
Flink CDC:新一代实时数据集成框架
发布时间:2025-06-24 16:54:50 作者:北方职教升学中心 阅读量:737
摘要:本文从阿里云实时计算团队整理出来 Apache Flink Committer 和 PMC Member 任庆盛老师在 Apache Asia CommunityOverCode 2024中的分享。内容主要分为以下四个部分:
- 什么是 Flink CDC。
- Flink CDC 版本历程。
- Flink CDC 内部实现。
- Flink CDC 社区和未来规划。
一、什么是 Flink CDC。
Flink CDC 数据集成框架,它是基于数据库日志的 CDC(变更数据捕获)该技术实现了统一的增量和全数据读取。结合 Flink 优良的管道能力和丰富的上下游生态系统,Flink CDC 能有效地实现海量数据的实时集成。
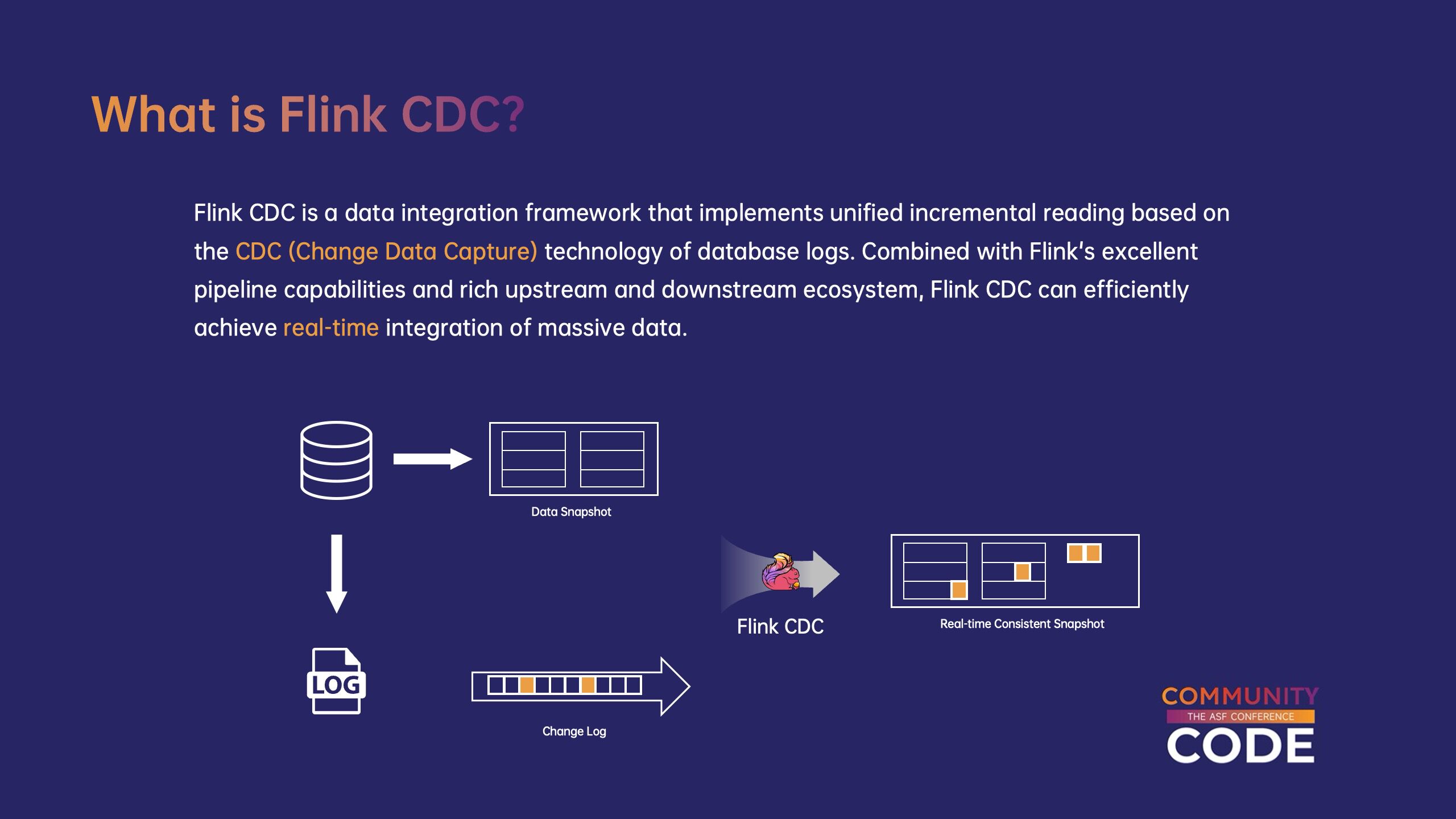
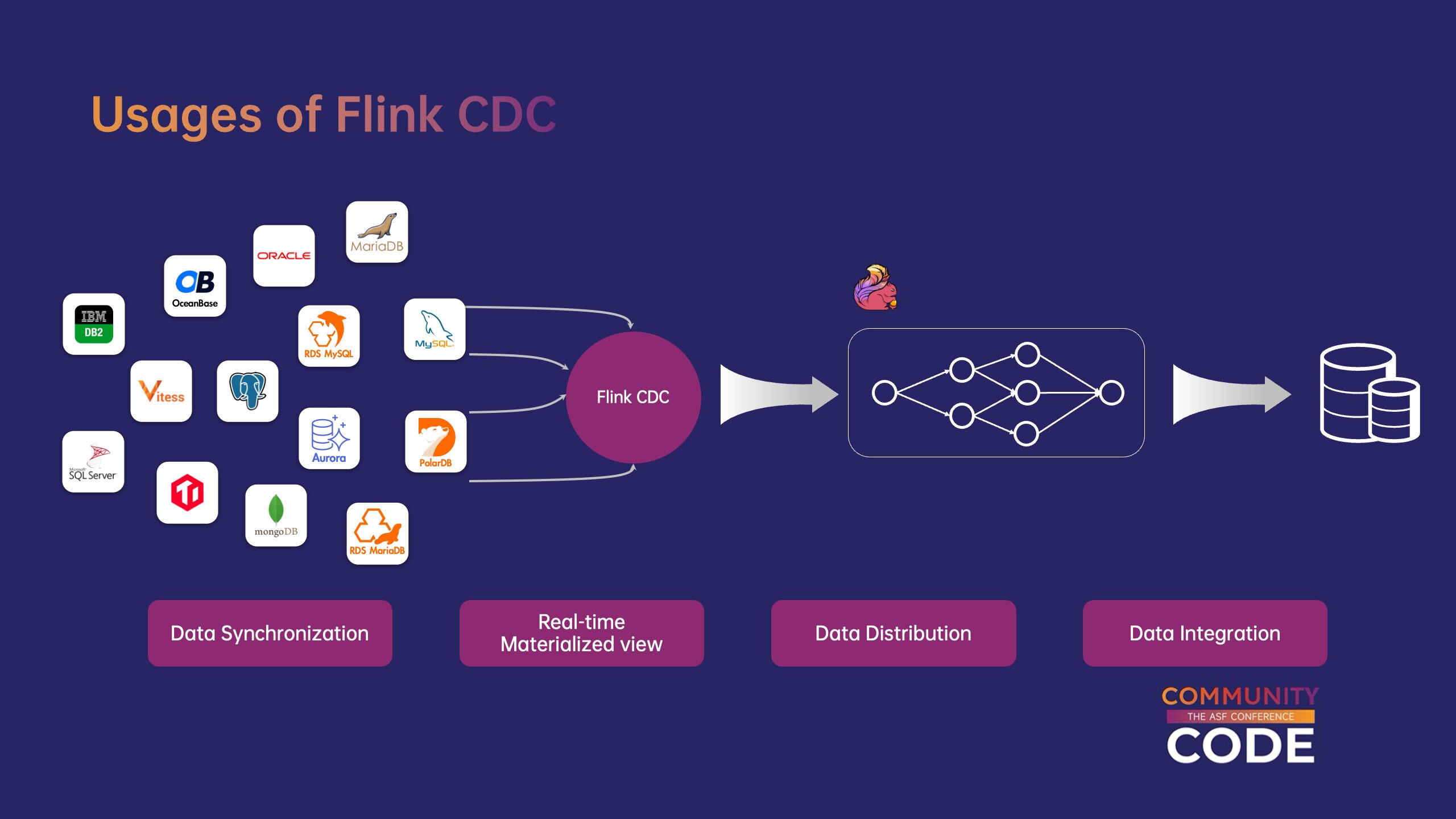
(1)Flink CDC 使用场景。
Flink CDC 可应用于各种场景。例如,数据同步可将上游数据库中的数据同步到下游数据仓库、数据湖等。用户也可以借助 Flink CDC source 实现实时物化视图结合下游 Flink 操作处理逻辑实现了更丰富的业务场景。此外,用户还可以使用 Flink CDC 根据业务逻辑分发数据捕获的变更数据。
