
发布时间:2025-06-24 19:00:58 作者:北方职教升学中心 阅读量:574
而Zookeeper可以提供分布式锁和选举的功能,因此Kafka可以利用Zookeeper来实现leader选举。
综上所述,Kafka依赖Zookeeper主要是为了协调分布式系统、因此,在安装kafka之前需要先安装JDK
Kafka 为什么依赖 Zookeeper
- 1.协调分布式系统:Kafka是一个分布式系统,各个节点之间需要进行协调和同步,而Zookeeper正是为分布式系统提供协调和同步的服务的。
自定义字段
当我们的元数据没办法支撑我们的业务时,我们还可以自定义添加一些字段filebeat.inputs:- type: log enabled: truepaths: - /opt/elk/logs/*.log tags: ["web", "test"]#添加自定义tag,便于后续的处理fields: #添加自定义字段from: web-test fields_under_root: true#true为添加到根节点,false为添加到子节点中setup.template.settings: index.number_of_shards: 3output.console: pretty: trueenable: true添加完成后,重启 filebeat
./filebeat -e-cshengxia-log.ymlfilebeat.inputs:-type:log enabled:truepaths:-/opt/elk/logs/*.logtags:["web","test"]fields:from:web-test fields_under_root:falsesetup.template.settings:index.number_of_shards:1output.elasticsearch:hosts:["192.168.40.150:9200","192.168.40.137:9200","192.168.40.138:9200"]Logstash 配置
1.修改Logstash 配置文件(下面 output 将日志打印到本地,观察日志是否采集到,日志格式是否正确)
cat>/usr/local/logstash-7.16.1/config/logstash.conf <<"EOF"input { kafka { bootstrap_servers => "10.0.5.163:9092" topics => ["hosts_10-0-5-163"] group_id => "test" codec => "json" }} filter { if [type] == "access" { json { source => "message" remove_field => ["message","@version","path","beat","input","log","offset","prospector","source","tags"] } }} output { stdout { codec=>rubydebug }}EOF2.执行前台启动命令
#查看是否已存在进程,将其停止ps-ef|greplogstash |grep-vgrep|awk'{print $2}'|xargskill-9#启动 Logstashlogstash -f/usr/local/logstash-7.16.1/config/logstash.conf3.查看kafka Group 和队列信息
#进入kafka 安装目录cd/usr/local/kafka_2.12-3.4.0/bin#查看所有topic./kafka-topics.sh --bootstrap-server 10.0.5.163:9092 --lis#查看Group./kafka-consumer-groups.sh --bootstrap-server 10.0.5.163:9092 --list#查看队列./kafka-consumer-groups.sh --bootstrap-server 10.0.5.163:9092 --grouptest--describe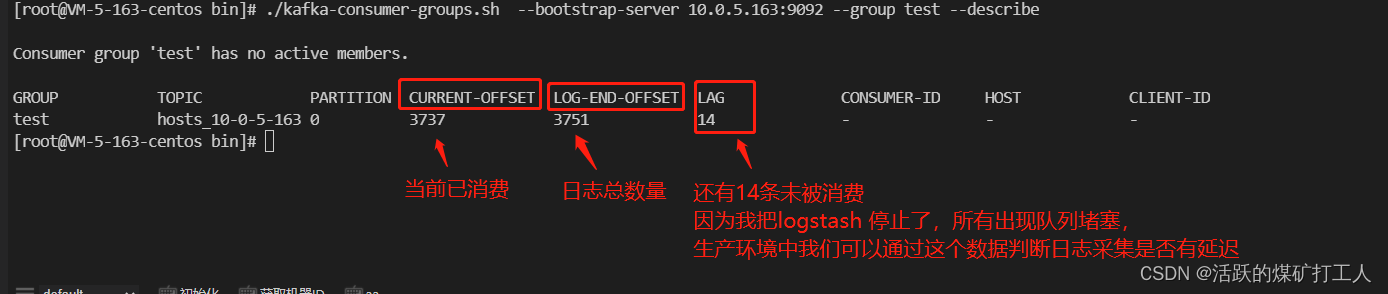
4.修改配置文件,将output 将日志写入elasticsearchcat>/usr/local/logstash-7.16.1/config/logstash.conf <<"EOF"input { kafka { bootstrap_servers => "10.0.5.163:9092" topics => ["hosts_10-0-5-163"] group_id => "test" codec => "json" }}filter { if [type] == "access" { json { source => "message" remove_field => ["message","@version","path","beat","input","log","offset","prospector","source","tags"] } }} output{ if [type] == "access" { elasticsearch { hosts => ["http://127.0.0.1:9200"] user => "elastic" password => "elk@2023" index => "access-%{+YYYY.MM.dd}" } } else if [type] == "messages" { elasticsearch { hosts => ["http://127.0.0.1:9200"] user => "elastic" password => "elk@2023" index => "messages-%{+YYYY.MM.dd}" } }}EOF4.后台启动 Logstash
#查看是否已存在进程,将其停止ps-ef|greplogstash |grep-vgrep|awk'{print $2}'|xargskill-9#启动 Logstashnohuplogstash -f/usr/local/logstash-7.16.1/config/logstash.conf >/tmp/logstash.log 2>&1&查看服务日志是否正常
查看日志是否有 ERROR 持续输出tailf /tmp/logstash.log #查看logstash 端口是否监听netstat-lntp|grep9600
