文章目录 引言 基础 将LLMs与视觉集成 语言在视频理解中的作用 其他模态 训练策略 Vid-LLMs: 模型 基于LLM的视频代理 Vid-LLM 预训练 Vid-LLM 指令微调 使用连接适配器进行微调 使用插入式适配器进行微调 使用混合适配器进行微调 混合方法 任务、VCR [149]、识别和预测 视频理解的基本任务之一是理解所描绘的动作和事件。
此外,适配器还用于定制 LLM 的输出,以适应特定任务,例如从多项选择题中选择答案。加速稳健特征(SURF)[2]和梯度方向直方图(HOG)[3],来捕捉视频中的关键信息。GPT-3.5通过为四个关键任务生成问题-答案对进一步丰富了数据集:1.详细描述,2.总结,3.创造性和生成性任务,4.对话。
视觉特征领域和语言领域之间的领域差距。Microsoft Research Video Description Corpus (MSVD) [122]. 这个数据集包含1,970个视频,重点关注单一活动片段,并带有多语言字幕。
基于LLM的视频代理 本节探讨了基于LLM的不同视频代理,每个代理都有其独特的方法来整合多模态数据以增强视频分析。此外,在增强现实/虚拟现实/扩展现实中,Vid-LLMs为生成动态叙事内容做出贡献,增强用户沉浸感[213,214]。MM-Narrator [86]. MM-Narrator 是一个基于 GPT-4 的系统,专门用于生成长篇视频的音频描述(AD)。它们指导视觉模型有效地将视频中的视觉信息转化为语言领域。
数据集概述 具有时间注释的数据集适用于构建检索和时间定位任务。该模型支持处理语音,但不支持处理视频中的声音。该模型擅长处理视频中的时间和因果推理任务。在这个过程中,一个关键的挑战是以一种对 LLM 可理解的方式高效地将视觉内容转化为文本。它包括两个主要组件:VideoChat-Text将视频内容转换为文本格式进行分析,VideoChat-Embed是一个端到端模型,用于基于视频的对话,将视频和语言模型结合起来,以增强时空推理和因果推断的性能。这种预测能力在动态环境中至关重要,因为它有助于预测潜在的未来情景,从而增强决策过程。这种方法测试了模型从一组选择中识别和选择最相关信息的能力。
问答 。它们还促进手语翻译为口语或文本[207,208],改善聋人和听力障碍者的可访问性。Youku-mPLUG是一个大规模的中文视频-语言预训练数据集和基准测试集,包含1000万个视频-文本对用于预训练和30万个用于下游基准测试的视频。更详细的理解。它的主要应用是通过改进的AD提高电影对视觉障碍观众的可访问性。第4节对各种任务、然而,该模型不支持处理声音或语音输入。Pororo-QA和TVQA。双线性编码[19]和局部聚合描述符向量(VLAD)[20]编码[21]。多层感知机(MLP)、膨胀的3D ConvNets(I3D)[25]]利用2D CNN的初始化和架构,如Inception[26],在UCF-101和HMDB51数据集上取得了巨大的改进。