作为数据集成框架,Flink CDC 对接上下游数据库、数据湖仓库、消息队列等外部系统非常丰富,如 MySQL、PostgreSQL、Kafka、Paimon 等。
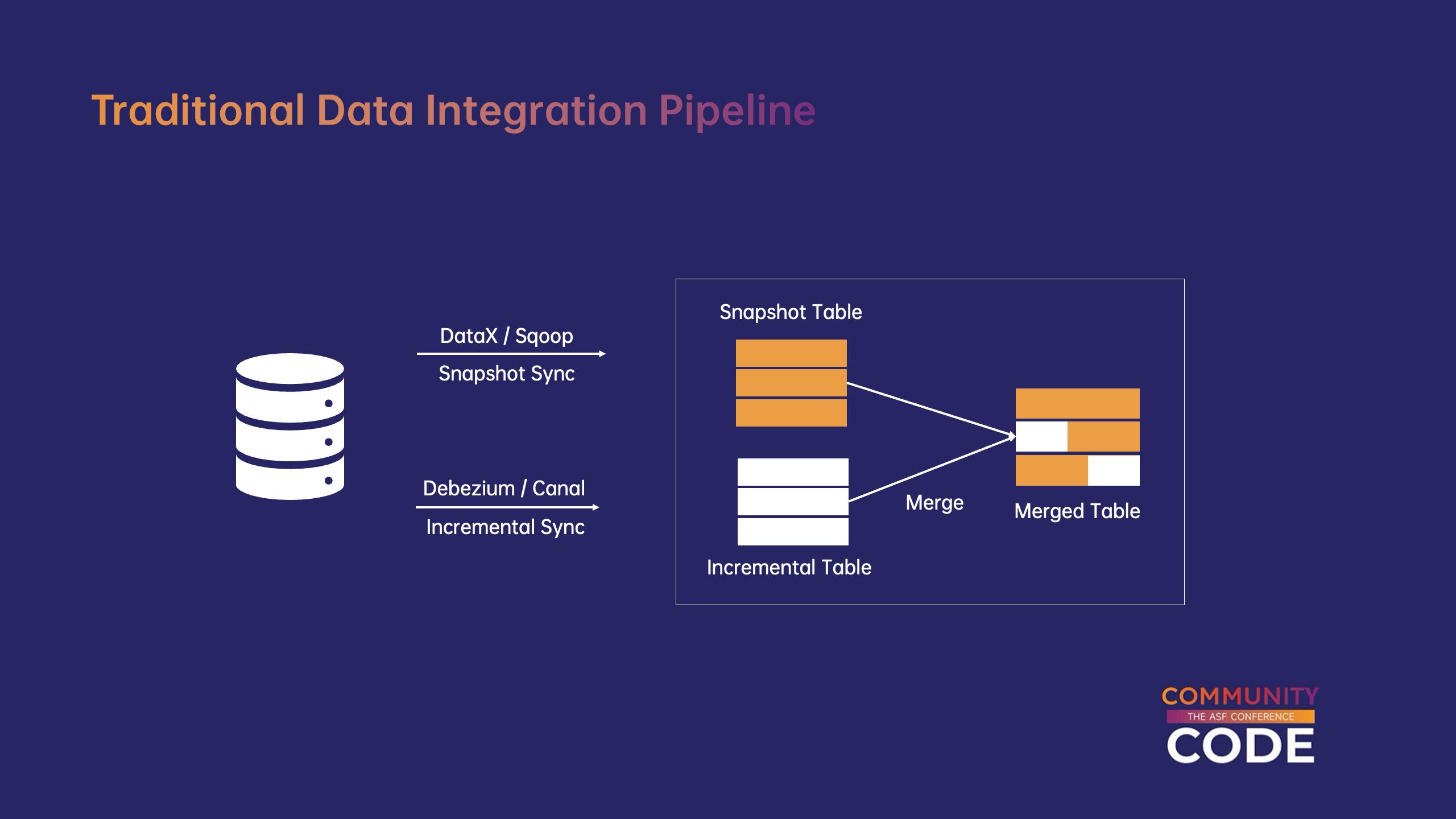
(2)与传统的数据集成流水线相比。
传统的数据集成流水线通常由两个系统组成:全量同步和增量同步。全同步将使用 DataX、Sqoop 等系统,增量同步需要另一套系统,如 Debezium、Canal 等等。全同步完成后,合并增量表和全量表可能需要额外的一步来合并,最终获得与上游一致的快照。这种架构的组件组成比较复杂,它给系统维护带来了许多困难。
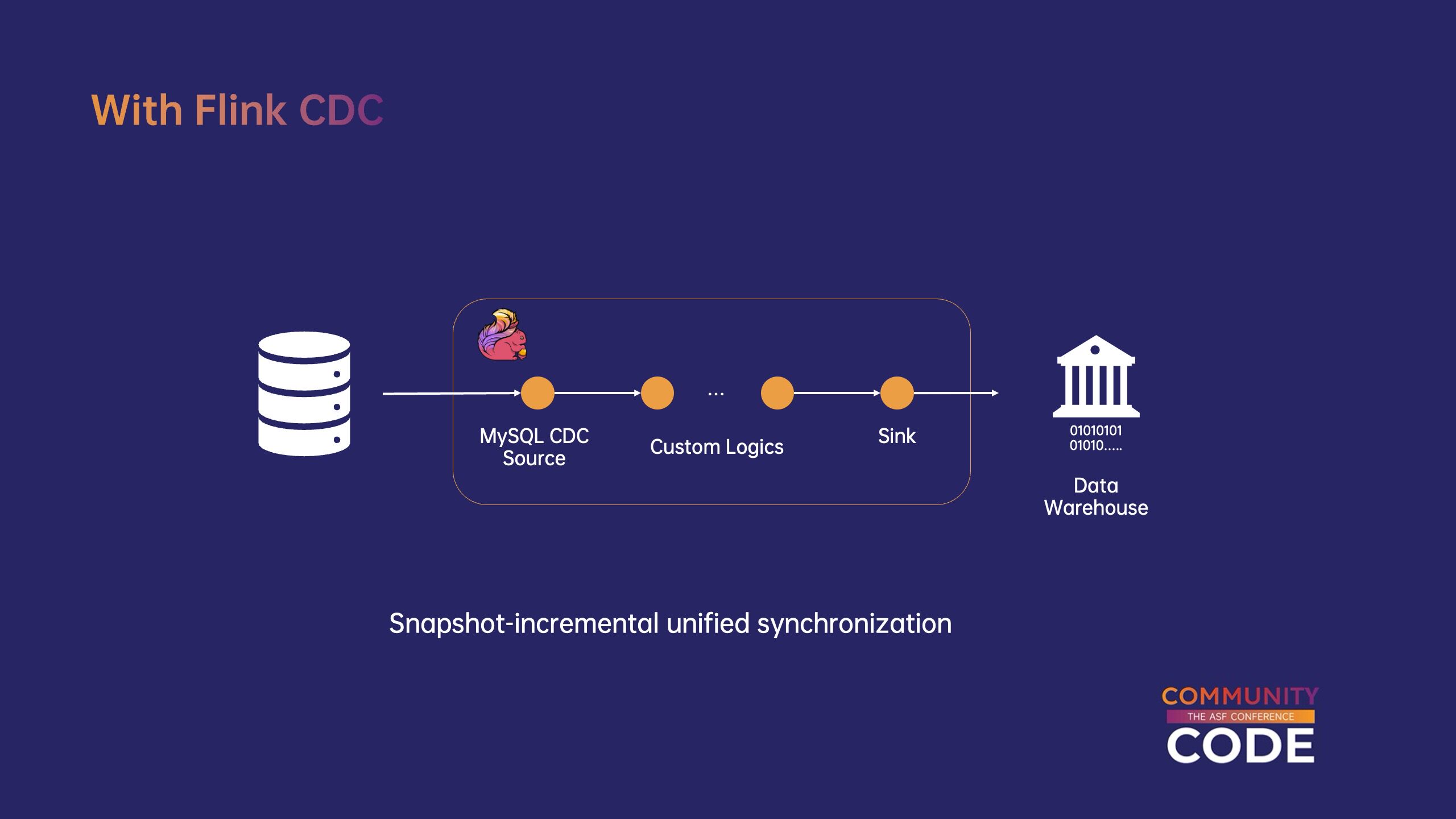
与传统数据集成流水线相比,xff0c;Flink CDC 提供全量与增量一体化同步的解决方案,同步任务,只需使用一个 Flink 操作可以将上游的全数据与增量数据同步到下游系统。此外 Flink CDC 使用增量快照算法,实现全量和增量数据的无缝切换,无需任何额外配置。
二、Flink CDC 版本历程。
Flink CDC 诞生于 2020 年 7 月,中间经过不断迭代优化多个大版本已经发布。2021 年 8 月,Flink CDC 发布了 2.0 版本,首次为 MySQL CDC source 引入增量快照算法,实现全增量同步无缝切换。