目录。
1.准备工作:
1.确保jdk已安装在当前的操作系统中。
2..准备hadoop安装包。
3.开始安装:
1.修改当前主机的主机名称:
2.安装hadop。
3.配置hadop。
4. 进入hadoop配置文件的路径:
4.启动hadop平台。
1.格式化主服务器。
2.启动hadop平台。
3.检查所有过程是否成功启动。
5.报错解决方案。
1.准备工作:
1.确保jdk已安装在当前的操作系统中。

2..准备hadoop安装包。

hadoop-2.7.7.tar.gz。
3.开始安装:
1.修改当前主机的主机名称:
- 打开/etc/hostname 文件。
[root@localhost etc]# vi /etc/hostname。

- 然后删除原始内容,设置新的主机名称。
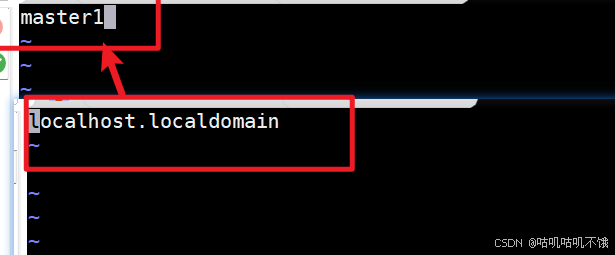
注意:主机名不允许使用一些特殊符号:- _ . *。
- 打开/etc/hosts 文件,然后修改里面的映射关系。
[root@localhost etc]# vi /etc/hosts。
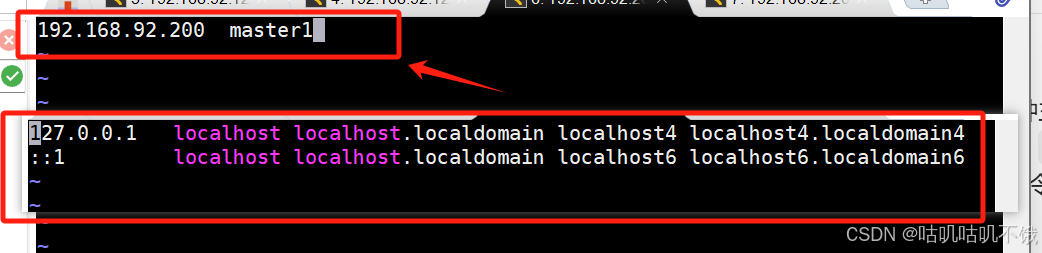
- 删除原始内容,并输入新的映射关系。
虚拟机IP地址 主机名。
例如:192.168.74.129 master1。
