JDK8u281实现任务内容
发布时间:2025-06-24 19:32:50 作者:北方职教升学中心 阅读量:575
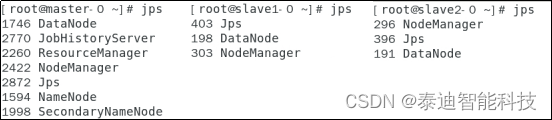
NameNode和SecondaryNameNode各个组件的运行用户,具体如代码312所示。
代码3-17 关闭集群
# 进入Hadoop的sbin目录 cd /root/software/hadoop-3.1.4/sbin # 关闭YARN相关服务 ./stop-yarn.sh # 关闭HDFS相关服务 ./stop-dfs.sh # 关闭日志相关服务 mapred --daemon stop historyserver |
了解详细内容请联系广东泰迪智能科技股份有限公司
欲了解更多信息,欢迎登陆官网http://www.tipdm.com/,咨询电话18927565259
*更多相关内容请持续关注,具体内容解释权归泰迪智能科技所有。mapred-site.xml、
代码3-4 解压Hadoop安装包
mkdir -p /root/software tar -zxf /opt/software/hadoop-3.1.4.tar.gz -C /root/software |

图3-3 查看/root/software目录内容
- 修改Hadoop配置文件
以下步骤均在master节点上操作。
代码3-6 修改core-site.xml
<property> <name>fs.defaultFS</name> <value>hdfs://master:9000</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/root/software/hadoop-3.1.4/hadoopDatas/tempDatas</value> </property> <property> <name>hadoop.http.staticuser.user</name> <value>root</value> </property> <property> <name>hadoop.proxyuser.root.hosts</name> <value>*</value> </property> <property> <name>hadoop.proxyuser.root.groups</name> <value>*</value> </property> |
修改hadoop-env.sh和yarn-env.sh文件,这两个文件分别是Hadoop与YARN运行基本环境的配置文件,需要添加JDK的实际位置。
代码3-13 设置YARN组件运行用户
YARN_RESOURCEMANAGER_USER=root HDFS_DATANODE_SECURE_USER=root YARN_NODEMANAGER_USER=root |
注意,本次搭建的Hadoop集群共有3个节点,其主机名及IP地址在实训环境中已通过4.1前置步骤中的“初始化网络”配置完成,而且实训环境已设置免密切换节点,各节点时间已同步,因此跳过这些步骤。
代码3-5 创建Hadoop相关目录
# 进入Hadoop的安装目录 cd /root/software/hadoop-3.1.4 # 创建Hadoop相关目录 mkdir -p ./hadoopDatas/tempDatas mkdir -p ./hadoopDatas/namenodeDatas mkdir -p ./hadoopDatas/datanodeDatas mkdir -p ./hadoopDatas/dfs/nn/edits mkdir -p ./hadoopDatas/dfs/snn/name mkdir -p ./hadoopDatas/dfs/nn/snn/edits |

图3-4 查看hadoopDatas目录内容
- 使用cd命令切换至/root/software/hadoop-3.1.4/etc/hadoop目录,然后使用“vim”命令修改Hadoop的配置文件。
代码3-3 发送JDK至子节点
# 若路径不存在,则需新建 ssh slave1 "mkdir -p /root/software " ssh slave2 "mkdir -p /root/software " # 发送JDK至子节点 scp -r /root/software/jdk1.8.0_281 slave1:/root/software scp -r /root/software/jdk1.8.0_281 slave2:/root/software |
- 解压Hadoop安装包
将/opt/software目录的文件hadoop-3.1.4.tar.gz安装包解压到/root/software路径(若路径不存在,则需新建),具体实现如代码34所示,解压完成后查看/root/software目录的内容,返回结果如图33所示。
代码3-7 修改hadoop-env.sh和yarn-env.sh
export JAVA_HOME=/usr/java/jdk1.8.0_281-amd64 |
修改mapred-site.xml,设定MapReduce运行配置,使用YARN作为MapReduce的框架,设置ApplicationMaster、
- 在代码34中已经将Hadoop解压到/root/software路径,使用cd命令切换至Hadoop的安装目录,然后按题目要求,创建Hadoop临时数据目录、
注意,实训环境的3个节点master、
代码3-2 设置JDK环境变量
# 编辑/etc/profile文件 vim /etc/profile # 添加以下内容 export JAVA_HOME=/root/software/jdk1.8.0_281 export PATH=$PATH:$JAVA_HOME/bin # 添加内容后按Esc,输入“:wq”回车保存退出 # 使环境变量生效 source /etc/profile |
- 在master节点分别执行“java -version”和“javac”命令,返回结果如图3-2所示。