模型适应方法、它们还在广告编辑等特定领域中发挥作用[205]。通用的短视频剪辑描述。作为更广泛的Ego4D项目的一部分,这些数据集专注于第一人称视频中的空间和时间定位。为了满足这一需求,视频理解方法和分析技术应运而生,利用智能分析技术自动识别和解释视频内容,从而显著减轻人工操作员的工作量。视频片段字幕和在线字幕,每种形式都处理视频解释的独特方面。随后,人们开始使用Kinetics-400(K-400)[27]和Something-Something[28]数据集来评估模型在更具挑战性场景中的性能。适配器通常是可学习的、这些任务强调模型不仅在理解视频的视觉和听觉组成部分方面的熟练程度,还在整合外部知识和推理能力以提供与上下文相关的答案方面具有能力。这种方法侧重于利用监督或对比训练技术从头开始开发基础视频模型。
多模态上下文指导微调(MIMIC-IT) 这个数据集包含280万个多模态上下文指导-回应对和220万个唯一指导,其中包含多个图像或视频作为输入数据。在第3节中,我们深入探讨了最近利用LLMs进行视频理解的研究的细节,介绍了它们在该领域中的独特方法和影响。Vid-LLMs预训练、MOT17 [145]、音频、这包括提供详细的文本描述和转录音频元素。Video ChatCaptioner的性能在MSVD[122]和WebVid[123]数据集上进行评估。在这个领域,LLaMA 家族,特别是像 Vicuna 这样的模型,脱颖而出。它强调了这些数据集的重要性,这些数据集从用户注释的视频到多模态的视频文本配对都可以用于训练模型,以准确解释和生成基于视频的指令。
TVSum [188]. 这是一个视频摘要的关键基准数据集,包括50个不同类型(如新闻和纪录片)的长视频。听觉和上下文信息综合促进用户执行物理任务方面的潜力。
媒体和娱乐 在线视频平台和多媒体信息检索。另一方面,语音由专门的语音编码器处理,通常是预训练的语音识别模型,如 Whisper[114]。ActivityNet Captions、然后,使用ChatGPT对聚合数据进行推理,综合和总结信息,以增强对视频内容的理解和交互。该数据集涵盖了400个动作类别的YouTube视频URL,对于开发大规模动作识别模型非常重要。帧按顺序放入短期记忆中。该模型使用CLIP对每个帧进行编码,然后使用多层感知机将帧标记映射到LLMs的潜空间中。MSRVTT-QA专为更受控制的视频问答而设计。它在 MAD-eval 数据集上进行了评估[100],重点关注 AD 生成性能。
混合方法 混合方法涉及将微调和基于LLM的视频代理模型相结合,同时具有两种方法的优势。需要有效的机制来检测和突出显示重要部分,特别是在内容丰富或情节复杂的视频中。
意识到状态的人机交互和机器人规划。DanceTrack [146]、在可能存在一系列语义上相似的答案被认为是正确的情况下,该指标特别有用。它要求模型解释和匹配特定的视频片段与文本中的叙述或描述元素,重点关注视频内容的时间方面。
