们要:将所有小于 L 的边连接的点缩成一个点(缩点),并记录缩后的点数(就是记录有多少个点缩成了这一个点),大于 R 的边则直接舍弃(不加到图中)。
然后再搜索满足条件的点对的数量,比如:有 3 个点缩成的点 A 和 2 个点缩成的点 B 之间有一条 [L, R] 之间的边,那么就有 2 x 3 = 6 个点对。示意图如下:
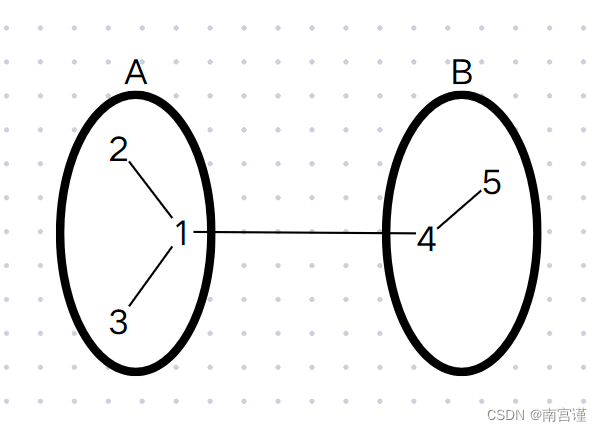
对应的点对分别为:(1, 4)、(1, 5)、(2, 4)、(2, 5)、(3, 4)、(3, 5)。
怎么实现缩点呢?并查集!将所有小于 L 的边连接的点用并查集来合并,让集合的根作为合并后的新点。注意记录集合的大小(也就是新点是由多少旧点合并来的)。
最后使用 DFS 累加点对数量(也可以用再用一个并查集找联通块)。比如点 A 是由 3 个旧点合并而来,与其连通的有 2 个新点,对应 5 个旧点,那么以 A 为第一个坐标的点对就有 3 x (8 - 3) 对。
注意累加的点对有重复((1, 2)、(2, 1) 是同一对),最后要除以二。
代码
from sys import *setrecursionlimit(10**6)cin = lambda: list(map(int, input().split()))n, m, l, r = cin()e = [set() for _ in range(n + 1)]# s[i] == i 表示 i 为新点,sz[i] 表示新点 i 的大小s, sz = list(range(n + 1)), [1] * (n + 1)def find(x): if s[x] == x: return x s[x] = find(s[x]) return s[x]edges = [cin() for _ in range(m)]for u, v, w in edges: if w > r: continue # 舍弃 su, sv = find(u), find(v) if w < l and su - sv: # 边权小于 l 且不在同一集合 # 合并 s[su] = sv sz[sv] += sz[su]# 以新点建图for u, v, w in edges: if l <= w <= r: su, sv = find(u), find(v) e[su].add(sv) e[sv].add(su)vis = [False] * (n + 1)def dfs(u, block): # 寻找连通块,返回值表示该块内点的集合的总大小 block.append(u) res, vis[u] = sz[u], True for v in e[u]: if vis[v]: continue res += dfs(v, block) return resans = 0for i in range(1, n + 1): if s[i] == i and not vis[i]: block = [] t = dfs(i, block) for u in block: ans += sz[u] * (t - sz[u])print(ans // 2)
测试样例
样例一
输入:
5 5 1 21 2 21 3 51 4 12 4 52 5 4
输出:
3
样例二
输入:
10 12 5 81 5 31 2 82 5 52 6 75 7 27 10 98 10 28 9 42 8 73 7 63 8 53 4 10
输出:
30
H:纯职业小组
考察:贪心、思维


解题思路
这道题我的思路比较抽象,大概意思就是找一个数,能恰好组成 k 组(不冗余),且这个数尽可能大。
显然只有当每一组都选完还组不成 k 组的时候输出 -1,否则一定能组成 k 组。
如果能组成 k 组,那么设一个计数器 m = k 表示还缺几组没有凑够。
先在同职业中选 1 ~ 2 个人,这不会增加组数,然后再看剩下的人数是 3 的几倍,如果这个倍数小于 m 的话就都加上。
当遍历完后,这时候 m 仍然小于 k,再加上 m * 3 - 2 就是正确答案。为什么要 -2 呢?因为最后缺的一组再加 1 个人就凑够了。
下面的代码直接用 k 来代替 m 了。
代码
from collections import *cin = lambda: list(map(int, input().split())) for _ in range(int(input())): n, k = cin() cnt = Counter() for i in range(n): a, b = cin() cnt[a] += b if sum(c // 3 for c in cnt.values()) < k: print(-1) continue ans = 0 for a, b in cnt.items(): ans += min(b, 2) # 1 或 2 b -= min(b, 2) # 这行不加,答案也是正确的 if b // 3 < k: ans += b // 3 * 3 k -= b // 3 print(ans + k * 3 - 2)
测试样例
样例一
输入:
23 21 32 33 33 51 32 33 3
输出:
8-1
样例二
输入:
16 601 1002 433 511 322 553 98
输出:
184
最后
今年蓝桥杯省赛的成绩出来了,居然是河北省B组第一名哈哈哈~

可惜的是不知道具体多少分😥
最后祝大家都能蓝桥杯榜上有名,心想事成🤪❤️!!!!
有什么问题欢迎在评论区留言。