重启虚拟机:reboot。
2.安装hadop。
- 将hadoop的安装包解压到 指定路径a;以bigdata为例。
[root@master1 ~]# tar -zxvf hadoop-2.7.7.tar.gz -C bigdata/。
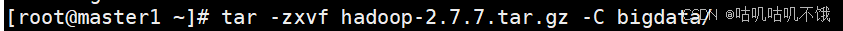
- 配置环境变量。
打开~/.bashrc。
[root@master1 ~]# vi ~/.bashrc。
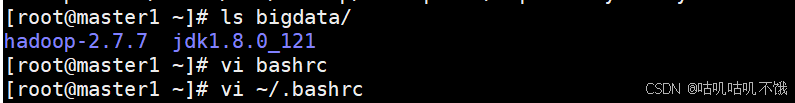
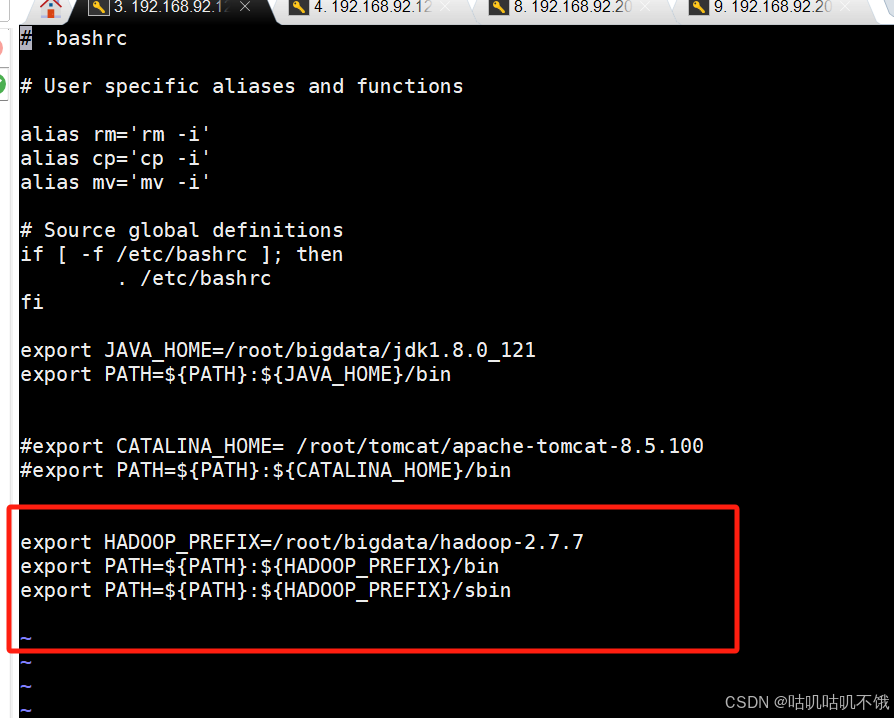
- 然后在文件末尾添加以下内容。
#配置hadop的环境。
export HADOOP_PREFIX=/root/bigdata/hadoop-2.7.7 <-- 这里是hadoop的地址-->
export PATH=${ PATH}:${ HADOOP_PREFIX}/bin。
export PATH=${ PATH}:${ HADOOP_PREFIX}/sbin。
- 配置文件的设置生效。
[root@master1 ~]# source ~/.bashrc。
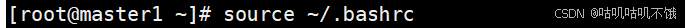
