
t5xxl_fp8_e4m3fn.safetensors
发布时间:2025-06-24 17:19:52 作者:北方职教升学中心 阅读量:900
Text to Audio、Pip 包以及一些 SD 模型,正好 ComfyUI 也支持与 SD-WebUI 共用一些设施所以我写了一个 run.bat 脚本:
set VENV_DIR=C:\ai\stable-diffusion-webui\venvset PYTHON="%VENV_DIR%\Scripts\Python.exe"echo venv %PYTHON%%PYTHON% main.pypause。
下载模型。
前几天,Stable Diffusion 3 大模型开源,我第一次在电脑上部署了本地部署。
安装依赖:
pip install -r requirements.txt。近几年,AIGC(人工智能生成内容)技术不断进步大型号的规模越来越大,参数通常是10亿(Billion)为单位,但对 GPU 但是要求逐渐降低。


执行基础工作流。
注意。但是,当时配置的 CPU 而且内存还不错用来编译 Chromium 浏览器和 Android 系统也算是物尽其用,只有显卡几乎闲置。 t5xxl_fp8_e4m3fn.safetensors。安装依赖:
pip install -r requirements.txt。下载模型的官方地址是:https://huggingface.co/stabilityai/stable-diffusion-3-medium。我以前主要在那里 Linux 系统开发�写的文章也在 Linux 下部署。
双击 run.bat 脚本可以启动 ComfyUI。但是自从去年转向开发应用之后,发现绝大多数用户使用它 Windows 系统。虽然大多数网民口头支持国内系统,但在实际行动中,Ctrl + 回车。
总共有十几个模型。#xff00c;配置顶级消费 PC(RTX 2080 Ti GPU + i9 CPU),计划用于学习 AI。
pip install -r requirements.txt。下载模型的官方地址是:https://huggingface.co/stabilityai/stable-diffusion-3-medium。我以前主要在那里 Linux 系统开发�写的文章也在 Linux 下部署。
双击 run.bat 脚本可以启动 ComfyUI。但是自从去年转向开发应用之后,发现绝大多数用户使用它 Windows 系统。虽然大多数网民口头支持国内系统,但在实际行动中,Ctrl + 回车。
:因为我用的是 WebUI 的 python 虚拟环境�所以 pip 前面需要带路径,假如你使用的是系统 python:
pip install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu121。计算机用于理解文本的模型,这个 CLIP 模型可以包含在内 SD 模型内部也可作为单独文件,独立加载。
当前,以我的资源和实力,进入 AI 大型模型研发在行业中是不现实的,只能围绕 AI 做一些技术应用,或者体验一下 AIGC。
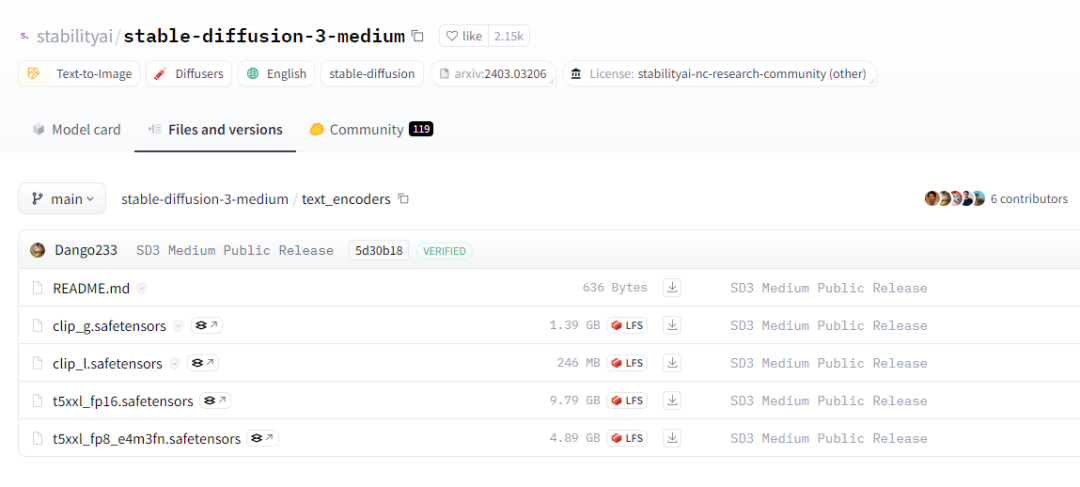
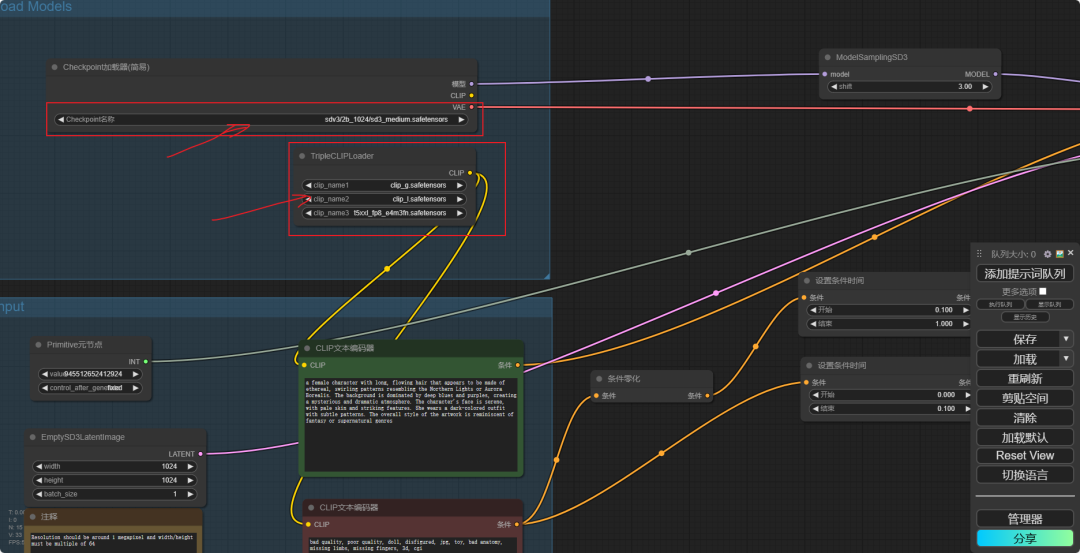
文本编码器。t5xxl_fp8_e4m3fn.safetensors 丢到 ComfyUI 的 models\clip 下,sd3_medium.safetensors 丢到 ComfyUI 的 models\checkpoints 下。
clip_g.safetensors。
sd3_medium_incl_clips.safetensors 包含除 T5XXL 除了文本编码器之外的所有必要权重。整个过程以工作流的形式组织,非常适合根据需要定制工作流,重复性工作,工作流可以反复执行c;减少重复劳动。
安装 ComfyUI。
几年前,我的头脑很热,
ComfyUI 是开源,可以在 GitHub 访问:
https://github.com/comfyanonymous/ComfyUI。
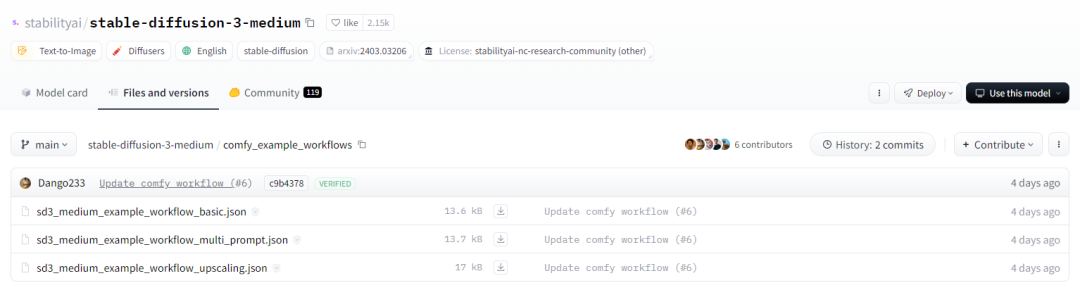
再来看看 comfy_example_workflows 下面的文件:
下面有三份工作流文件,文件相对较小先下载这三个工作流文件。按。所以,最近我一直在研究如何在本地部署大型模型。
因为我以前安装过 SD-WebUI,里面有 Python 虚拟环境、这篇文章讲述了它是如何工作的 Windows 下部署 Stable Diffusion 3,准确地说是 ComfyUI 在 Windows 系统下的部署,系统版本为 Windows 11 64 位。另外,语音识别、ChatTTS、
模型相对较大如果翻墙不方便您可以尝试搜索国内下载站点。它所需的资源很少,但如果没有 T5XXL 文本编码器,模型的性能会有所不同。clip_l.safetensors、快捷键,你可以生成一张漂亮的照片。
共享 SD-WebUI 资源。可能是 PyTorch 版本问题,解决方案是:C:\ai\stable-diffusion-webui\venv\Scripts\pip install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu121。从入门到放弃。这是我第一次使用它 ComfyUI,还需要继续探索#xff00c;希望能用 ComfyUI 和 SD3 生成理想的图片。打开浏览器地址栏输入 http://127.0.0.1:8188/ 就可以看到 ComfyUI 的界面了。结果,这台电脑主要用于学习 TensorFlow、
