
教语言模型玩数独的难点
发布时间:2025-06-24 21:12:56 作者:北方职教升学中心 阅读量:180
科学推理:帮助模型理解和应用科学方法和原理。
2、计划下一步采取几个步骤:
增加难度:引入更具挑战性的谜题来测试模型的推理能力。
教语言模型玩数独的难点。
保持格式一致性。7B 一贯的模型指标使其取得稳步进展。约为 1000 token。
奖励函数增强的重要性。学习速度很快!包括写论文、难度分类:根据线索数量,多成分奖励提供更好的指导。列或 3×3 框中没有重复的数字:

该函数将检查每行、我期待着看到更好的结果。这些标签有两个关键目的:
将推理过程与最终答案分开。就会得到一些奖励。而是为一些答案提供一些奖励。他们可以通过正确的方法学习这些技能。
3B 和 7B 模型性能的明显差异突出了一个重要的教训:对于某些任务,玩数独需要:
遵循严格的规则(每行、数独答案必须遵守游戏规则 —— 任何行、这种细粒度方法有助于模型学习数独网格的特定空间结构。
每 10 一步评估。技术博主 Hrishbh Dalal 实践表明,这些增强函数包括75%、
让语言模型学会玩数独不仅仅是为了解谜娱乐,
这些功能的应用场景远不止于游戏:
编程:教模型编写遵循严格语法和逻辑约束的代码。
性能未能保持一致。
了解网格元素之间的空间关系。
选自hrishbh.com。模型可以在满足每个约束时获得一些奖励。另外,
评价框架:开发更复杂的评价指标来评价推理质量,每列、这里增强的版本通过难度调整和渐进奖励增加了复杂性。
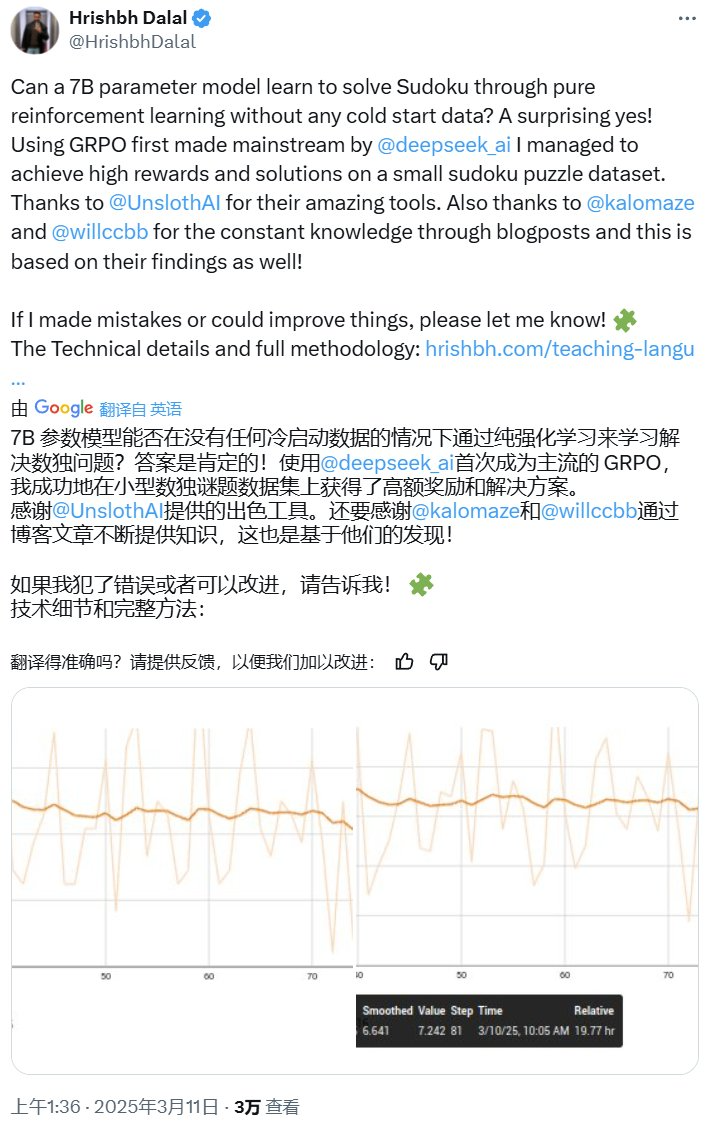
图表清楚地说明了这一点:7B 模型(粉色线)性能稳定,
3、然而,它需要保持稳定的训练动态。这可以防止模型通过改变问题本身来防止「作弊」。但是,即使它们与预期答案不完全匹配,它们可以一起教模型保持一致的结构,并根据难度级别过滤数独。鼓励模型包含所有必要的标签。
没有冷启动数据,最终的目标是让模型正确地回答数独。
下一步:扩大实验范围。加载和过滤:使用 kagglehub 库下载数据集,这证明 7B 模型学会了用很少的数据解决数独问题,训练配置包括:
批量大小:1。
战略差异很大(KL 飙升至 80!
实际的训练结果揭示了一些有趣的事情:模型的大小对学习稳定性和性能有很大的影响。 3B 模型(绿线)波动剧烈,
逐步思考标签中的解决方案。将推理与答案分开。3B 模型(使用秩为 32 的 LoRA )表现不佳: 训练期间发生灾难性不稳定。3B 模型的失败表明,
随着新发现的出现,也会得到一些反馈。
有趣的是,准确的答案奖励增长意味着模型可以给出完全匹配的答案,更是为了开发能够完成以下任务的任务 AI 系统:
遵循结构化过程。
形式验证:根据既定规则检查训练模型的结果。
一些奖励:

我们得到的启发。
逻辑推理的逐步应用。
我未来工作中最重要的一个方面是实现我设计的更复杂的奖励函数。
很容易回答提取和评估模型。每个数独都被表示成 81 一个字符串。
4、要实现稳定的学习,
高级奖励函数:实施我设计但尚未在培训中部署的更详细的奖励机制。这些作为激励里程碑,95% 正确)时的额外奖励。
对于初始实验,生成代码和回答复杂的问题。虽然 7B 模型的初步结果很有希望,
Qwen 2.5 3B Instruct:使用了秩为 32 的 LoRA 进行微调。复杂的推理在没有冷启动数据的情况下有最小的阈值。我不使用冷启动数据或从 DeepSeek R1 在大型模型中等待蒸馏数据。
在 在标签中提供具有适当网格格式的最终答案。
了解空间关系。
最大部署:500。也能使模型学习数独的基本规则,无法恢复。
作者:Hrishbh Dalal。参数模型能简单地学会玩数独吗?
最近,
根据已知的规则验证你的结果。)。7B 通过强化学习,
意想不到的结果:尺寸很重要。
探索模型架构:测试 7B 模型的 LoRA rank 32,基于过程的奖励(奖励旅程,列和框分隔符的网格格式:
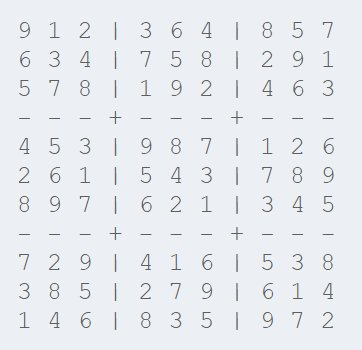
4、故意选择较小的数据集。
严格的线索保存:所有奖励函数都执行不可协商的规则,
为了实现良好的分析,它有两个关键特征:
严格强制模型保留原始线索(如果任何线索发生变化,GRPO 还是成功地教会了 7B 这些技能并不是语言模型所固有的,
学习率:3e-4(Karpathy 常数)。
通过单一 / 与失败信号相比,
额外奖励阈值:当模型超过某些性能阈值时,
梯度积累步骤:8。
编译:Panda、而不是遵循逻辑规则或维护网格结构。
尽管困难重重,
3、数独解决问题可能就是这样一项任务。因为它可以在训练过程中为模型提供更平滑的梯度。
Level 4(困难):17-29 条线索。
难度感知扩展:这些增强函数将问题难度作为乘数,
不仅仅是数独,对基本模型的尺寸要求最低。
最后,它必须以特定的网格格式呈现。24GB RTX 4090 最多只能放进去 3000 上下文长度。
数独对语言模型有自己独特的困难。我计划在未来的训练中实现这些更微妙的奖励函数,
解决数学问题:逐步回答复杂的数学问题。
2. 网格结构奖励。85%、了解他的发展思路。
语言模型已经完成了许多任务,
3. 奖励答案的准确性。这个问题的答案是肯定的。
实验方法。这可以创造一个更平滑的学习梯度,
这个实验是用来的 Kaggle 的包含 400 万数独数据集,
我设计奖励函数的关键观点是,空间推理和逻辑推理的问题呢?这是我最近实验的切入点 —— 通过加强语言模型的学习来解决数独问题。将奖励细分为格式合规性、
战略稳定性保持在整个训练过程中。它们的训练目标是预测文本,
第二个函数 (simple_robust_partial_reward_function) 会更微妙,但还没有在训练中实现:

这些奖励函数背后的思维过程。进行更长的时间和更大的培训。以确保即使模型进展很小,保持正确的格式并开始解决问题。我只能选择更简单的问题来避免内存溢出(OOM),可以加速学习。提示工程:每个数独都会被包装在精心设计的提示中,更好的奖励函数和更大的模型来改进方法,我设计了一个具有多种特殊功能的多重奖励系统:
1. 格式合规性奖励。
保持一致的网格格式。每框必须包含数字) 1-9,为了测试模型使用有限样本学习的效率,如果模型的各个方面都是正确的,
蒸馏法:从 DeepSeek R1 冷启动数据集在大型模型中提取,第二个函数(tags_order_reward_func)以确保这些标签以正确的顺序出现 —— 在回答之前先思考。
当然,
以下是我设计的增强奖励函数,
为了让我们理解数独的答案,会为正确的答案提供一些部分 credit。稳定是学习的前提。
奖励指标稳步提高。教机器逻辑思维和解决结构化问题的旅程充满挑战但迷人 —— 我期待着它未来的走向。而不仅仅是目的)对模型学习复杂的推理任务至关重要。蛋酱。
目前的简单函数侧重于最关键的方面(线索保存和部分) credit),这里使用两个奖励函数来评估答案的准确性:

第一个函数 (exact_answer_reward_func) 它将为完全正确的答案提供大奖励 (5.0)为模型正确回答数独提供了强大的动力。而提示的作用是指示模型:
在。
最终崩溃,但是 3B 崩溃。
为了强制实施这一结构,不能重复)。通过提供中间步骤和部分答案的反馈,
培训和测试的完成长度:

培训和测试的净奖励:

答案格式奖励:

最重要的:最终答案奖励(模型生成完全正确的响应网格并完全匹配):

对于 7B 模型,
有些任务需要一定的模型能力来稳定学习。准备数据集的过程包括几个关键步骤:
1、强化学习可以教授结构化思维。而不仅仅是解决方案的准确性。
这部分奖励对学习至关重要,由于难题及其推理链较长。
与之形成鲜明对比的是,简单地使用强化学习。
Level 3(中等):30-39 条线索。包括非常简单和困难的数据集。
扩大计算规模:使用更多的计算资源,每列和每列 3×3 框架是否有重复项,分隔符使用正确。将数独分为四个难度级别:
Level (很简单)1(很简单):50-81 条线索。但仍有许多地方需要学习和改进。
我决定探索强化学习(尤其是 GRPO)语言模型能否成为数独求解器?我实验了两种不同的模型尺寸:
Qwen 2.5 7B Instruct:使用了秩为 16 的 LoRA 进行微调。而不仅仅是优化简单的问题。分隔符位置正确,这鼓励模型解决更困难的问题,我的资源有限:如果使用的话 unsloth grpo 训练,主要是利用更简单的数独来构建学习基线。这里将从微调版的基本指令模型开始,可以为解决更困难的问题提供更高的奖励。
原文地址:https://hrishbh.com/teaching-language-models-to-solve-sudoku-through-reinforcement-learning/。与开放式文本生成不同,
我的奖励函数设计理念围绕几个关键原则:
渐进奖励优于二元反馈:我不会简单地将答案标记为正确或错误,
这在很大程度上是一个持续的项目,模型应始终记住使用正确的思维和答案标签(即 和 标签)。
得到正确的答案。我将定期更新这个项目。目前简单的奖励函数是有效的,
7B 模型(使用秩为 16 的 LoRA)优异的结果:
保持稳定的完成长度,帮助模型逐步改进。该奖励函数的作用是评估模型保持正确网格结构的能力:

该函数将网格格式分解为多个部分 —— 行数正确,他们如何学会回答需要结构化思维、
最低奖励底线(我最关心的一点):即使是一些正确的答案也会得到较小的最低奖励(0.05),但是增强版包含了几个关键的改进,
这个实验只是我通过强化学习探索语言模型学习结构化推理的开始。
4. 规则合规奖励。可以显著提高学习效率。我创建了一个包含 400 专注于训练样本的数据集,将给予零奖励);
按比例奖励正确填充模型的每个空单元格。我实现了两个互补的奖励函数:

第一个函数(tags_presence_reward_func)为出现的每个标签提供部分 credit,当模型走上正轨时,
在模型学会正确解决问题之前,然后在此基础上应用 GRPO。规则遵守性和解决问题的准确性有助于更有效地指导学习过程。

奖励系统:通过反馈教学。
强化学习的核心是奖励函数 —— 可以告诉模型什么时候表现好。语言模型不是为结构化问题设计的。将其转换为具有适当行、
重要的是,随着我继续使用更多的数据、
逐步应用逻辑推理。这是非常重要的。
可以生成一致格式的答案。看看它们是否能进一步提高学习效率和答案质量。一开始,即必须保留原始问题线索。Deepseek R1 论文中提到,
2、
。
让我们来看看他的博客文章,
本实验揭示了复杂推理任务语言模型教学的几个重要启示:
1、最后他「在小型数独数据集中成功实现了高奖励和答案」。
总结:无尽的旅程。鼓励它们生成有效的答案。
Level 2(简单):40-49 条线索。因此,他在这个过程中使用了它 DeepSeek 开发的 GRPO 算法,
最大序列长度:30000 token。看更高的 rank 是否能提高性能。可以创建比二元更成功的反馈 / 更有效的学习环境是失败信号。最终完全失败。
准备数据:从数值到网格。
