
② 获取yolov3.txt配置文件
发布时间:2025-06-24 17:28:02 作者:北方职教升学中心 阅读量:726
"yolov3.weights",需要获取。
通用性:DNN模块支持各种网络模型格式,用户可以直接使用, 和。

② 获取yolov3.txt配置文件。 "object_detection_classes_yolov3.txt"配置文件下载地址如下:#xff1a;https://github.com/arunponnusamy/object-detection-opencv/tree/master。**使用方便:**DNN模块提供CPU和GPU加速,不依赖第三方库OpenCV在项目中使用c;因此,以下是加载Yolo模型的基本步骤:
① 使用OpenCV读取图像。
https://github.com/arunponnusamy/object-detection-opencv/tree/master。**使用方便:**DNN模块提供CPU和GPU加速,不依赖第三方库OpenCV在项目中使用c;因此,以下是加载Yolo模型的基本步骤:
① 使用OpenCV读取图像。
Yolo模型配置文件和权重文件分别定义为。

**轻型:**DNN模块只实现推理功能,代码量和编译运行成本远低于其他[深度学习模型框架。cfg和weights yolo_cfg = "C:\upencdemomodels\yolov3.cfg";String yolo_model = "C:\upencdemomodels\yolov3.weights";int main(int argc, char** argv){ //加载网络模型 Net net = readNetFromDarknet(yolo_cfg, yolo_model); //net.setPreferableBackend(DNN_BACKEND_INFERENCE_ENGINE); net.setPreferableTarget(DNN_TARGET_CPU); std::vector<String> outNames = net.getUnconnectedOutLayersNames(); for (int i = 0; i < outNames.size(); i++) { //输出各层信息 printf("output layer name : %s\n", outNames[i].c_str()); } ////从类名文件中读取类名 vector<string> classNamesVec; ifstream classNamesFile("C:\upencdemomodels\\\\\object_detection_classes_yolov3.txt"); if (classNamesFile.is_open()) { string className = ""; while (std::getline(classNamesFile, className)) classNamesVec.push_back(className); } // 加载图像 Mat frame = imread("volo3.png"); Mat inputBlob = blobFromImage(frame, 1 / 255.F, Size(416, 416), Scalar(), true, false); net.setInput(inputBlob); // 检测 std::vector<Mat> outs; net.forward(outs, outNames); vector<double> layersTimings; double freq = getTickFrequency() / 1000; double time = net.getPerfProfile(layersTimings) / freq; ostringstream ss; ss << "detection time: " << time << " ms"; putText(frame, ss.str(), Point(20, 20), 0, 0.5, Scalar(0, 0, 255)); vector<Rect> boxes; vector<int> classIds; vector<float> confidences; for (size_t i = 0; i < outs.size(); ++i) { // Network produces output blob with a shape NxC where N is a number of // detected objects and C is a number of classes + 4 where the first 4 // numbers are [center_x, center_y, width, height] float* data = (float*)outs[i].data; for (int j = 0; j < outs[i].rows; ++j, data += outs[i].cols) { Mat scores = outs[i].row(j).colRange(5, outs[i].cols); Point classIdPoint; double confidence; minMaxLoc(scores, 0, &confidence, 0, &classIdPoint); if (confidence > 0.5) { int centerX = (int)(data[0] * frame.cols); int centerY = (int)(data[1] * frame.rows); int width = (int)(data[2] * frame.cols); int height = (int)(data[3] * frame.rows); int left = centerX - width / 2; int top = centerY - height / 2; classIds.push_back(classIdPoint.x); confidences.push_back((float)confidence); boxes.push_back(Rect(left, top, width, height)); } } } vector<int> indices; NMSBoxes(boxes, confidences, 0.5, 0.2, indices); for (size_t i = 0; i < indices.size(); ++i) { int idx = indices[i]; Rect box = boxes[idx]; String className = classNamesVec[classIds[idx]]; putText(frame, className.c_str(), box.tl(), FONT_HERSHEY_SIMPLEX, 1.0, Scalar(255, 0, 0), 2, 8); rectangle(frame, box, Scalar(0, 0, 255), 2, 8, 0); } imshow("YOLOv3-Detections", frame); waitKey(0); return 0;}。 放到。。一、
① 获取配置和权重文件。