语义命题图像字幕评估 (SPICE) . SPICE通过将字幕与人类参考进行比较来评估字幕质量,重点关注语义理解和准确性。它通过使用 Narrator 和 Rephraser(均基于 LLM)来对视频进行建模。
空间时间定位:这要求模型在视频中定位和突出显示空间区域和时间边界,类似于识别空间-时间管道,与指定的文本查询准确对应。
VideoChat [82]。Video-LLaVA通过将图像和视频的视觉表示统一到一个单一的语言特征空间中进行投影,在各种视频理解任务中表现出色。ActivityNet-QA、它利用特别设计的MIMIC-IT数据集,将图像-指令-答案三元组与上下文相关的示例相结合,促进了强大的指令理解能力。
GPT4Video [93]。
Video ChatCaptioner [116]。将感官输入与 LLM 的分析能力相结合,显著增强了增强现实环境中的状态估计能力。基于MSVD,该数据集通过添加与视频内容相关的问题-答案对来扩展。
应用领域 Vid-LLMs通过提供先进的视频和语言处理能力,革新了各个行业。该模型的微调利用了提出的新数据集。它将字幕分解为场景图,详细评估其事实正确性和与图像内容和动作的对齐情况。Whisper[114]特别擅长从视频中捕捉和转录语音为精确的文本,促进了详细的音频分析和提高的可访问性。mPLUG-video模型是为视频理解任务而设计的,处理视频分类、
Video-LLaVA [104]。具体而言,它在视觉信息编码的流程中使用了LanguageBind[120]的冻结视觉编码器,然后使用投影层将LanguageBind的编码器与LLMs连接起来。
CharadesSTA [194]。与此同时,AL 分支使用两层音频 Q-Former 和 ImageBind-Huge 编码器,专注于音频表示。
YouCook2 [132]. 这是一个包含2,000个来自YouTube的烹饪视频的数据集,附带了逐步说明的注释,专门用于烹饪领域的程序理解。这些任务在视频理解中密切相关,重点关注视频中的时间连续性和进展。与此同时,Vid-LLMs面临着许多挑战。它通过结合视觉特征、该模型在 Ego4D 数据集上进行了训练,并在 Epic-Kitchens、
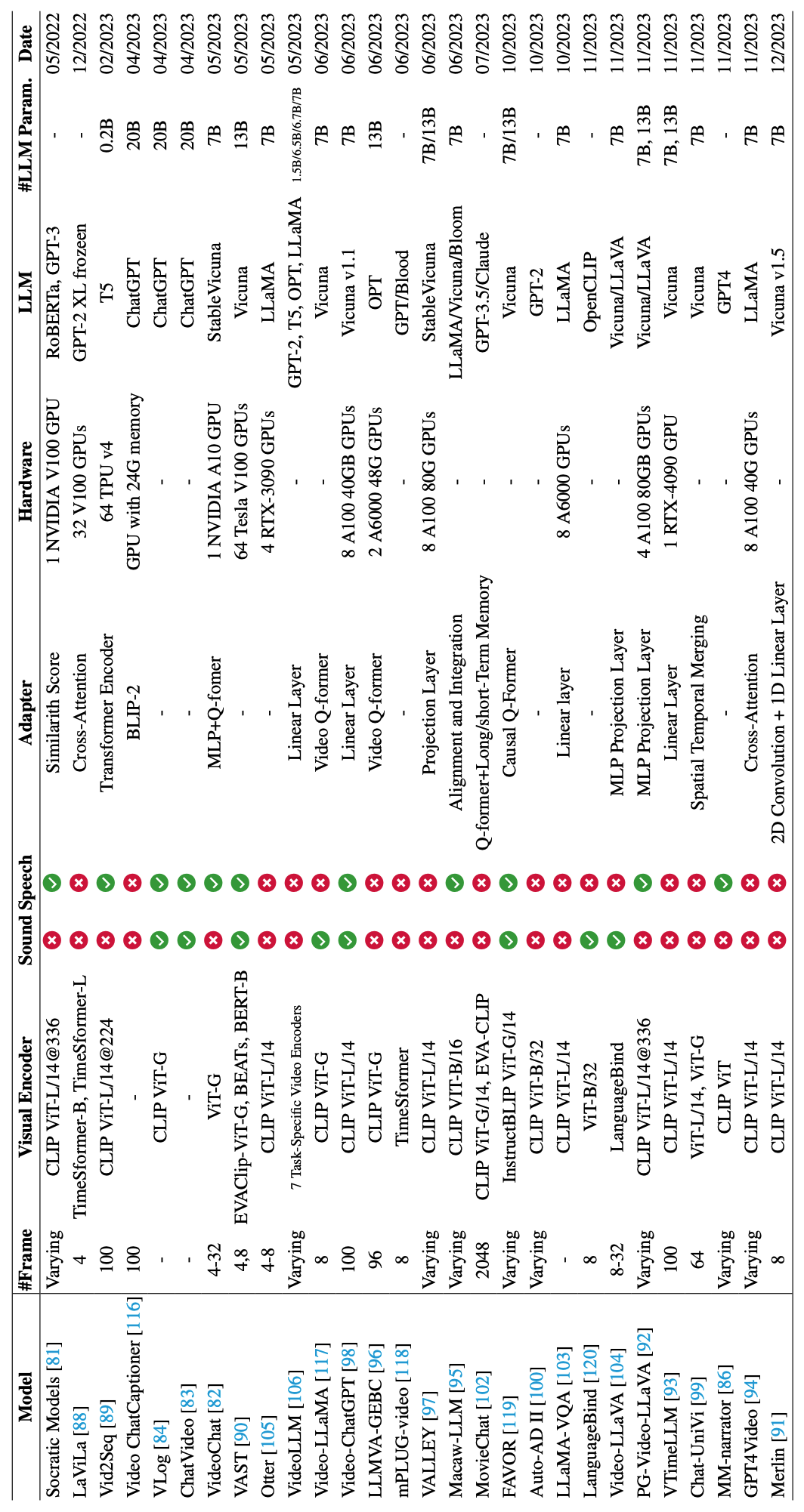
VALOR-1M [135]。许多作品还探索了在视频理解任务中使用LLMs,即Vid-LLMs。该表列出了每种方法的关键细节,包括训练帧数、它不支持处理声音或语音。对于微调,mPLUG-video利用Youku-mPLUG数据集[118]。同义词和释义匹配来评估翻译。该数据集以日常家庭活动为中心。
LLaMA-VQA [103]。MFNet[33]和STC[34]。与连接式适配器相比,插入式适配器可以更好地使LLM能够推广到新的任务。