2022 年 11 月,Flink CDC 发布 2.3 版本,将大多数 connector 对接到增量快照框架。2023 年 12 月,Flink CDC 推出 3.0 版本,正式将 Flink CDC 项目升级为实时数据集成框架,提供 YAML API,端到端解决方案同步提供数据。

三、Flink CDC 内部实现。
(1)Flink CDC YAML。
在 Flink CDC 2.x 时代,Flink CDC 只提供一些 Flink source,用户仍然需要自己开发 Flink DataStream 或 SQL 操作实现数据同步逻辑。如果用户对 Flink 不熟悉�数据正确性和乱序问题经常遇到困难。此外 Flink CDC 2.x 不支持 schema 变更,而 schema 在用户的业务系统中,变更是一个非常常见和重要的场景。通过对用户使用场景的研究,我们发现绝大多数使用它 Flink CDC 作业是相对简单的数据 ETL。结合上述问题我们决定为用户提供一个新的框架,全新的设计 API,专注于数据同步场景。

(2)Flink CDC 整体设计。
Flink CDC 基于 Flink runtime 实现,因此,可以充分重用 Flink 在不同环境下部署资源管理和能力。各种数据集成场景,Flink CDC 多种自定义算子深度定制c;如 schema operator、router、transformer 等。协调和组合不同的算子,Flink CDC 引入了 composer 组件,可以根据用户定义的数据同步逻辑构建 Flink 作业。依托于 Flink 丰富的生态系统,开发人员只需简单包装即可快速包装现有开发人员 Flink connector 对接至 Flink CDC。此外 Flink 还提供了 CLI,只需一个脚本就可以使用用户 YAML 定义使用 composer 构建成 Flink 作业,并向指定提交 Flink 集群。基于上述架构�Flink CDC 为数据集成用户提供服务 schema 增强变更同步、整库同步、分库分表同步等能力。
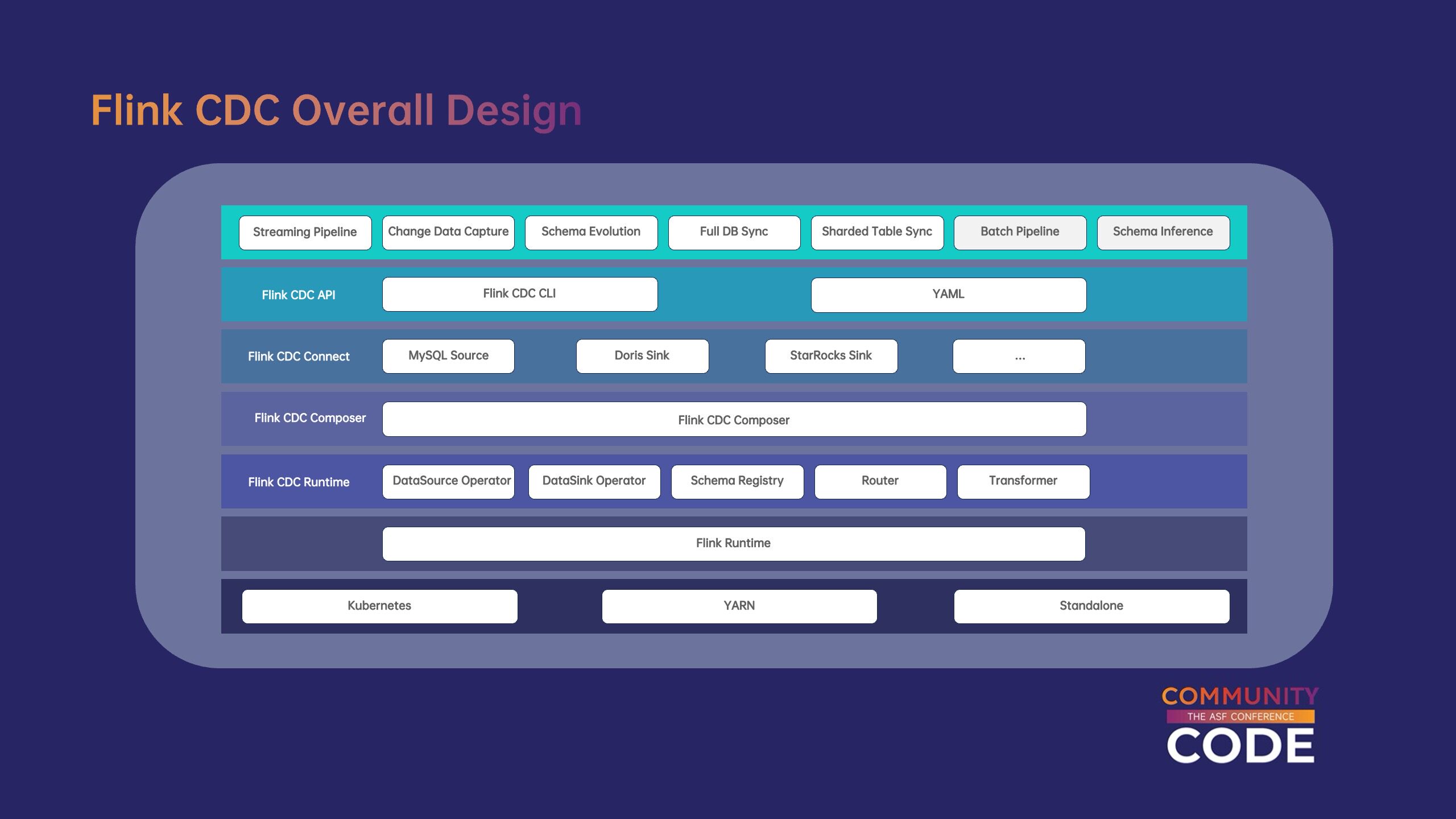
(3)Flink CDC API。
Flink CDC API 使用 YAML 语法定义数据同步任务,开发人员很容易手动开发,也可以有效地使用机器进行处理。YAML API 为数据集成场景设计,用户只需定义同步数据源和数据目标端即可快速构建实时同步流水线。此外,用户也可以在那里 YAML 中定义 routing 和 transformation 实现自定义数据的分发和变换。用户不再需要熟练掌握 Flink 操作开发和内部实现即可使用 Flink CDC 构建实时数据集成流水线。

