您现在的位置是:Flink源码分析(12)Flink SQL执行流程源码分析 >>正文
Flink源码分析(12)Flink SQL执行流程源码分析
德薄能鲜网5人已围观
简介Flink SQL执行主要包括以下四个部分:解析。使用Calcite的解析器,解析SQL为语法树(SqlNode)。校验。按照校验规则ÿ...
Flink SQL执行主要包括以下四个部分:
解析。使用Calcite的解析器,解析SQL为语法树(SqlNode)。
校验。按照校验规则,检查SQL的合法性,同事重写语法树。
转换。将SqlNode转换为Releational tree。再包装为Flink的Operation。
执行。根据上一步生成的Operation,将其翻译为执行计划。
Flink SQL的执行入口主要有两个方法,一个是StreamTableEnvironment.executeSql(sql),另一个是StreamTableEnvironment.sqlQuery(sql),由于executeSql()方法在内部的调用逻辑上可以覆盖sqlQuery(sql)方法,最终会汇总到同一条执行路径,因此关于Flink SQL执行流程源码分析从executeSql(sql)方法开始进行SQL执行源码分析。
Flink SQL模块的真正目的是将用户提交的SQL语句转换成Flink DataStream的形式,最后提交生成的DataStream算子到执行引擎去执行的过程。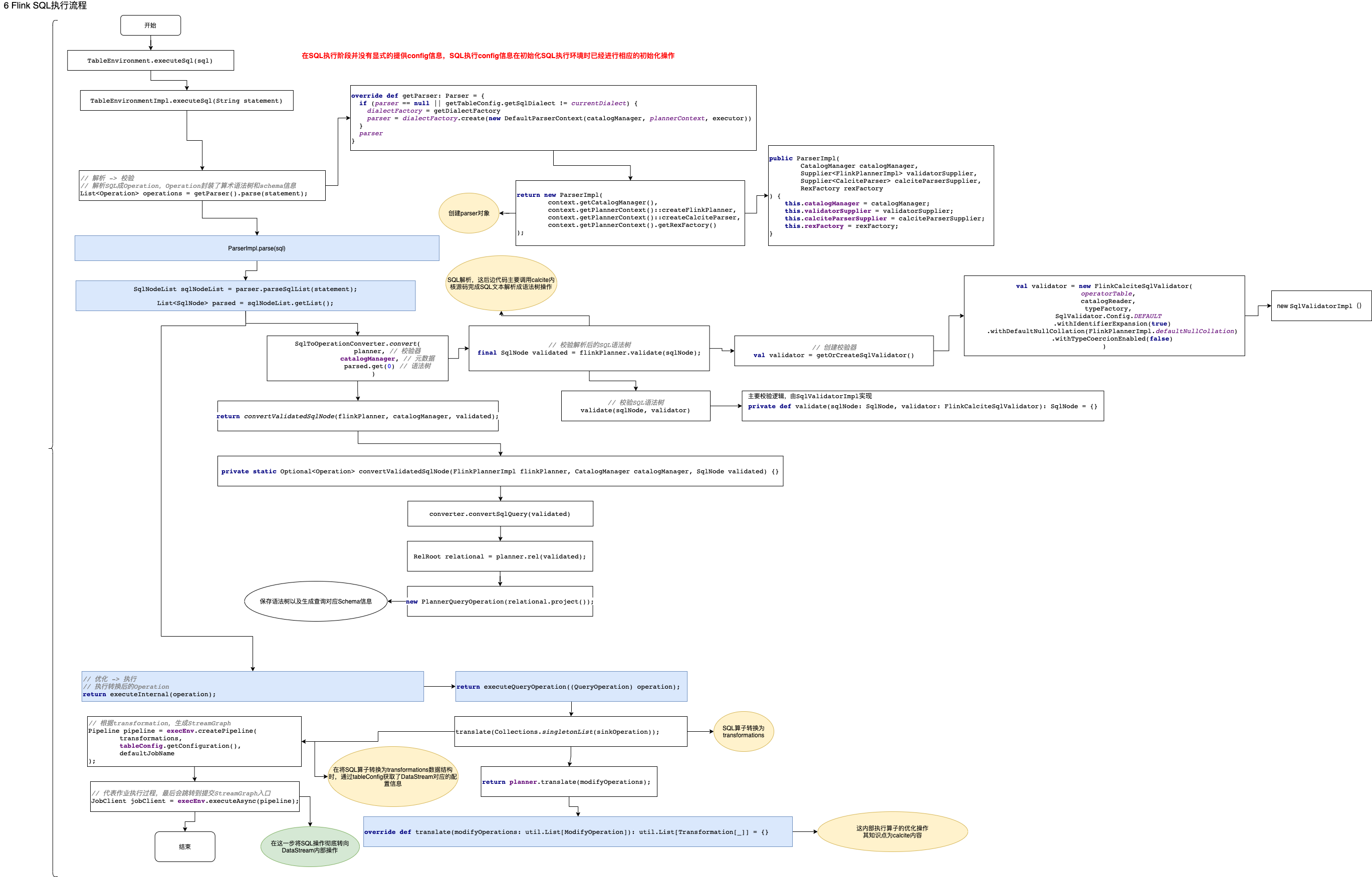
从
executeSql(sql)开始:publicTableResultexecuteSql(Stringstatement){ // 解析 -> 校验// 解析SQL成Operation,Operation封装了算术语法树和schema信息List<Operation>operations =getParser().parse(statement);// 这里一个SQL一个SQL执行,不能一次提交多个SQL语句 if(operations.size()!=1){ thrownewTableException(UNSUPPORTED_QUERY_IN_EXECUTE_SQL_MSG);}Operationoperation =operations.get(0);// 优化 -> 执行// 执行转换后的OperationreturnexecuteInternal(operation);}这个方法覆盖了SQL执行的整个流程在宏观上的阶段划分,其中
- getParser().parse(statement):完成SQL语句到SQL AST的转换和校验两个步骤的动作;
- executeInternal(operation):完成SQL的优化和向DataStream转换两个主要动作;
SQL解析基础知识
- SQL解析:SQL语句转换为结构化的SQL AST的过程
- SQL校验:SQL语法、元数据等验证,验证通过SQL意味这在语义语法层面是正确的SQL语句,可提供执行
- SQL优化:包含SQL逻辑优化和SQL物理优化
- 逻辑优化:根据关系代数理论根据规则对SQL进行转换,将SQL转换为更高效的执行模式的过程,常见的逻辑优化规则包括
- 谓语下推
- 常量折叠
- 物理优化:根据数据的元数据和统计信息等对SQL执行路径进行成本计算,选择最小成本执行路径的过程,常见的物理优化手段包括:
- Join算法选择
- 多表Join顺序选择
- 表扫描方式(全表扫描还是索引扫描等)
- 逻辑优化:根据关系代数理论根据规则对SQL进行转换,将SQL转换为更高效的执行模式的过程,常见的逻辑优化规则包括
- SQL执行:将优化过的SQL提交执行器执行,逻辑上对应真正处理数据的过程,在Flink SQL角度来看是将优化的关系代数树转换为Flink DataStream算子的过程。
下面开始分析
getParser().parse(statement),首先是getParser()// 1 getParser()实现 publicParsergetParser(){ returngetPlanner().getParser();}// 2 planner对象在创建table执行环境时创建publicPlannergetPlanner(){ returnplanner;}这里的planner是在SQL执行环境初始化阶段完成的实例化,代码(这里的内容请参考《Flink源码分析(11)Flink SQL执行环境初始化源码分析》)如下:
// 实例化SQL Planner,这里追踪Stream模式,因此是StreamPlannerfinalPlannerplanner =PlannerFactoryUtil.createPlanner(executor,tableConfig,userClassLoader,moduleManager,catalogManager,functionCatalog);下面通过planner获取SQL解析器:
overridedefgetParser:Parser ={ if(parser ==null||getTableConfig.getSqlDialect !=currentDialect){ dialectFactory =getDialectFactory // 如果parser没有实例化,那么这条语句创建了parser parser =dialectFactory.create(newDefaultParserContext(catalogManager,plannerContext,executor))}parser}可以发现parser是通过代码
