目录。
AIGC🎨缓解数据稀缺问题❓。
论文研究的动机✏️。
作者是怎么做到的?❓。
#x1f9f0实验配置;
#x1f50d实验结果;
结论✅。
#x1f49000实践;
裂缝图片需要增强。
在stable-difusionv1-5上,根据论文中的参数进行textual inversion微调。
假如直接使用stable-difusionv1-5模型图。
AIGC🎨缓解数据稀缺问题❓。
🤔自2022年以来,diffusion模型在艺术设计、海报创作、产品设计等领域产生了创新影响。对于算法研究人员来说,,一个发人深省的问题是:diffusion模型能否为算法开发的数据处理链接带来新的动力?在各种视觉算法应用的背景下,数据的质量和规模直接关系到模型性能的优缺点,特别是面对少样本学习�这个挑战�其核心是探索如何在极限有限的标记样本基础上使算法,实现对未见类别的有效泛化。
🔍该技术的前沿挑战了以往机器学习模型高度依赖大规模数据集来实现高性能的局限性,📊特别适用于数据采集成本高、获取难度大的特定情况,例如精确分析医学图像,自动识别稀有生物类型,以及对新兴商品市场趋势的预测和分析。diffusion模型通过在这些“数据稀缺”场景中的创新应用,不仅拓宽了算法应用的边界,还重新定义了数据效率和模型泛化的标准,在有限的资源下,为算法开发开辟了追求高效率的新途径。
👀做过视觉分类任务的朋友也应该知道,区分猫和狗的基本分类任务,x1f431;🐶相对简单的,但在实际应用中,分类任务往往要复杂得多c;尤其是在少样本学习的情况下。在这种情况下我们面临的挑战升级,远不止于典型的日常分类问题。在这种情况下我们面临的挑战升级,远不止日常生活中看到的典型分类问题。在现实世界的应用场景中,我们可能会遇到非常专业的细分领域分类,例如,识别不同类型的细胞结构和细微的地质结构变体,或者区分高度相似的稀有植物种类。 这些类别不仅数量少,而且#xff0c;很难收集到大量样本而且类别之间的差异可能极其微妙,要求模型具有较高的辨别能力和泛化能力。📖所以今天我们就来介绍一下CMU团队2023年的工作,主要讲述diffusion是如何通过数据增强Resnet图像分类任务的,希望大家能得到一些启发💐在文章的结尾,我也会给出一些个人实践~论文链接 。

论文研究的动机✏️。

传统的数据增强技术通过结合随机参数化图像转换来缓解数据稀缺问题,这些转换通常包括翻转、旋转和其他操作。这种数据增强方法很好地捕捉到了这种图像转换下的鲁棒性,即使是简单的变换对象,确保模型能够识别出来c;例如,可以识别正面或倒置的咖啡杯。
但是,这些基本变化是有限的,不能生成新的语义信息,例如,结构、纹理或视角的变化。例如,虽然一个模型可以识别任意旋转后的咖啡杯,但它可能很难区分不同品牌咖啡杯之间的微妙外观差异,例如,设计图案或材料纹理。我们之所以能用一个例子来区分不同品牌的咖啡杯,因为我们可以注意和记住这些微妙的视觉特征。

基于上述困境,本文的作者构建了数据增强策略——DA-fusion:使用diffusion models生成额外的训练样本,图像分类任务,这种策略需要满足以下三个性质:
一般适用性。
- :在预训练阶段,要能够生成diffusion模型没有“见过”的图片。传统的数据增强技术(例如旋转、缩放、翻转等)通常不依赖图像的具体内容,因此,有必要确保基于文本指导的图像扩散模型生成的数据增强也不受限制c;可应用于各种类型的图像数据。具体调优最小化数据集。
- :为提高实用性和易用性数据增强策略可以实现“开箱即用”(off-the-shelf),也就是说,没有必要调整或定制每个特定数据集的大量参数。这意味着模型应该有足够的通用性,能够自动适应不同数据集的特性,减少用户手动调整模型参数的工作量,从而提高工作效率和可推广性。平衡真实数据和合成数据。
- :在使用扩散模型生成额外训练样本的过程中c;追求真实数据与合成数据之间的平衡。这意味着生成的图像不仅要有多样性,学习内容丰富的模型,同时,与原始数据集的风格和特征保持一致性,避免引入噪声或误导性信息。此数据增强策略代码为:GitHub - brandontrabucco/da-fusion: Effective Data Augmentation With Diffusion Models ,有兴趣的朋友可以看看~。
作者是怎么做到的?❓。
作者参考textual inversion工作,让diffusion模型学习生成新的类别概念。
Textual inversion是一种简单有效的diffusion微调方法c;通过微调模型将新词汇添加到其文本编码器的嵌入空间中,以代表特定的视觉概念,允许模型根据用户定义的文本提示生成相应的图像,实现准确的图像定制。它的训练loss公式和stable diffusion差别不大,embedding加入了新概念c;即向量。
更新参数。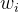 此时可能会有人问数据不能直接增强图生图吗??猫狗等常见类别c;确实可以,但是对于罕见的类别,diffusion模型可能不包含这个概念的语义信息,这就是使用textual inversion微调的原因。
此时可能会有人问数据不能直接增强图生图吗??猫狗等常见类别c;确实可以,但是对于罕见的类别,diffusion模型可能不包含这个概念的语义信息,这就是使用textual inversion微调的原因。