Flink CDC 提供的 CLI(flink-cdc.sh)进一步简化了用户提交 Flink CDC 任务流程。用户只需执行一行命令,CDC composer 会将 source、sink、自定义 CDC runtime 构建成 Flink 任务,创建 Flink JobGraph 后提交至 Flink 集群。

(4)Flink CDC Pipeline 连接器。
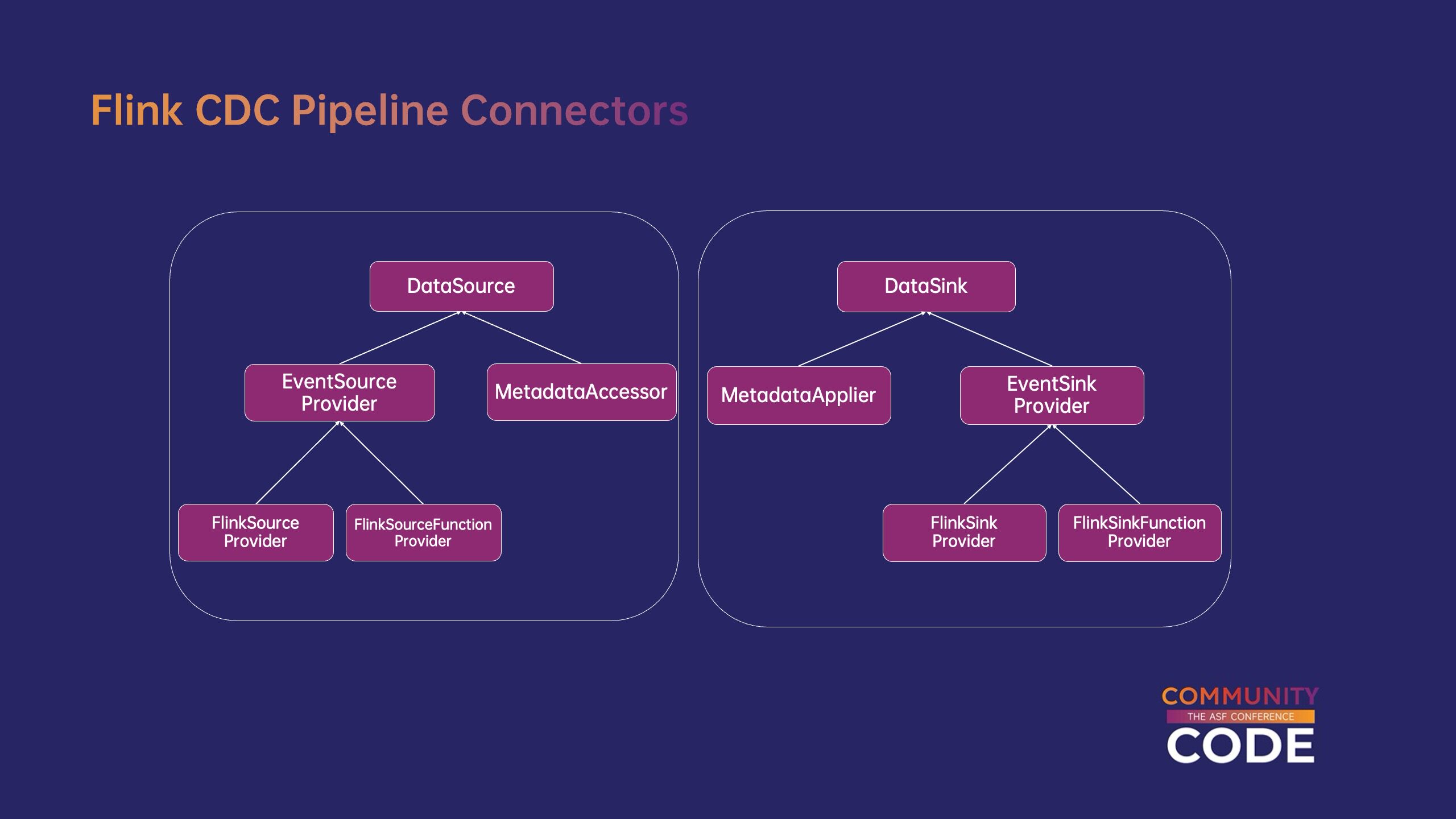
Flink CDC 定义自己的数据源和目标端连接器的接口,以适配 Flink CDC 内部数据结构。Flink CDC pipeline connector 基于 Flink connector,简单的数据转换包装,现有的可以快速复用 Flink connector,将其对接到 Flink CDC 在生态系统中。为了实现 schema 变更处理能力Flink CDC 定义了 MetadataAccessor 和 MetadataApplier,分别对源端和目标端 schema 获取和处理等元信息,实现 schema 实时同步变更。
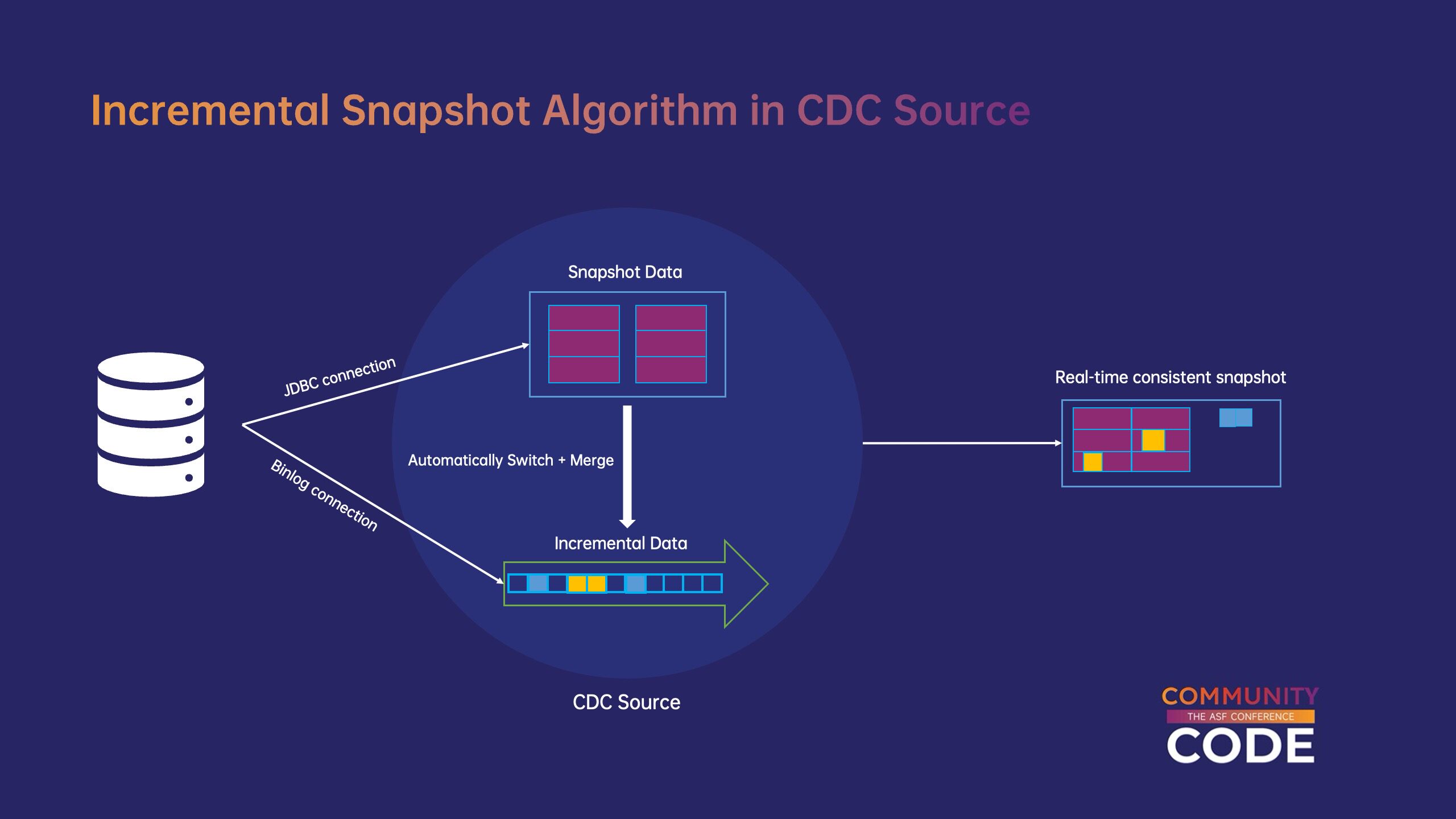
(5)Flink CDC Source 增量快照算法。
为实现全量与增量的一体化同步,Flink CDC source 使用增量快照算法,无缝切换既实现了全增量同步c;而且采用了无锁设计,避免锁表动作对上游业务的全同步影响。在增量快照算法中,数据库的全数据分为独立数据块(chunk),分发给 source 并发读取每一个。