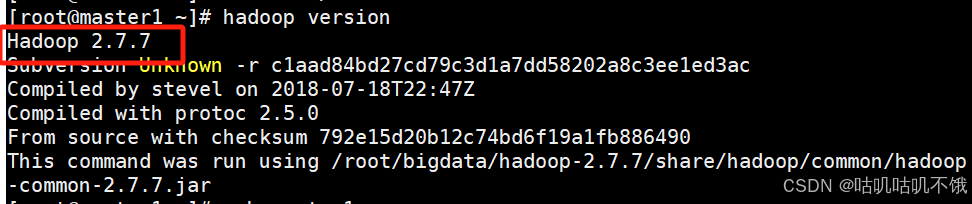
- 检查配置是否成功。
[root@master1 ~]# hadoop version。
Hadoop 2.7.7。
3.配置hadop。
- 免密登录在配置服务器之间。
。测试是否有免密功能。
如果输入:ssh 主机名 如果需要输入密码,则表示没有免密功能,需要设置。
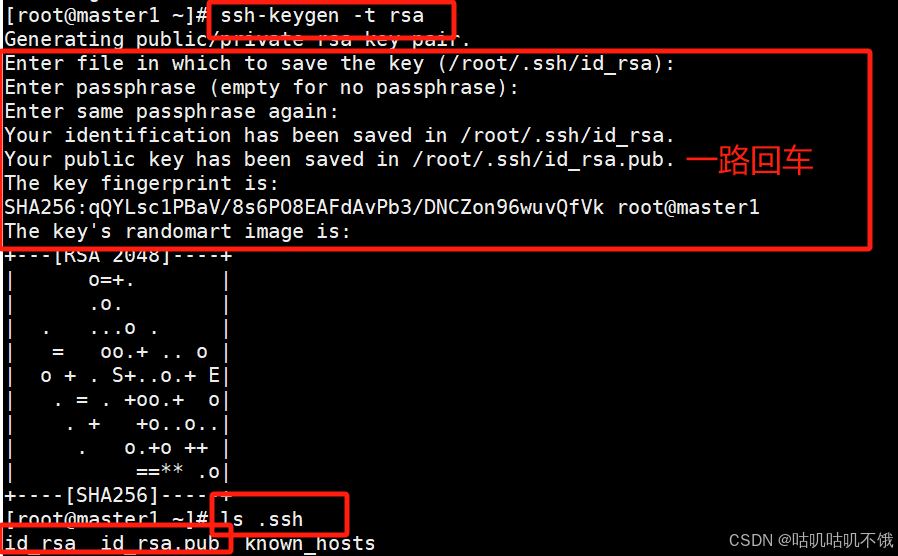
设置免密登录。
[root@master1 ~]# ssh-keygen -t rsa 用于生成当前服务器访问的密钥和公钥。
注意:上述命令执行后,一路返回车辆 然后将生成两个文件:id_rsa id_rsa.pub。
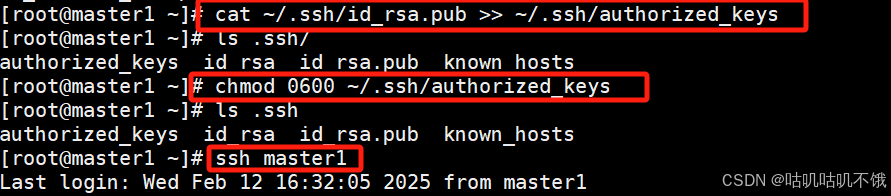
[root@master1 ~]# cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys 在目标服务器中保存生成的公钥。
[root@master1 ~]# chmod 0600 ~/.ssh/authorized_keys 设置权限。
测试配置是否成功。
ssh 主机名。
如果不需要输入密码,则表示无密设置成功。
- 修改hadoop配置文件。
hadoop配置文件的路径: ../hadoop-2.7.7/etc/hadoop/。