如下图所示,整个过程如下图所示a;
例如,我想扩展图中的“红色火车”🚄🔴这类数据,但diffusion预训练模型不包含“红色火车”的语义信息。此时�我是“红火车”(相应图中的classs 3)设置token文本编码器词典中通常不包含的单词,然后文本编码器学习“红火车”的embeddings。推理阶段输入包括“红色火车”tokenprompt,包含更丰富语义多样性的图片可以通过图生图diffusion模型生成。

为了证明自己工作的有效性,作者在三个数据集中测试了Resnet50分类任务的性能,COCOCO数据集分别为COCO、PascalVOC、作者团队贡献的Leafy Spurge🍃数据集,其中Leafy Spurge🍃该方法在少样本分类任务中的有效性,因为模型不包含这些样本的语义信息。
下图的左边是Leafy Spurge☘️数据集中样本,作者试图利用CLIP模型在大规模图像数据集中搜索“a drone image of leafy spurge",但是查询到的图片(右边)无人机视角下的图片不能给出。这也证明了leafy 大模型中不包含spurge数据集的语义信息。这也证明了leafy 这个数据集的语义信息不包含在大模型中。
实验配置🧰

论文提供了详细的实验参数供参考。初始token设置为the原因是如果你训练新概念classs x,基于一个类别不可知的token。这样,token就不会偏向于任何特定的类别特征,逐渐学习embedding#xff0c;最终能代表classs x的特征。
#x1f50d实验结果;

在这个实验中,对少样本分类进行了三组测试,每组采用不同的数据增强策略:
Baseline(基线)
- : 这是实验的对照组,不使用任何合成图像。它实施了标准的数据增强策略,包括随机旋转和平移具体参数取决于数据集。COCO和Pascal数据领域,随机水平翻转和角度+随机取样的随机旋转在15-15度之间均匀。在Spurge数据领域附加随机垂直翻转,并将随机旋转的角度范围扩大到+45到-45度。Real Guidance Baseline。
- : 基于He等人提出的方法,SDEdit技术用于真实图像。为了保证公平性�Real Guidance和DA-fusion方法共享的超参数值相等。DA-fusion。
- : 上面介绍的方法。 从上图可以看出,DA-在图像分类任务中,Fusion的表现单方面超过了Baseline,同时也比Real好 Guidance方法,证明了diffusion用于数据增强的有效性。

结论✅。
作者提出了基于扩散模型的数据增强方法,名为DA-Fusion。该方法可以通过语义修改图像来调整预训练的扩散模型c;无论图像内容如何,可生成高质量的增强数据。测试结果c;DA-Fusion提高了少量样本分类的准确性,基于Pascal和COCO的任务c;提升幅度高达+10个百分点。同样,超出diffusion预训练模型词汇范围的Leafy Spurge识别数据集c;DA-Fusion方法也提高了性能。
#x1f49000实践;
为了验证本论文中数据增强的方案是否可行,我也用textual 扩展裂缝数据集的inversion方法。在这里,我只扩展了数据集,用肉眼判断增强后的数据是否在类似原始数据集的基础上改变了内部语义信息。
裂缝图片需要增强。
在stable-difusionv1-5上,根据论文中的参数进行textual inversion微调。

由于计算能限制�我用的batchsize是1,如下效果如下a;
增强后的图片与原始数据集相似。

直接使用stable-diffusionv1-5模型图形:
直接生成的图片与原始数据集有很大的不同,也没有抓住“裂缝”的关键特征,也说明了微调的有效性。