dialectFactory.create(new DefaultParserContext(catalogManager, plannerContext, executor))实现的,追踪create()方法publicParsercreate(Contextcontext){ returnnewParserImpl(context.getCatalogManager(),context.getPlannerContext()::createFlinkPlanner,// 计划器context.getPlannerContext()::createCalciteParser,// calcite解析器context.getPlannerContext().getRexFactory());}可以发现parser是ParserImpl实例,在实例parser的过程中,会给parser变量赋值flink planner和calcite paeser,下面让我们分别追踪方法
createFlinkPlanner和createCalciteParser。方法
createFlinkPlannerreturn new FlinkPlannerImpl(createFrameworkConfig(), this::createCatalogReader, typeFactory, cluster);方法
createCalciteParserreturn new CalciteParser(getSqlParserConfig());
上面获得了parser对象,下面让我们追踪
parse(statement)都做了什么publicList<Operation>parse(Stringstatement){ // 获取Calcite的解析器,在创建parser对象时构建CalciteParserparser =calciteParserSupplier.get();// 1-解析 使用FlinkPlannerImpl作为validator,在创建parser对象时构建FlinkPlannerImplplanner =validatorSupplier.get();// 扩展解析器,用来解析calcite解析器无法解析的扩展SQL语句// 对于一些特殊的写法,例如SET key=value。CalciteParser是不支持这种写法的// 为了避免在Calcite引入过多的关键字,这里定义了一组extended parser,专门用于在CalciteParser之前,解析这些特殊的语句Optional<Operation>command =EXTENDED_PARSER.parse(statement);if(command.isPresent()){ returnCollections.singletonList(command.get());}// parse the sql query// use parseSqlList here because we need to support statement end with ';' in sql client.// 解析SQL为语法树,这里的parser对象是上面构建parser对象的属性,是calcite的SQL解析对象// 真正解析SQL的方法在Calcite内部,此处复杂度很高,不做展开// 返回对象SqlNode就是Calcite的SQL AST,直到这一步,已经完成了SQL解析工作SqlNodeListsqlNodeList =parser.parseSqlList(statement);List<SqlNode>parsed =sqlNodeList.getList();Preconditions.checkArgument(parsed.size()==1,"only single statement supported");returnCollections.singletonList(// 2-校验 将解析过的语法树转换为operatorSqlToOperationConverter.convert(planner,// 校验器catalogManager,// 元数据parsed.get(0)// 语法树).orElseThrow(()->newTableException("Unsupported query: "+statement)));}这段代码实现了两个主要的功能
SQL解析:由
parser.parseSqlList(statement)调用Calcite的SQL解析模块对SQL语句执行解析,返回SqlNode对象即Calcite的SQL语法树对象。SQL语法树向FlinkSQL Operation的转换:由
SqlToOperationConverter.convert()执行,让我们进入方法追踪publicstaticOptional<Operation>convert(FlinkPlannerImplflinkPlanner,CatalogManagercatalogManager,SqlNodesqlNode){ // validate the query// 校验解析后的SQL语法树,由SqlValidatorImpl实现,返回SQL语法语义正确的SQL// 到这里才真正完成了SQL的第一步工作,SQL校验 finalSqlNodevalidated =flinkPlanner.validate(sqlNode);returnconvertValidatedSqlNode(flinkPlanner,catalogManager,validated);}在这里完成了SQL的第二步工作,SQL校验的完成,接着调用