4. 进入hadoop配置文件的路径:
[root@master1 hadoop]# cd /root/bigdata/hadoop-2.7.7/etc/hadoop/。

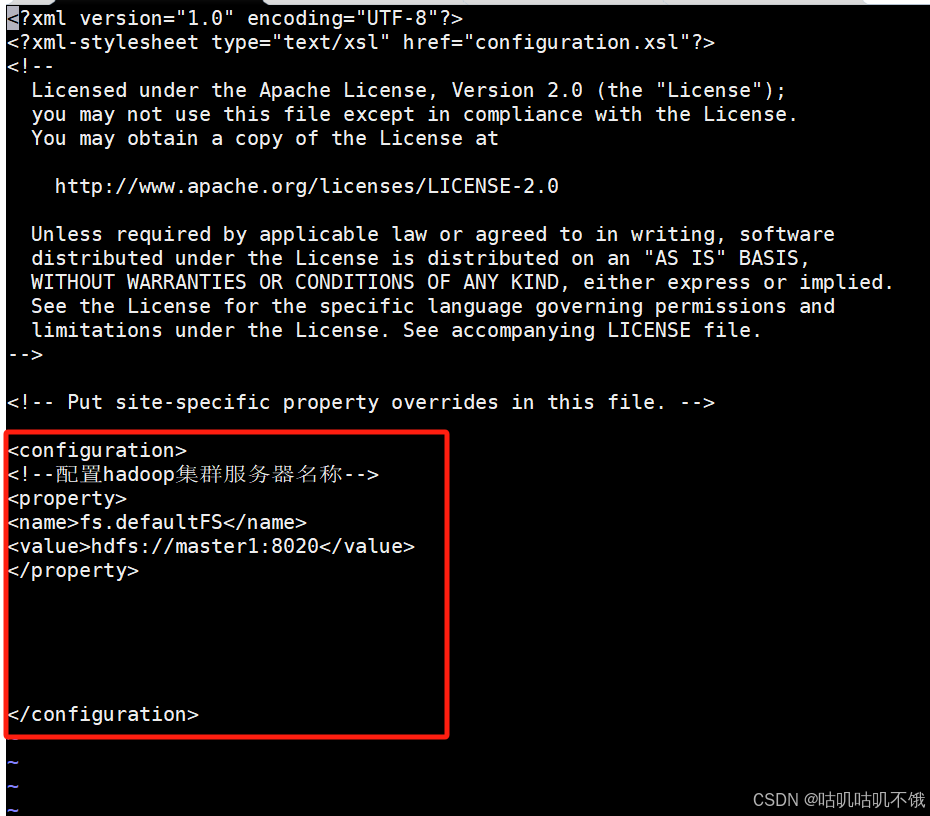
#xff1修改核心配置文件a;core-site.xml。

打开配置文件:[root@master1 hadoop]# vi core-site.xml。
<!--配置hadoop集群服务器名称 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs:///自己的主机名:8020</value>
</property>
- 修改hdfs配置文件:hdfs-site.xml。
[root@master1 hadoop]# vi hdfs-site.xml。
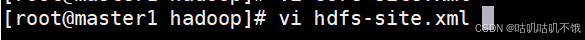
在标签中添加以下内容:
注意:以下路径应以自己的实际路径为主。
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/root/bigdata/hadoop-2.7.7/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/root/bigdata/hadoop-2.7.7/dfs/data</value>