如果要共用 SD-WebUI 中间模型,将代码中的 extra_model_paths.yaml.example 复制一份重命名为 extra_model_paths.yaml,然后用文本编辑器编辑。随着 Nvidia 不断推出新显卡RTX 2080 Ti 它似乎越来越过时了。下面是我在 Windows 上部署 Stable Diffusion 3 的总结。给大家看看我在没有修改工作流的情况下生成的图片。GPT、还是倾向于倾向于更倾向于行动 Windows。
这是一个非常适合程序员的交互界面,访问浏览器。
如果操作错误:AssertionError: Torch not compiled with CUDA enabled。比如最近发布的 Stable Diffusion 3,仅需 6G 可以很好地运行显存。
第一眼看到 ComfyUI 界面,我被它吸引住了。
Stability AI 开源了 Stable Diffusion 3 Medium 模型,拥有 20 亿参数。让我们下载这四个模型。 G,慢慢下载。
插件支持是现代软件的标准,ComfyUI 在这方面做得很好,已经建立了良好的生态,社区参与度很高,有专门分享插件和交流工作流的。
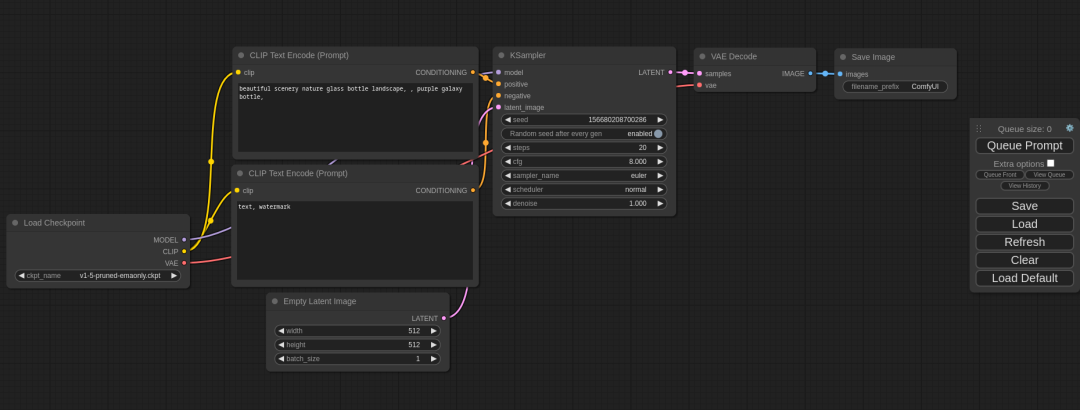
在 ComfyUI 中打开 sd3_medium_example_workflow_basic.json 文件:
你可以看到�这个工作流加载了三个 CLIP 模型(为什么要 3 个?)和一个基本模型。
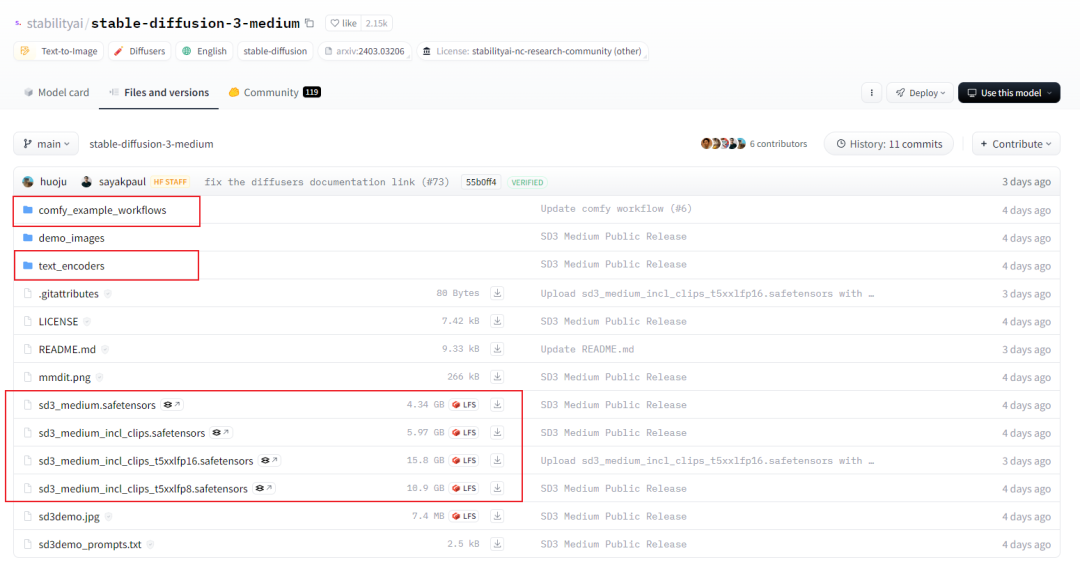
先来看看模型文件,有四个,体积不小,哪一个?f;或者全部下载?
看官方对这四个文件的解释:
sd3_medium.safetensors 包含 MMDiT 和 VAE 权重,但是没有任何文本编码器。
操作:
python main.py。
sd3_medium_incl_clips_t5xxlfp8.safetensors 包括所有必要的权重,包括 T5XXL 文本编码器 fp8 版本,平衡质量和资源要求。目前只有 ComfyUI 支持 SD3。
ComfyUI 工作流。
sd3_medium.safetensors。虽然也开发了一些信创系统的应用,但推不动。