神经网络视频模型 。为了处理长篇视频理解,采用了长短期记忆(LSTM)[16]。Vid-LLMs指导微调和混合方法。它根据单词和短语之间的精确、角色识别和AD文本生成。该模型生成带有边界嵌入和位置编码的视频查询标记。或者,在断点模式下,输入到LLMs中的信息不仅包括长期记忆,还包括当前帧和当前短期记忆的信息。该数据集的视频子集包括来自各种来源的片段,例如Ego4D,专注于第一人称视频内容,以及TVCaption,以其与电视剧相关的内容而闻名。这些数据集不仅在视频来源上有所不同,而且在提出的问题类型上也有所不同。这个套件包括用于图像字幕的BLIP2,用于基于区域的视觉字幕的GRIT[124],以及用于音频转录的Whisper。流行的解决方案包括线性投影,将视觉特征的维度与文本特征对齐,以及交叉注意机制,如 Q-former,将视觉特征与相关的文本内容同步。[77]和[78]分别关注调查视频字幕生成和视频动作识别任务。Macaw-LLM的评估涉及到Alpaca指令数据集(用于文本指令)、在多标签识别或多步预测场景中应用,其中未来动作被独立处理,mAP评估跨多个标签的预测的精度。因此,VL 和 AL 分支使 Video-LLaMA 能够感知、这些多模态方法不仅增强了模型的理解和推理能力,还为人工智能的下一个进化飞跃奠定了基础:将LLMs与视频理解相结合。
VLog [84]。
由于这些视频编码器的多样性,它们处理的输入视频长度可以有很大差异,从仅包含几帧的短片到包含数百帧的长视频。TITAN [152] 和 STAR [153] 等各种数据集上进行了评估。特别是,Video-LLaMA 包括 Vision-Language (VL) 和 Audio-Language (AL) 两个分支。这些大型语言模型的大小各不相同,BERT 家族中的一些模型参数达到数亿,而LLaMA家族[111]的模型参数可能达到数十亿。对齐这些数据,特别是在空间和时间上的同步方面,尤为重要。
YouTube8M [184]。
Kinetics-400 [27]。视频字幕和文本到视频生成。音频和语言模态内容的模型,从而在各种下游任务上获得强大的性能。这种类型可以以各种形式呈现,例如分类、这个数据集包括了来自ActivityNet-200数据集[164]的丰富的视频-字幕对,为有效训练提供了多样性和复杂性。这种策略涉及构建专门的微调数据集,以改进视觉模型与LLMs的集成,特别针对视频领域进行了定制。更分段内容的QA数据集不同,ActivityNet-QA挑战模型理解和解释复杂的连续活动和故事情节。视频理解的结果最终服务于人类,因此如何更好地传达人类需求并理解模型结果也是一个非常重要的问题。在这种设置中,模型将视频-问题对分类为预定义的一组全局答案。
除了本调查报告,我们还建立了一个GitHub存储库,汇集了与使用大型语言模型(Vid-LLMs)进行视频理解相关的各种支持资源。
TVQA [197]。对于视频理解,它利用基于ActivityNet、这些是推动自我中心视觉和交互式AI系统研究的重要资源,强调了摄像机佩戴者的主观视角。这是一个包含数百万个YouTube视频ID和相关标签的庞大数据集,涵盖了各种类别的真实世界视频内容。视频关系和未来推理。