考虑到数据在完全读取过程中可能会发生变化,在开始阅读之前,source 将 binlog 目前的位置是低水位线(low watermark),完全阅读后再次阅读 binlog 最新位置记录为高水位线(high watermark),然后读取高低水位线之间的变化数据,将其合并到已读取的全数据块中,构建与上游完全一致的数据块。阅读完所有数据块后,source 切换位点将根据记录的高水位线确定c;实现全量和增量的无缝切换。
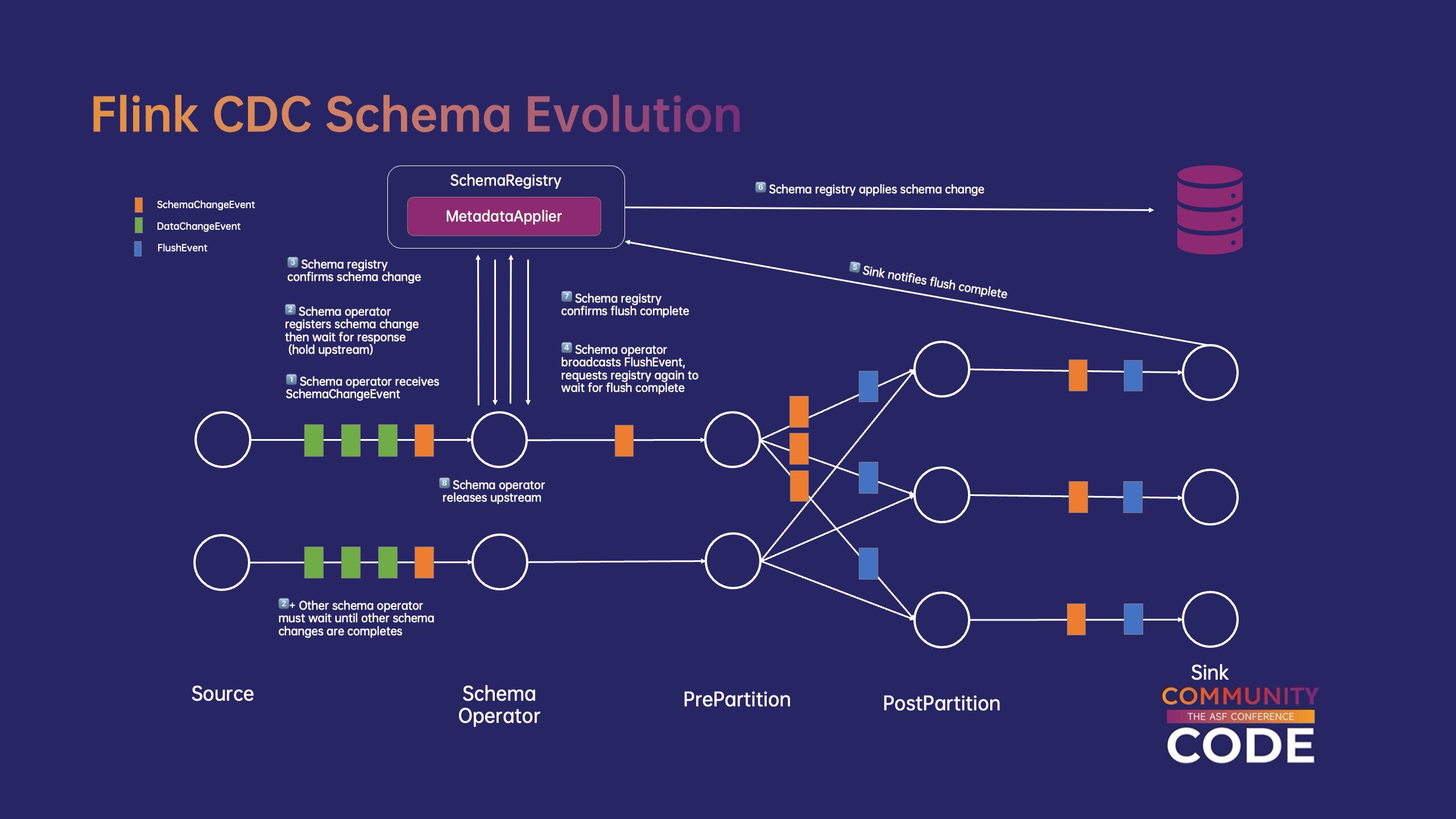
(6)Flink CDC 对 Schema 支持变更。
Flink CDC 通过定制 schema operator 以及 schema registry 协调,实现对上游 schema 实时同步变更。当 schema operator 感知上游的发生 schema 变更后,将同步发送变更信息 schema registry,并暂停数据流的处理。schema registry 首先插入 Flush 所有下游数据将从事件开始 sink 推出,在收到全部 sink 确认后,通过 MetadataApplier 将 schema 变更应用于下游系统,在完成 schema 变更后,schema registry 通知 schema operator,恢复数据流处理,完成整个 schema 变更过程。

