
树莓派Linux实现ChatGPT语音交互(语音识别,TTS)
发布时间:2025-06-24 16:37:39 作者:北方职教升学中心 阅读量:207
文章目录
- 前言
- 一、ChatGPT API获取
- 二、API使用步骤
- 三、语音识别
- 三、TTS(语音合成)
- 四、音频播放
- 五、功能整合
- 总结
前言
ChatGPT使用想必大家都不陌生,进入官网,注册账号即可开始正式的对话聊天,可是如何使用ChatGPT API,且在Linux环境下进行语音交互呢?碰巧在今年暑期参加物联网设计竞赛有用到这项功能,今天就来教下大家详细步骤。
一、ChatGPT API获取
如何获取一个ChatGPT账号相比对大家来说不是一件难事,网上教程很多大家可以搜一下,获取到一个账号后,可以进入https://platform.openai.com/account/api-keys页面。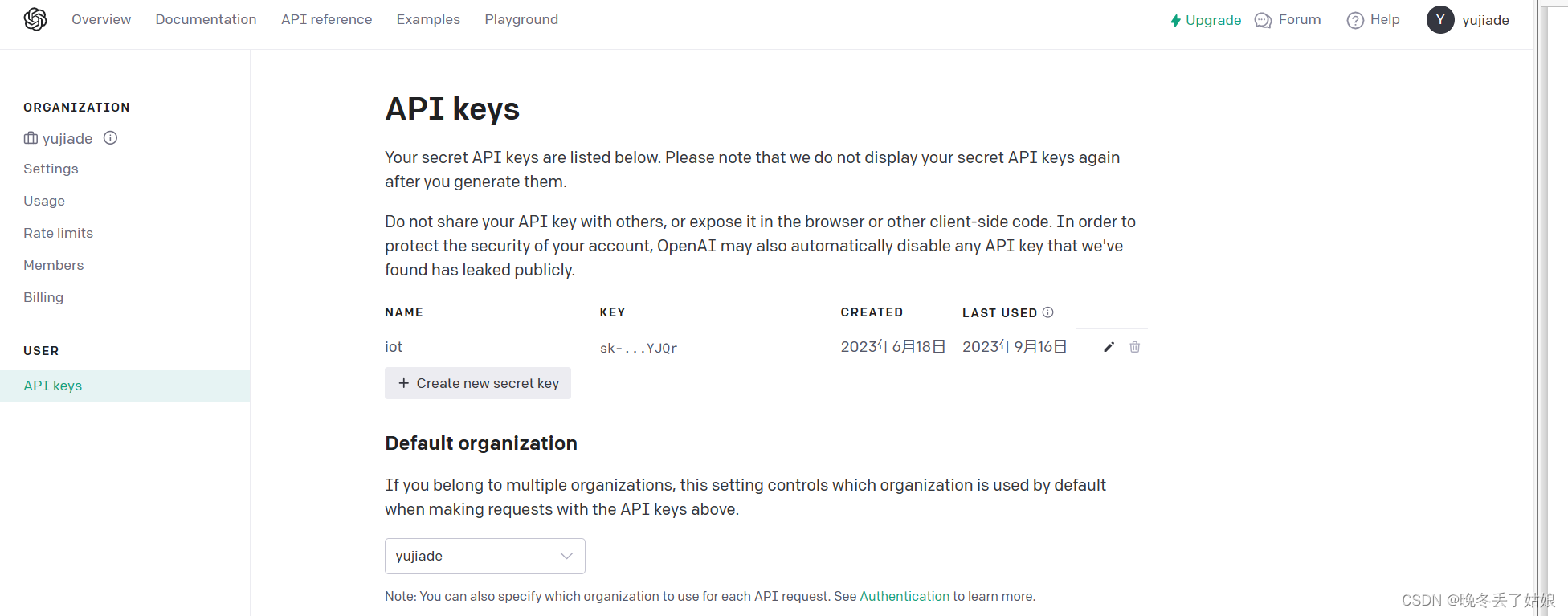
选择创建一个api key 大家一定要保存好这个密钥,后续使用都是利用这个密钥。这里需要注意免费API每个账户都是有限的,五美元,理论上自己日常使用时用不完了的。
二、API使用步骤
接下来就让我们来试验一下API密钥。首先在Linux环境下需要安装openai的包这里我们以树莓派为例。
pip3 install openai成功安装后我们就可以创建一个Python运行一下,而众所周知,ChatGPT是需要需要使用魔法的,API调用也不例外。
# -*- coding: utf-8 -*-importopenai# 设置OpenAI API密钥openai.api_key ='sk-xxxx'#这里需要替换为你的账户API KEY# 定义初始对话历史conversation_history =[{'role':'system','content':'You are a helpful assistant.'}]# 循环交互whileTrue:# 处理用户输入user_input =input("User: ")# 将用户输入添加到对话历史中conversation_history.append({'role':'user','content':user_input})# 发送聊天请求response =openai.ChatCompletion.create(model='gpt-3.5-turbo',messages=conversation_history,max_tokens=100,n=1,stop=None,temperature=0.7)# 获取助手的回复assistant_reply =response['choices'][0]['message']['content']# 打印助手的回复print("Assistant:",assistant_reply)# 将助手的回复添加到对话历史中conversation_history.append({'role':'assistant','content':assistant_reply})# 检查用户是否选择退出循环ifuser_input.lower()=='exit':break通过以上代码实现简单的API调用,运行。
问出问题,就可以得到你想要的答案。其中的模型大家也可以根据需求选用。
三、语音识别
首先最重要的是外接一个麦克风设备,对外界实时音频进行识别,这里树莓派上使用的无驱的USB麦克风设备。
想要实现真正意义上的语音交互,就只能从实时音频流中读取。
这里我们使用的是Google的语音识别API SpeechRecognition。
首先在终端中安装相关包。
pip3 install SpeechRecognition成功安装,且麦克风设备安装完成,我们就可以进入下一步。
我们使用一个Python程序来进行实现。
importspeech_recognition assr# 创建一个Recognizer对象r =sr.Recognizer()# 使用麦克风录音withsr.Microphone()assource:print("请说话:")audio =r.listen(source)# 将语音转换为文本try:text =r.recognize_google(audio,language='zh-CN')print("你说的是:"+text)exceptsr.UnknownValueError:print("无法识别你的语音")exceptsr.RequestError ase:print("无法连接到Google API,错误原因:"+str(e))这里是实现实时音频的识别。需要注意的是,speech_recognition的使用也需要Linux环境下的魔法上网。
运行代码会出现许多报错信息,但这些都不影响我们的识别结果。
当显示请说话示例时就可以提出问题了。实测在安静环境下识别速度和识别准确率还是非常高的。
识别返回的结果保存在text中,只要将text赋值给上述GPT的输入即可。
三、TTS(语音合成)
要想实现语音对话,还需要将GPT回复的问题经过TTS转化为音频。
这里使用的阿里云的Sambert语音合成,实测合成速度很快,且语音自然。