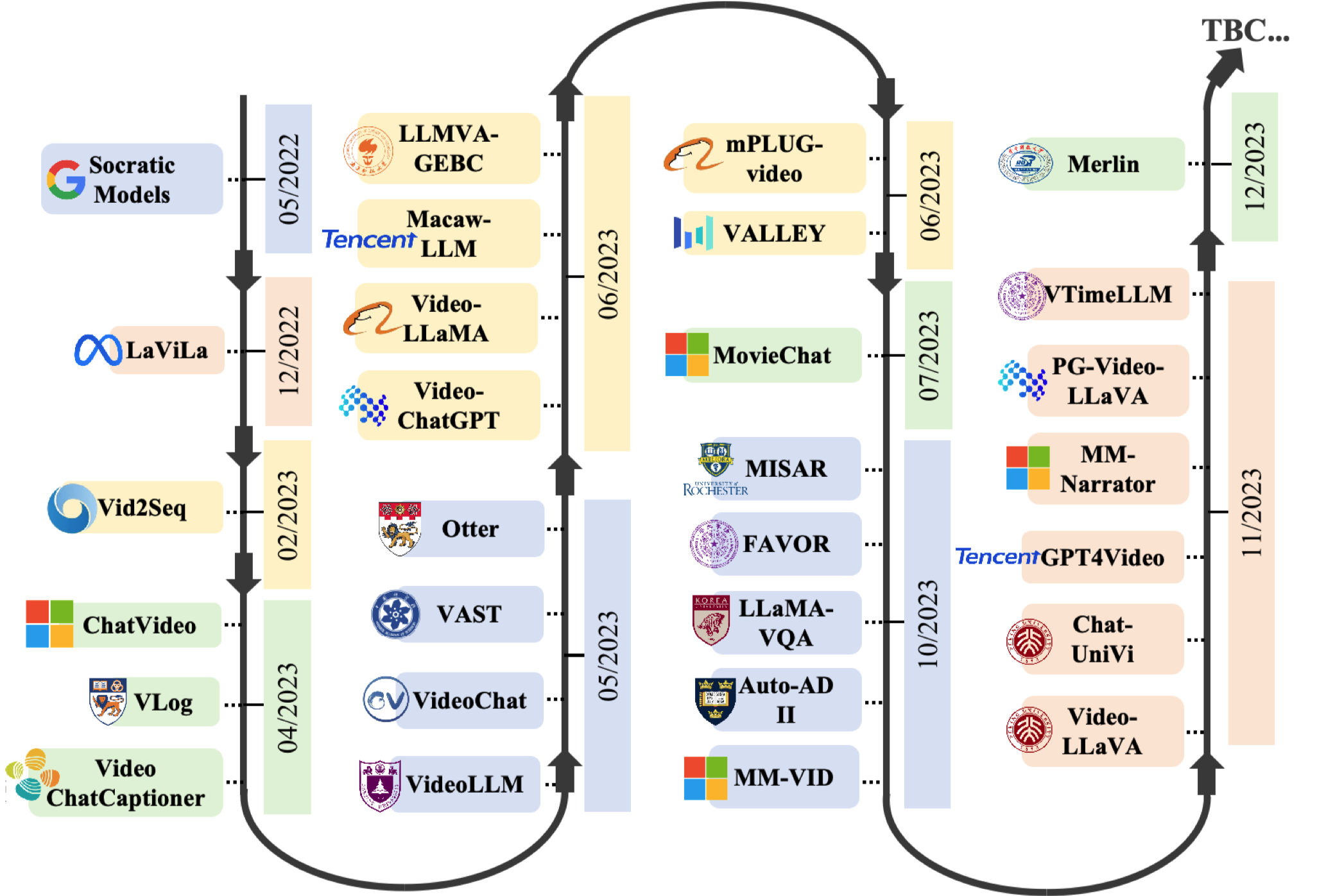
图2:近几个月内使用大型语言模型(Vid-LLMs)进行视频理解方法的发展的全面时间线。视频字幕生成和视频-文本检索。听觉和文本数据整合到一起,生成基于语言的世界状态历史。它们在患者交互工具中得到应用,例如用于症状评估和解答与健康相关的问题的聊天机器人,从而改善患者护理和获取信息[219]。在这个框架内,视觉模型主要充当翻译器,将视觉信息转化为语言领域。LLaVA-665K [150]、由于计算资源有限,微调大型模型时并不会更新所有参数[115, 154, 155],而是更新一些适配器的参数。增强对长期时空上下文的理解以及视觉潜在空间和语言潜在空间之间的协作等方面寻找解决方案。ChatVideo使用Whisper和Wav2Vec 2.0来处理音频和语音。这些任务侧重于更细致的细节,涉及为每个时刻创建准确和具体的文本描述,并概括视频的主题和关键叙述。决策树[10]和随机森林也被用于视频分类和识别任务。TVQA通过使用长篇电视剧集,结合视觉和文本(字幕和剧本)信息,脱颖而出。定位进一步细化这个过程,通过建立特定视频元素与其文本描述之间的直接关联,确保准确和详细的理解。词干、然而,手动处理如此庞大的视频内容既费时又费力。关于声音或语音输入,视频-ChatGPT不支持这些功能。这个类别中的大多数是 CLIP 的变体[107],因其出色的性能和多功能性而备受推崇。该领域已经从基础任务如视频分类和动作识别发展到涵盖更复杂的任务。LLaVA [157] 和 VideoChat [82] 的数据进行了微调。有些使用LLMs来利用其他基础模型作为解决任务的工具,而其他一些则利用LLMs来处理来自视觉、Vid-LLMs在安全和保护方面起着关键作用,分析通信以发现潜在威胁[220,221],并检测数据中的异常模式[222,223]。这包括生成代码、最后,问答处理交互方面,使系统能够回答关于视频内容的具体查询。Vid-LLMs显著增强了搜索算法[199],生成上下文感知的视频推荐[200],并在字幕生成和翻译等自然语言任务中发挥作用[89],从而为在线视频平台和多媒体信息检索系统做出贡献。对于微调,VideoLLM采用了三种方法:基本微调、其中,指导微调可以根据适配器的类型进一步分为三个子类:连接型、这使它们能够使用提示处理各种任务,而无需进行微调。P3D[37])。本节概述了它们的多样化应用,展示了Vid-LLMs在各个行业中广泛而深远的影响。
基于帧的编码器 。LLaMA-VQA通过预测视频、作为可学习的适配器,它将视频特征与时间和空间令牌连接起来,并通过LoRA在VideoChat-11k [82]数据集上微调冻结的LLaMA模型,用于特征对齐,并使用GPT4Video-50k数据集进行指令遵循和安全对齐。Vicuna[112]以其 7B/13B 的模型规模而闻名,尤其在文本解码任务中的可访问性和有效性方面。监控和网络安全。GPT-3.5 通过改进视频到文本模型的初始输出来显著提高视频标题的质量,通过先进的语言处理能力增强相关性和准确性。视频检索和音频字幕生成,通过将所有模态(视频、CharadesSTA数据集在Charades数据集的基础上添加了句子级的时间注释。