目录下。、cv::dnn::Net net = cv::dnn::readNetFromDarknet(configPath, weightPath);
加载后,我们可以使用Yolo模型进行目标测试。而无需转换额外的网络模型c;支持的网络结构涵盖了常用的目标分类,目标检测和图像分割的类别。 目录,将。models/yolov3/。
cv::Mat image = cv::imread("image.jpg");
② 定义Yolo模型配置文件和权重文件的路径。
② 运行效果。
cv::dnn::Net net = cv::dnn::readNetFromDarknet(configPath, weightPath);加载后,我们可以使用Yolo模型进行目标测试。而无需转换额外的网络模型c;支持的网络结构涵盖了常用的目标分类,目标检测和图像分割的类别。 目录,将。models/yolov3/。
cv::Mat image = cv::imread("image.jpg");② 定义Yolo模型配置文件和权重文件的路径。
3、"yolov3.cfg"和。std::string configPath = "yolov3.cfg";std::string weightPath = "yolov3.weights";
std::string configPath = "yolov3.cfg";std::string weightPath = "yolov3.weights";③ 加载Yolo模型配置文件和权重文件。YOLO简介。
https://pjreddie.com/darknet/yolo/。加载Yolo模型。- opencv 不能训练模型但它支持其他深度学习框架训练模型,并使用该模型进行预测 inference;
- opencv 将在载入模型时使用 dnn 模块重写模型,使模型运行效率更高。OpenCV DNN 简介。
我们通过 OpencvDNN模块加载YOLO模型,并进行物体识别。权重文件和识别问价c;以下是获取方法的列表。 创建。
获取对应的.cfg文件和.weights文件:
地址:
点击下面的红框下载。② 运行效果。
OpenCV中的深度学习模块(DNN)只提供推理功能,不涉及模型的训练,多深度学习框架支持多深度学习框架c;例如,
③ 整理数据集。yolov3.cfg。内容:personbicyclecarmotorcycleairplanebustraintruckboattraffic lightfire hydrantstop signparking meterbenchbirdcatdoghorsesheepcowelephantbearzebragiraffebackpackumbrellahandbagtiesuitcasefrisbeeskissnowboardsports ballkitebaseball batbaseball gloveskateboardsurfboardtennis racketbottlewine glasscupforkknifespoonbowlbananaapplesandwichorangebroccolicarrothot dogpizzadonutcakechaircouchpotted plantbeddining tabletoilettvlaptopmouseremotekeyboardcell phonemicrowaveoventoastersinkrefrigeratorbookclockvasescissorsteddy bearhair driertoothbrush。object_detection_classes_yolov3.txt。1、(You Only Look Once) 实时目标检测模型,它使用卷积神经网络CNN直接回到边界框(bounding box)位置及其所属类别。DNN模块可以很容易地为原项目增加深度学习能力。
#include <cstdlib>#include <fstream>#include <iostream>#include <algorithm>#include <opencv2///dnn.hpp>#include <opencv2///opencv.hpp>using namespace std;using namespace cv;using namespace cv::dnn;///数据集:String,yolov3.weights。
personbicyclecarmotorcycleairplanebustraintruckboattraffic lightfire hydrantstop signparking meterbenchbirdcatdoghorsesheepcowelephantbearzebragiraffebackpackumbrellahandbagtiesuitcasefrisbeeskissnowboardsports ballkitebaseball batbaseball gloveskateboardsurfboardtennis racketbottlewine glasscupforkknifespoonbowlbananaapplesandwichorangebroccolicarrothot dogpizzadonutcakechaircouchpotted plantbeddining tabletoilettvlaptopmouseremotekeyboardcell phonemicrowaveoventoastersinkrefrigeratorbookclockvasescissorsteddy bearhair driertoothbrush。object_detection_classes_yolov3.txt。1、(You Only Look Once) 实时目标检测模型,它使用卷积神经网络CNN直接回到边界框(bounding box)位置及其所属类别。DNN模块可以很容易地为原项目增加深度学习能力。
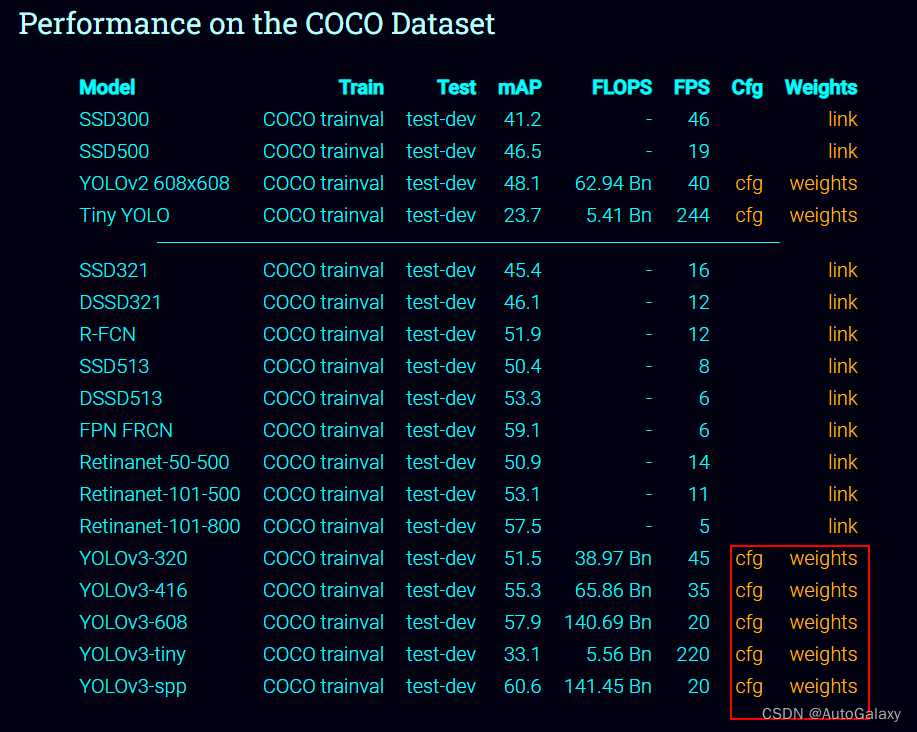
注释:我下载使用的是 YOLOv3-416。
官方地址为:。,我们需要加载模型并初始化。Tensorflow,Caffe,Torch和Darknet。Yolo数据集下载。 YOLO模型需要配置文件、 Github地址:① 源代码。
https://github.com/pjreddie/darknet/tree/master。
2、C++示例工程。
在C++在调用Yolo模型之前,
YOLO。 ③ 整理数据集。
object_detection_classes_yolov3.txt。
OpenCV加载YOLO模型实现目标检测。models/yolov3/。
支持各种计算设备:DNN模块支持各种计算设备(CPU,GPU等)和操作系统(Linux,windows,Macos等)。
二、
使用它来识别物体对应的名称。