</property>
- 修改mapreduce配置文件:mapred-site.xml.template。
配置文件mapred-site.xml.复制template的当前路径,重命名为:mapred-site.xml。
配置文件mapred-site.xml.复制template的当前路径,重命名:mapred-site.xml。
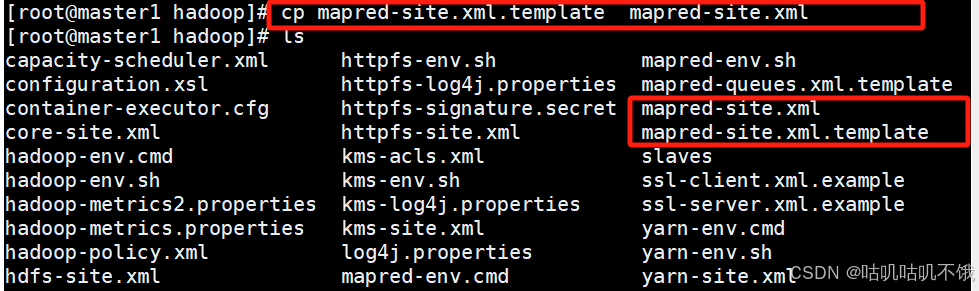
[root@master1 hadoop]# cp mapred-site.xml.template mapred-site.xml。
[root@master1 hadoop]# vi mapred-site.xml。
在标签中添加以下内容:
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
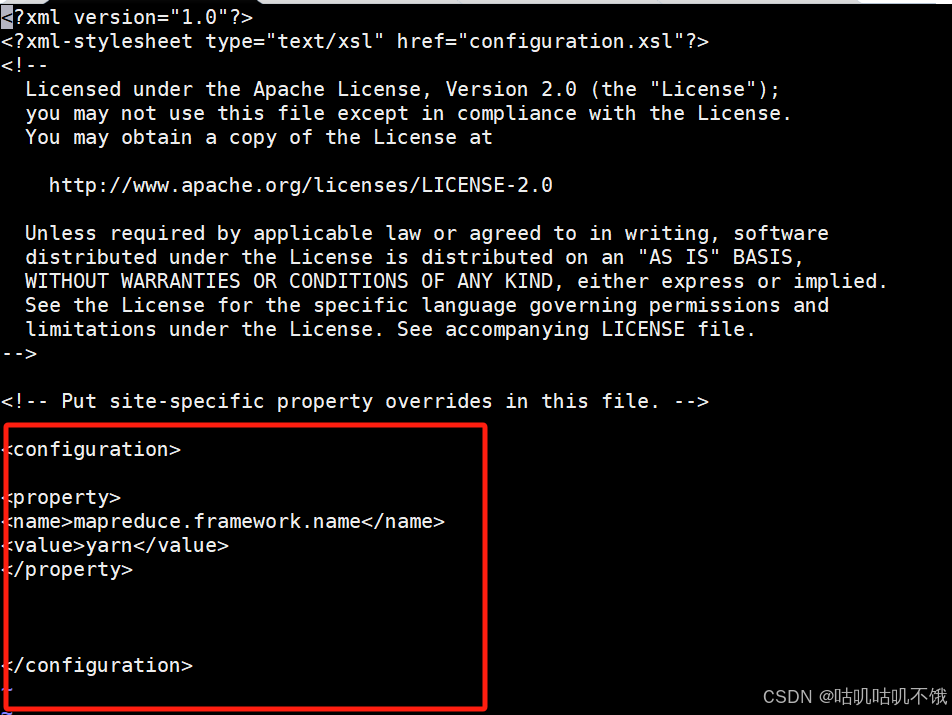
- </property>
修改yarn资源管理器配置文件:yarn-site.xml。
[root@master1 hadoop]# vi yarn-site.xml。
在标签中添加以下内容:
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>主机名:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>主机名:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>主机名:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>主机名:8033</value>
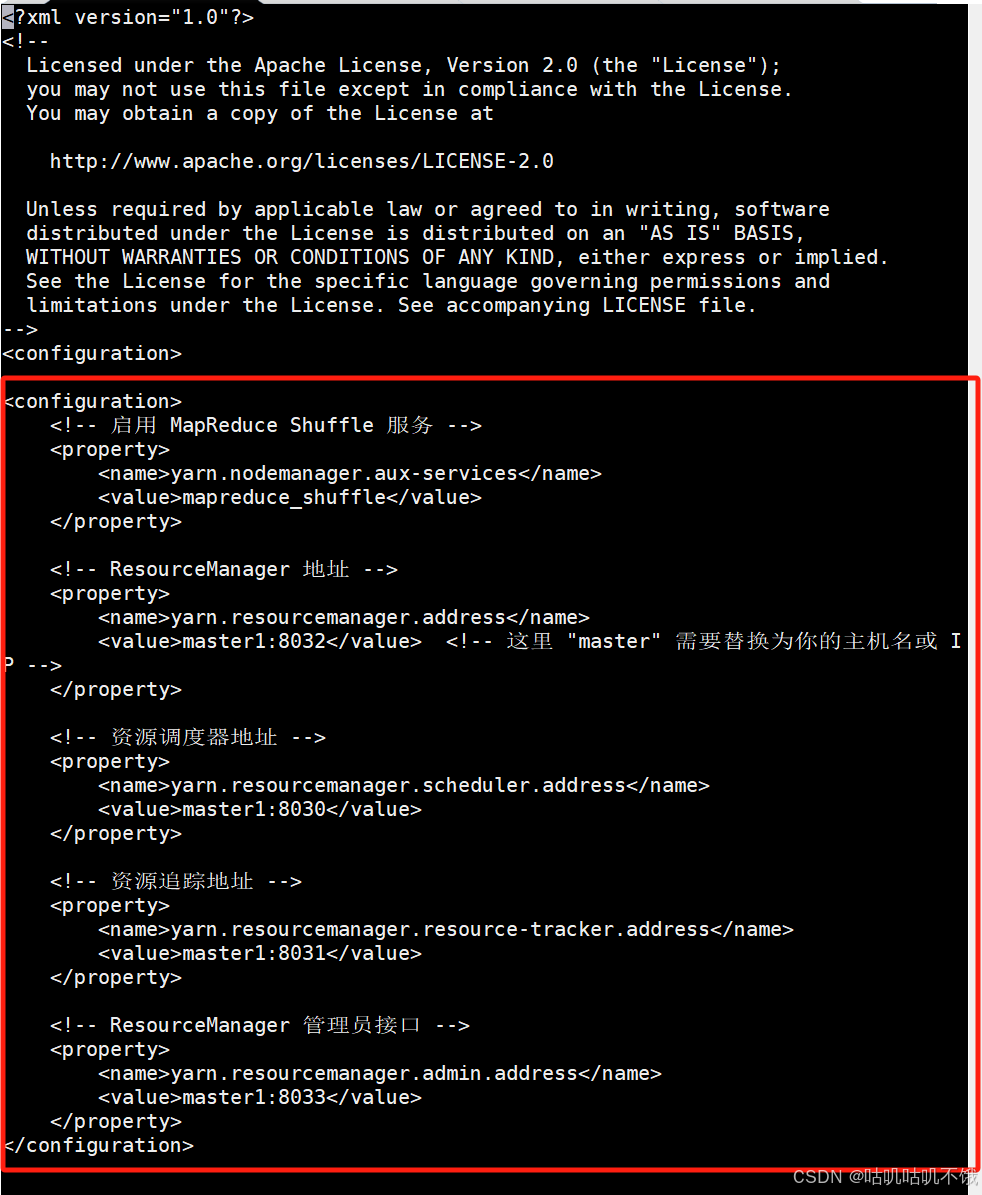
- </property>
修改配置文件,设置子服务器主机姓名:slaves。
[root@master1 hadoop]# vi slaves。
- [root@master1 hadoop]# vi slaves。
删除内容,设置当前服务器的主机名。
修改jdk路径:hadoop-env.sh。

[root@master1 hadoop]# vi hadoop-env.sh。
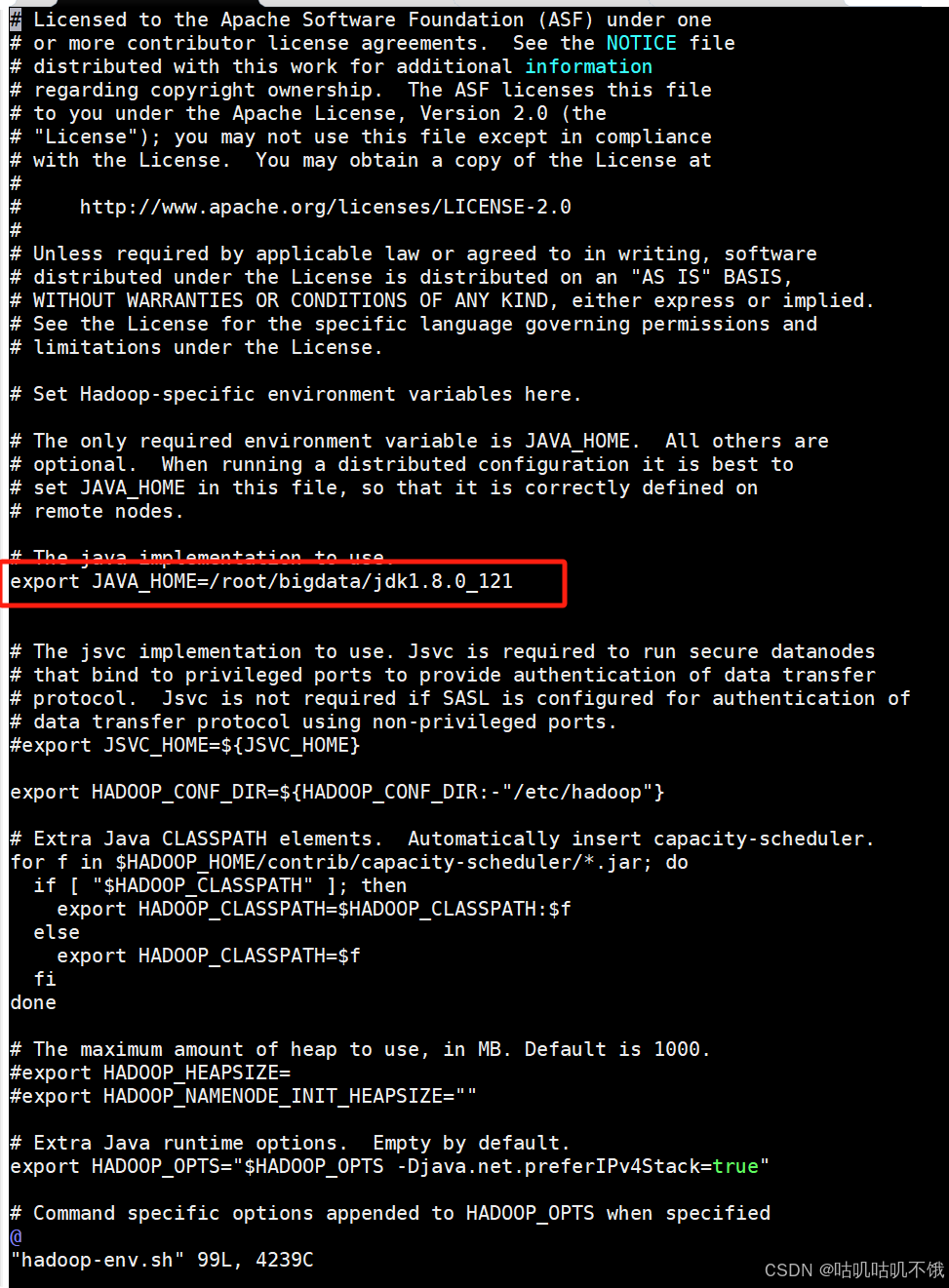
export JAVA_HOME=JDK安装路径。
4.启动hadop平台。
1.格式化主服务器。
(一般只格式化一次)