(7)Flink CDC 支持数据分发处理。
Flink CDC 定制了 router 算子,实现变更数据的分发与合并。用户可以在 YAML 中使用 route 修改更改数据的目标数据库和表名,将数据同步到指定的目标端�还可以指定多对一路由规则,将多个表合并为目标端的一个表。


(8)Flink CDC 支持数据变换。
通过在 YAML 中使用 transform 字段,用户可以定义投影、过滤、增加元信息列等数据转换操作c;调整数据内容后,同步到下游。transform 使用类 SQL 语法,用户可以简单地开发,它还保留了支持更多类型变换的可扩展性。

(9)Flink CDC 数据结构。
Flink CDC 定义数据和数据流 schema 信息协议:
数据流以 CreateTableEvent 开始描述开始 schema。
后续所有的 DataChangeEvent 需要遵循它的前面 schema。
当 schema 发生变化时需要在数据流中发送新的信息 SchemaChangeEvent 以描述 schema 变化。
这种设计的优点是实现了数据和 schema 分离,大大降低了数据的序列化成本。此外 Flink CDC 压缩二进制格式用于数据变更事件c;性能进一步提高。

四、Flink CDC 社区和未来规划。
目前 Flink CDC 已经有超过 160 位置贡献者,项目获得 5k+ star,1000+ commit。未来 Flink CDC 扩展生态,对接到更多的外部系统,如 PostgreSQL、Iceberg 等,并且会支持更多 schema 变更类型和数据类型。另外 Flink CDC 也将继续提高生产稳定性,包括定制异常处理方法的配置,提高测试覆盖率等。作为 Apache Flink 子项目,Flink CDC 使用与 Flink 一致的贡献过程。欢迎用户和贡献者 Flink 咨询和讨论电子邮件列表中的#xff0c;使用 Apache JIRA 创建 issue,在 GitHub 上提交 PR!


欢迎大家多加关注 Flink CDC,从钉钉用户交流群[1]、微信微信官方账号[2]、Slack 频道[3]、加入邮件列表[4] CDC xff000用户社区c;以及在 Flink CDC GitHub 参与仓库[5]代码贡献#xff01;
[1] “ Flink CDC 社区 ② 钉钉群号:80655011780。

[2] ” Flink CDC 微信官方账号“微信号:ApacheFlinkCDC。
[3] https://flink.apache.org/what-is-flink/community/#slack。
[4] https://flink.apache.org/what-is-flink/community/#mailing-lists。
[5] https://github.com/apache/flink-cdc。