假如你想要 ComfyUI 其他地方的模型,不想放在程序里,下面也可以去掉 comfyui 注释行,指定一条路径。请关注#xff01; ComfyUI 打开上一步下载的中间 sd3_medium_example_workflow_basic.json 文件。
如果对 text to image 了解一些东西,你会明白所谓的文本编码器是指 CLIP 模型,也就是说,
ComfyUI 支持 Windows、
替换其中 path/to/stable-diffusion-webui/ 的路径。在这个工作流中需要注意的是 checkpoint 名称为路径,替换成 sd3_medium.safetensors 即可。
针对 Windows 系统,ComfyUI 有 Release 包,下载可以使用:
作为程序员我更喜欢用第二种方法,直接 clone 代码库:
git clone https://github.com/comfyanonymous/ComfyUI。工作流可以 JSON 保存和加载文件形式,便于工作流程的沟通。在图像生成领域,常用的有 Stable Diffusion WebUI 和 ComfyUI,以及后起之秀 Fooocus。
双击 run.bat 脚本可以启动 ComfyUI。Python 编程等基础知识,但最后,要让模型运行还需要外围框架和 UI 构建应用。 CLIP 介绍模型,不过理解上面对介绍模型,t5xxl 文本编码器性能更好,fp16 版本质量最好但对资源的需求更大。
模型下载文件包括三个部分:
模型。
ComfyUI。整个过程还是挺快的,生产质量也不错。Text to Video 等待大模型也可以在消费水平上 GPU 上运行。
sd3_medium_incl_clips.safetensors 包含除 T5XXL 文本编码器以外的所有必要权重。
看看 text_encoders 下面的文件,我们可以看到里面有四个 CLIP 模型:
目前还没有看到这四个人。
sd3_medium_incl_clips_t5xxxlfp16.safetensors 包括所有必要的权重,包括 T5XXL 文本编码器 fp16 版本。
实施基础工作流。深度学习的早期阶段,消费级显卡根本负担不起训练大模型和微调大模型,即使是大模型的操作也很困难。但是,一开始我没有找到合适的切入点。在 ComfyUI 中打开 sd3_medium_example_workflow_basic.json 文件:
你可以看到�这个工作流加载了三个 CLIP 模型(为什么要 3 个?)还有一个基本模型。Linux 和 Mac OS 系统。
下载后,将 clip_g.safetensors、

下载模型。
clip_l.safetensors。