[root@master1 hadoop]# hadoop namenode -format。
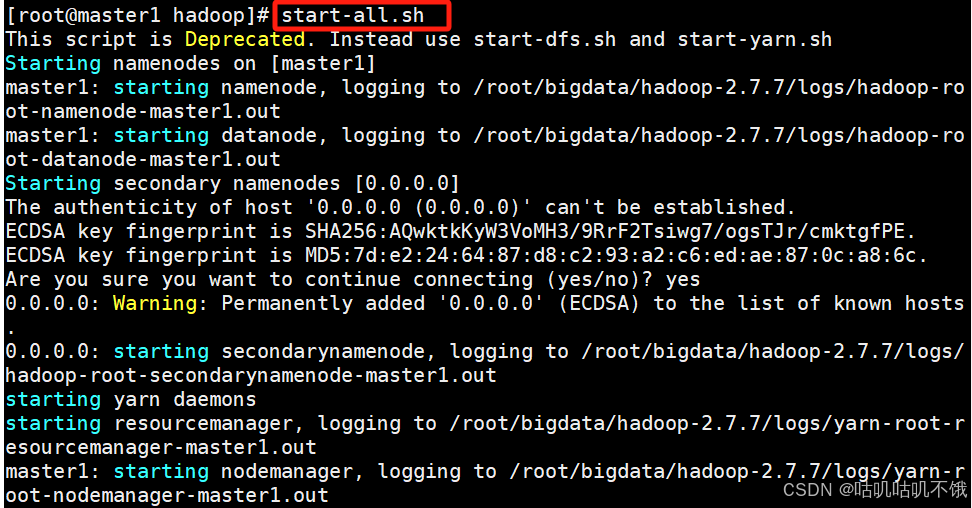
2.启动hadop平台。
[root@master1 hadoop]# start-all.sh。
3.检查所有过程是否成功启动。
[root@master1 hadoop]# jps。
至少要有以下六个结果。
2500 Jps。
1974 SecondaryNameNode。
2119 ResourceManager。
1705 NameNode。
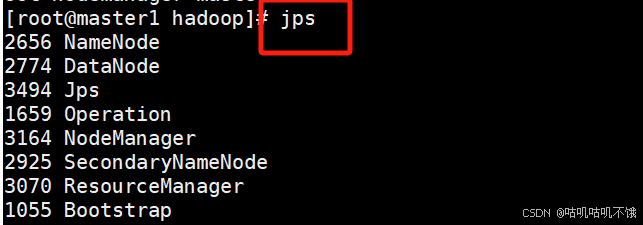
2238 NodeManager。
- 1823 DataNode。
- 5.报错解决。
4.重新启动。start-all.sh。 顶: 13748踩: 47注意:如果格式化时报错,由于配置文件出现问题,概率很大c;配置文件需要仔细检查。
如果格式化没有问题也就是说,配置文件没有文件但是开始时缺少过程。
解决方案:
1.先关闭hadop平台。
stop-all.sh。
2.删除hadoop安装文件下生成的几个文件夹:dfs和logs。
rm -rf dfs logs。
3.重新格式化主服务器。
[root@master1 hadoop]# hadoop namenode -format。



评论专区