发布时间:2025-06-24 19:49:31 作者:北方职教升学中心 阅读量:732
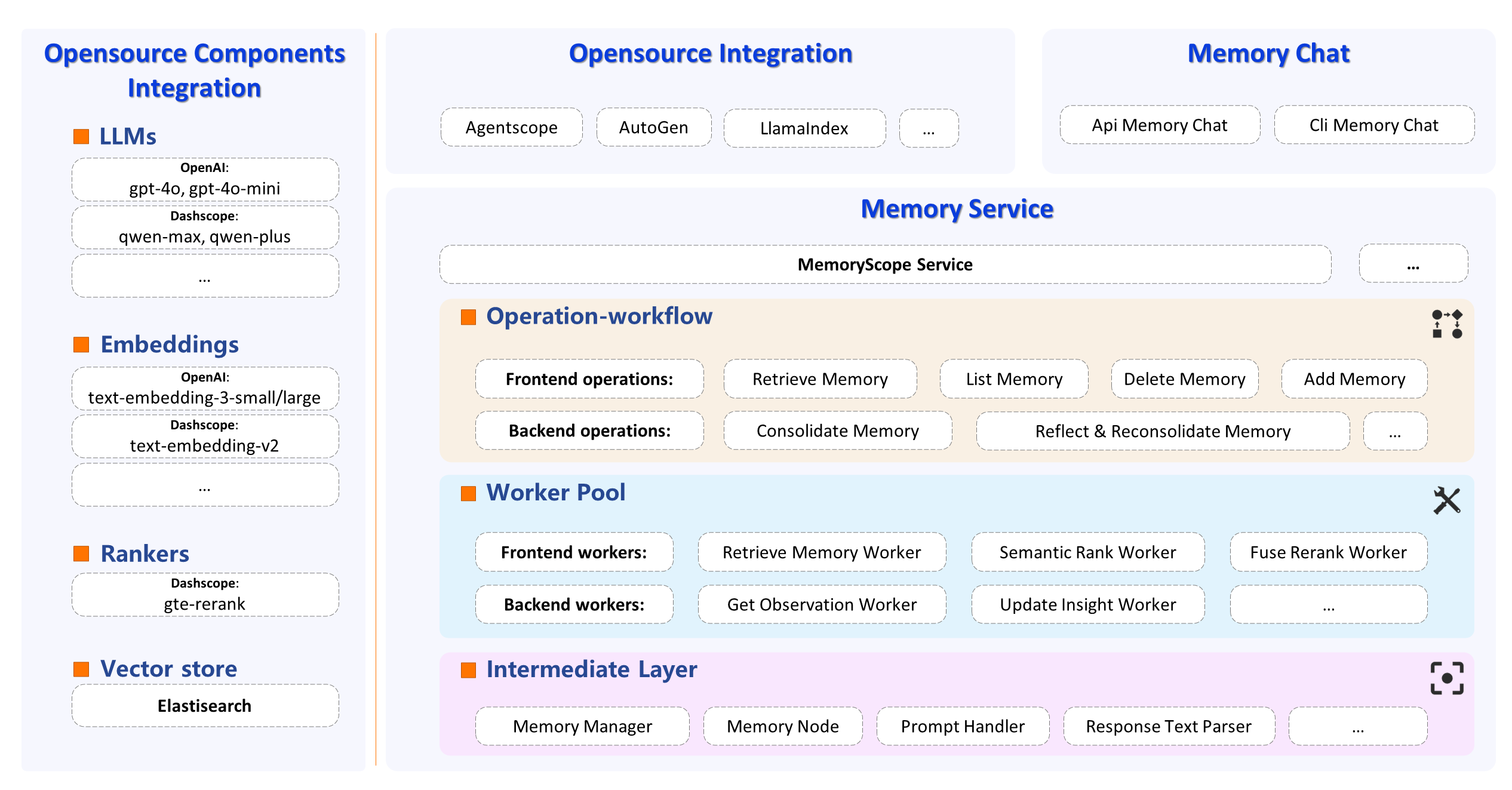
“反思与再巩固”,则是对observations进行反思,以insight形式的记忆片段存储起来,确保记忆片段不矛盾和重复。observation抽取,insight更新等20+Worker。
记忆,连接着过去和当下,承载着经验和人格。
为了能够使用硅基的 Embedding 模型,我们可以参考源码中的 DashScopeEmbedding,新建一个 Embedding 类:
class BgeEmbedding(BaseEmbedding): base_url: str = Field(description="The base URL for the BGE API") api_key: str = Field(description="The API key for the BGE API") model_name: str = Field(description="The model name")然后,修改Embedding获取的同步实现函数:
def get_general_text_embedding(self, texts: str) -> List[float]: """Get embedding.""" payload = {"model": self.model_name, "input": texts, "encoding_format": "float"} headers = {"Authorization": f"Bearer {self.api_key}","Content-Type": "application/json"} response = requests.request("POST", self.base_url, json=payload, headers=headers) return response.json()['data'][0]["embedding"]修改Embedding获取的异步实现函数:
async def aget_general_text_embedding(self, prompt: str) -> List[float]: payload = {"model": self.model_name, "input": prompt, "encoding_format": "float"} headers = {"Authorization": f"Bearer {self.api_key}","Content-Type": "application/json"} async with aiohttp.ClientSession() as session: async with session.post(self.base_url, json=payload, headers=headers) as response: return await response.json()['data'][0]["embedding"]最后,修改 yaml 配置文件的embedding_model部分:
embedding_model: class: core.models.llama_index_embedding_model module_name: bge_embedding model_name: BAAI/bge-m3 base_url: https://api.siliconflow.cn/v1/embeddings api_key: xxx3.6 ReRank 模型配置
ReRank 模型定义在memoryscope/core/models/llama_index_rank_model.py。记忆: None[MEMORY ACTIONS]:new observation: 用户爱好是吉他。
3. MemoryScope 实战
3.1 环境准备
首先准备 MemoryScope 环境,这里推荐大家本地安装,方便后续对代码修改:
git clone https://github.com/modelscope/memoryscopecd memoryscopeconda create -n memoryscope python=3.10 -yconda activate memoryscopepip install -e . # 基于项目根目录的 `setup.py` 进行安装3.2 ElasticSearch 部署
项目依赖 ElasticSearch 作为向量数据库,推荐大家采用 Docker 一键安装:
# -e用于设置环境变量,-d 用于放到后台运行docker run -d -p 9200:9200 -e "discovery.type=single-node" -e "TZ=Asia/Shanghai" -e "xpack.security.enabled=false" -e "xpack.license.self_generated.type=trial" --name es docker.elastic.co/elasticsearch/elasticsearch:8.13.2由于官方仓库默认只支持 OpenAI 和 阿里百炼的 API,二者都需要付费使用。
2. MemoryScope 简介
官方地址:https://github.com/modelscope/MemoryScope
老规矩,先来简单介绍下~
MemoryScope 有哪些亮点?
- ⚡低延迟:多线程实现。
前面和大家分享过
短期记忆的实现:- AIoT应用开发:给机器人接入’记忆’,完美解决「和谁对话&多轮对话」
简单来说,
短期记忆的实现:利用 SQLite 数据库缓存用户的聊天记录,将多轮对话的内容作为上下文,和当前对话内容一起交给 LLM 进行推理。
本文关注的 MemoryScope采用的就是第二种方案,向量数据库采用 ElasticSearch。有情怀的陪伴式 AI 对话机器人。
今日分享,手把手带大家实操 MemoryScope的具体实现,全程免费。
Worker库: 能力原子化,抽象成单独的worker,包括query信息过滤、
问题来了:如何才能优雅地实现 LLM 的长期记忆?
个人理解:肯定少不了 RAG,但实操起来才发现麻烦重重!
直到发现阿里开源的 MemoryScope,问题似乎有解了。