convertValidatedSqlNode(flinkPlanner, catalogManager, validated)// 创建SqlToOperationConverter,它负责SQL转换SqlToOperationConverterconverter =newSqlToOperationConverter(flinkPlanner,catalogManager);......// 判断SqlNode的类型,采用不同的转换逻辑if(validated.getKind().belongsTo(SqlKind.QUERY)){ // 查询语句转换入口returnOptional.of(converter.convertSqlQuery(validated));}......追踪查询语句转换逻辑,即代码
converter.convertSqlQuery(validated),它会继续调用toQueryOperation(flinkPlanner, node),如下privatePlannerQueryOperationtoQueryOperation(FlinkPlannerImplplanner,SqlNodevalidated){ // transform to a relational tree// 转换为relational tree,即这里将SQL语法树转换为关系代数树,SQL优化工作都是基于关系代数树规则进行的优化// 这里内部的核心转换逻辑也是Calcite实现的,这里不做深入研究RelRootrelational =planner.rel(validated);// 保存语法树以及对应的由SQL生成查询对应Schema信息// 算术语法树保存到了变量 calciteTree 中 returnnewPlannerQueryOperation(relational.project());}直到这里正是完成了最终的代码
List<Operation> operations = getParser().parse(statement)的工作。
下面我们追踪内部的优化和转换的入口,从
executeInternal(operation)开始// 执行自定义扩展SQL入口// try to use extended operation executor to execute the operationOptional<TableResultInternal>tableResult =getExtendedOperationExecutor().executeOperation(operation);// if the extended operation executor return non-empty result, return itif(tableResult.isPresent()){ returntableResult.get();}// 执行标准Calcite SQL入口......// 执行查询语句入口}elseif(operation instanceofQueryOperation){ returnexecuteQueryOperation((QueryOperation)operation);}elseif(operation instanceofExecutePlanOperation){ ......这里包含两个部分,一个部分是针对Flink 自定义的一些SQL执行操作,这部分不深入研究,有兴趣读者请自己钻研;另一部分就是标准的Calcite SQL流程,这里由于分支比较多,我们只研究query语句的转换逻辑,即代码
executeQueryOperation((QueryOperation) operation)处。下面我们进入标准查询语句的执行流程研究中,执行查询语句入口源码如下
privateTableResultInternalexecuteQueryOperation(QueryOperationoperation){ // 创建一个本地收集ModifyOperation结果的OperationCollectModifyOperationsinkOperation =newCollectModifyOperation(operation);// 将上一步的sinkOperation翻译为Flink的Transformation// 重要的方法,中间记录了如何将Operation翻译为transformation// StreamExecutionEnvironment中的属性定义:protected final List<Transformation<?>> transformations = new ArrayList<>();List<Transformation<?>>transformations =translate(Collections.singletonList(sinkOperation));// 设置作业名称finalStringdefaultJobName ="collect";resourceManager.addJarConfiguration(tableConfig);// We pass only the configuration to avoid reconfiguration with the rootConfiguration// 根据transformation,生成StreamGraphPipelinepipeline =execEnv.createPipeline(transformations,tableConfig.getConfiguration(),defaultJobName );try{ // 代表作业执行过程,最后会跳转到提交StreamGraph入口JobClientjobClient =execEnv.executeAsync(pipeline);// 用于帮助jobClient获取执行结果ResultProviderresultProvider =sinkOperation.getSelectResultProvider();resultProvider.setJobClient(jobClient);// 构建TableResultImpl对象returnTableResultImpl.builder().jobClient(jobClient).resultKind(ResultKind.SUCCESS_WITH_CONTENT).schema(operation.getResolvedSchema()).resultProvider(resultProvider).setPrintStyle(PrintStyle.tableauWithTypeInferredColumnWidths(// sinkOperation.getConsumedDataType() handles legacy typesDataTypeUtils.expandCompositeTypeToSchema(sinkOperation.getConsumedDataType()),resultProvider.getRowDataStringConverter(),PrintStyle.DEFAULT_MAX_COLUMN_WIDTH,false,isStreamingMode )).build();}catch(Exceptione){ thrownewTableException("Failed to execute sql",e);}}这段代码是SQL查询语句执行的入口源码,根据后边的调用链这段代码主要完成了三类动作,分别是
- SQL优化:针对SQL语句执行优化规则,返回优化后的SQL语句
- SQL翻译:将优化后的SQL语句转换为Flink DataStream的核心对象transformations(其实Flink SQL和Flink DataStream的关联就是从这个对象开始的,Flink DataStream程序会根据java代码DAG自动生层transformations,然后去执行剩余的公共流程;而Flink SQL代码是通过翻译器将SQL语句自动转换为transformations对象,然后去执行剩余的公共流程)
- 启动Flink DataStream执行:根据转换后的transformations,引领进入Flink DataStream的执行流程。
下一步的核心代码是
translate(Collections.singletonList(sinkOperation)),让我们深入观察/** * 包含了从Operation获取关系表达式,优化,生成执行节点图和转换为Flink Transformation的步骤 * 执行翻译工作,将SQL转换得到的Operation转换为Stream环境变量属性 transformations * 然后根据翻译得到的 transformations 就可以进行任务的部署提交流程,这些工作就进入到了flink核心算子内部进行 */overridedeftranslate(modifyOperations:util.List[ModifyOperation]):util.List[Transformation[_]]={ // 执行转换前的检查beforeTranslation()// 如果modifyOperations为空,返回一个空的Transformation集合if(modifyOperations.isEmpty){ returnList.empty[Transformation[_]]}// 转换Operation为Calcite的relation expression(关系表达式)// modifyOperations被包装成了 CollectModifyOperation 类型// relNodes 返回的事封装了原始SQL执行计划的 LogicalSink 对象valrelNodes =modifyOperations.map(translateToRel)// 优化valoptimizedRelNodes =optimize(relNodes)// 生成执行图 valexecGraph =translateToExecNodeGraph(optimizedRelNodes,isCompiled =false)// 执行图转换为transformationsvaltransformations =translateToPlan(execGraph)// 执行转换后的清理等工作afterTranslation()// 返回转换后的对象transformations}这里涉及内容比较复杂后边展开说明。
Tags:
相关文章
三星 One UI 7.0 Beta 5 更新截图曝光:电池图标变粗,快速设置开关变宽
Flink源码分析(12)Flink SQL执行流程源码分析IT之家 3 月 11 日新闻,科技媒体 sammyguru 昨日3 月 10 日)发布博文,报道称适用于 Galaxy S24 Ultra 的 One UI 7.0 Beta 5 内部测试版本被曝光...
阅读更多
NVIDIA宣布推出光电集成封装网络交换机Spectrum
Flink源码分析(12)Flink SQL执行流程源码分析NVIDIA 今天推出了 NVIDIA Spectrum-X™ 和 NVIDIA Quantum-X 使用硅光网络交换机 AI 工厂可以跨区域连接数百万 GPU ,同时,能耗和运营成本大大降低。 NV...
阅读更多
《双影奇境》还能让电玩店再次伟大吗?
Flink源码分析(12)Flink SQL执行流程源码分析资料来源:游戏研究社。油管上有一个叫MinnnMax的游戏频道。上个月,他们问了《双影奇境》制作人Josef很多问题,其中第二个问题是:“你打算怎么把《怪物猎人:荒野》玩家拉来玩《双影奇境》?”。Jo...
阅读更多