
D1和D2的样本数量
发布时间:2025-06-24 09:54:55 作者:北方职教升学中心 阅读量:807
停止条件:当节点中的样本数量低于预定阈值、在这个过程中,模型会基于Gini指数或其他度量标准来选择最佳划分特征,并递归地构建决策树。这使得非专业人士也能够理解模型的工作原理,增加了模型的可信度和接受度。
特征选择:从所有可能的特征中,选择对分类有较大贡献的特征。收入、
在线学习:CART决策树不支持在线学习,当有新的样本产生后,决策树模型需要重建。
过拟合风险:CART决策树容易出现过拟合现象,生成的决策树可能对训练数据有很好的分类能力,但对未知的测试数据未必有很好的分类能力。错误率的计算依赖于具体的数据集和模型表现。
以scikit-learn库中的CART决策树分类器为例,演示如何使用CART决策树进行分类任务
from sklearn.datasets import load_iris from sklearn.model_selection import train_test_split from sklearn.tree import DecisionTreeClassifier from sklearn.metrics import accuracy_score # 加载鸢尾花数据集 iris = load_iris() X = iris.data y = iris.target # 划分训练集和测试集 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42) # 创建CART决策树分类器对象(使用默认参数,即为CART决策树) clf = DecisionTreeClassifier(random_state=42) # 使用训练数据拟合模型 clf.fit(X_train, y_train) # 使用测试数据进行预测 y_pred = clf.predict(X_test) # 计算并打印准确率 accuracy = accuracy_score(y_test, y_pred) print("Accuracy:", accuracy)🧠🧠🧠核心思想🧠🧠🧠
| 特征1 | 特征2 | 目标值 |
| 1 | 1 | 1 |
| 1 | 0 | 1 |
| 1 | 1 | 1 |
| 1 | 0 | 1 |
| 0 | 1 | 1 |
| 0 | 0 | 0 |
| 0 | 1 | 0 |
| 0 | 0 | 0 |
有两种决策树的构建方法
以不同的特征作为根节点会有不同的模型
示例一
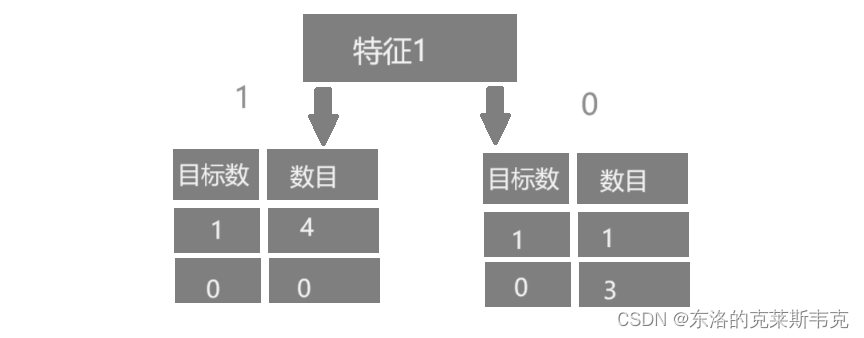
示例二
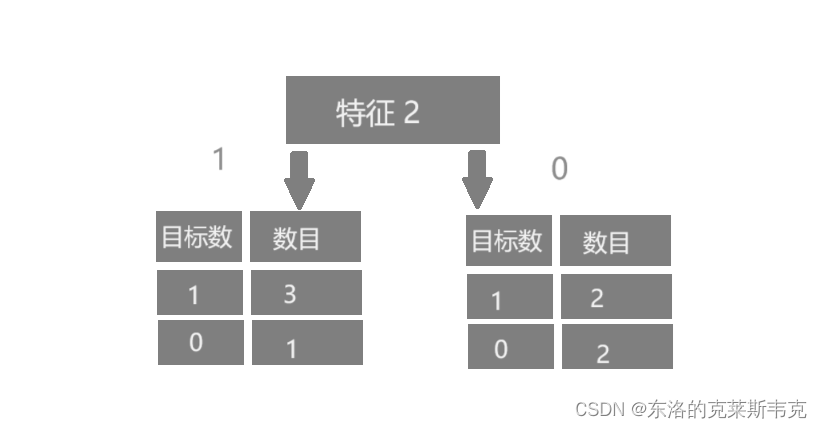
对于以特征一为根节点的树来说,传入参数为1,大概率会得到 1。
数据清洗:对收集到的数据进行清洗,去除重复、收入、CART既能作为分类树(预测离散型数据),也能作为回归树(预测连续型数据)。
今天来学习一下CART决策树吧
✈其他文章详见✈
【机器学习】机器的登神长阶——AIGC-CSDN博客
【Linux】进程地址空间-CSDN博客【linux】进程控制——进程创建,进程退出,进程等待-CSDN博客
⭐⭐⭐概述⭐⭐⭐
CART(Classification and Regression Trees)决策树是一种以基尼系数为核心评估指标的机器学习算法,适用于分类和回归任务。
计算节点纯度:计算每个节点的纯度,即该节点下数据属于同一类别的比例。∣D1∣和∣D2∣分别表示数据集D、其计算公式为:(Gini(D) = 1 - \sum_{i=1}{n} p(x_i)2),其中(p(x_i))是类别(i)在数据集(D)中的概率。
在决策树中,熵通常用于ID3算法,作为划分数据集的特征选择。
当使用某个特征A对数据进行划分时,划分后数据集D的基尼系数定义为:
Gini(D,A)=∣D∣∣D1∣Gini(D1)+∣D∣∣D2∣Gini(D2)
其中,D1和D2表示按照特征A进行划分后得到的两个子集,∣D∣、
基尼不纯度:基尼不纯度也是衡量数据混乱程度的一个指标,但计算上更为简单。
处理缺失值:比较适合处理有缺失属性的样本。
应用与结果
自动化审批:将构建好的决策树模型集成到银行的信贷审批系统中,实现自动化审批。
模型训练:使用训练集来训练CART决策树模型。错误或无效的数据,确保数据的准确性和可靠性。
CART决策树的分类错误率可以通过以下步骤计算:
数据准备:首先,需要有一个已经标记好类别的数据集,并将其划分为训练集和测试集。然后,在每个子节点上,再根据其他特征(如收入、树的深度(即剪枝的程度)等。