首先需要下载Sambert的包
pip3 install dashscope试验一下
# coding=utf-8importdashscopefromdashscope.audio.tts importSpeechSynthesizerdashscope.api_key='your-dashscope-api-key'result =SpeechSynthesizer.call(model='sambert-zhichu-v1',text='今天天气怎么样',sample_rate=48000,format='wav')ifresult.get_audio_data()isnotNone:withopen('output.wav','wb')asf:f.write(result.get_audio_data())print(' get response: %s'%(result.get_response()))执行代码后就能生成一个output.wav文件,文件内容就是text中问出的问题。
四、音频播放
得到了生成的音频文件,我们还需要将他播放出来。
Linux环境下python播放音频播放我尝过各种方式,最后使用效果最好,延时最低的是使用pygame来播放。
还是以同样的步骤,安装pygame。
pip3 install pygame五、功能整合
将所有功能进行整合,即可实现最后想要实现的功能。
# -*- coding: utf-8 -*-importopenaiimportpygamefrompygame importmixerimportdashscopefromdashscope.audio.tts importSpeechSynthesizerimportspeech_recognition assrimporttime# 创建一个Recognizer对象r =sr.Recognizer()mixer.init()# 设置OpenAI API密钥openai.api_key ='sk-xx'dashscope.api_key='sk-xx'# 定义初始对话历史conversation_history =[{'role':'system','content':'You are a helpful assistant.'}]# 循环交互whileTrue:# 处理用户输入# 使用麦克风录音withsr.Microphone()assource:print("请开始说话...")audio =r.listen(source)try:# 使用语音识别引擎将音频转换为文字text =r.recognize_google(audio,language='zh-CN')print("识别结果:",text)exceptsr.UnknownValueError:print("无法识别音频")exceptsr.RequestError ase:print("请求出错:",e)user_input =text # 将用户输入添加到对话历史中conversation_history.append({'role':'user','content':user_input})# 发送聊天请求response =openai.ChatCompletion.create(model='gpt-3.5-turbo',messages=conversation_history,max_tokens=100,n=1,stop=None,temperature=0.7)# 获取助手的回复assistant_reply =response['choices'][0]['message']['content']result =SpeechSynthesizer.call(model='sambert-zhimiao-emo-v1',text=assistant_reply,sample_rate=48000,format='wav')# 打印助手的回复print("Assistant:",assistant_reply)ifresult.get_audio_data()isnotNone:withopen('output.wav','wb')asf:f.write(result.get_audio_data())mixer.music.load('output.wav')mixer.music.play()# 将助手的回复添加到对话历史中conversation_history.append({'role':'assistant','content':assistant_reply})time.sleep(1)whilepygame.mixer.music.get_busy()!=True:# 在音频播放完成之前不退出程序passprint(' get response: %s'%(result.get_response()))运行代码,就可以的到想要得到的效果。因代理问题,最后效果会有短暂的延时。
总结
该案例实现起来不难,找准如何使用才是关键所在,这里实现的用ChatGPT,也可换成文心一言等国内大模型,其效果更好,响应速度更快。本次的分享也就到这里,如果还有什么问题请各位批评指教,大家一起相互学习。