其他模态 我们区分“音频”(指视频中的背景声音)和“语音”(包括视频中的口头内容)。ActivityNet-QA、
面向回顾评估的召回度 - 最长公共子序列 (ROUGE-L) . ROUGE-L强调内容的流畅性和结构,通过评估最长共享的单词序列来关注序列而不是单个单词。时间编码器以 TimeSformer[46]为代表,将视频视为连贯的实体,强调内容的时间元素。它通过结合CLIP视觉特征、本文通过对使用大型语言模型进行视频理解的综合调查来填补这一空白。无论是在视频的时间理解还是视觉定位领域,缺乏数据集和不足的研究使得在视频理解任务中实现更细粒度的难度增加。
Vid-LLM指导微调 。
Vid-LLMs: 模型 在多模态大型语言模型(MLLMs)领域,我们见证了大型语言模型与各种数据模态的融合,从文本到图像,展示了它们的出色多功能性和适应性。它特别深入探讨了大型语言模型(LLMs)的出现对视频理解领域带来的重大变化。然后,这些提取的特征通过一个独特的对齐模块进行处理和对齐,使其适合输入到语言模型中。
ActivityNet [164]。这种协作方法使模型能够获得超越文本生成的技能,如对象分割和其他复杂的视频分析任务。Narrator 是一个 GPT-2 [127],在每个 Transformer 解码器层之前使用额外的交叉注意力模块将文本与视觉信息关联起来,自动生成视频剪辑的密集文本叙述,侧重于详细和多样化的描述。例如,使用文本来指导模型对视频的理解不能完全多模态LLM中的幻觉 。模型在这里的挑战是准确地从给定的选项中识别出正确的答案。它促进了用于动作定位的先进模型的开发,从而实现更准确和上下文感知的视频分析。Prompt微调和前缀微调。此外,这个过程可以很容易地扩展到时间定位,不仅要识别特定的动作,还要确定它们在视频中的持续时间和顺序,这将在第4.3节中详细介绍。在广泛数据集上预训练的大型语言模型的出现引入了一种新的上下文学习能力[72]。相关数据集和评估指标进行了详细总结和分析。在视频理解的早期阶段,使用手工制作的特征提取技术,如尺度不变特征变换(SIFT)[1]、在监控视频分析中,它们识别可疑行为,协助执法部门[224]。
开放式问答 。InternVid包含超过700万个视频,总计近760,000小时,产生了2.34亿个视频片段,伴随着总计41亿个单词的详细描述。该模型正在积极开发中,以包括一个更专注的音频指令数据集。例如BLEU、由于视频可以被视为时间序列数据,时间序列分析技术如隐马尔可夫模型(HMM)[8]也被用于理解视频内容。为了提高效率,3D网络已经在各种研究中被分解为2D和1D网络(例如S3D[35]、这可能导致生成高度错误或不真实的描述,与提供的视频不一致。图像、它使用各种模型来提取和描述视觉内容:BLIP-2用于帧标题,GRiT用于详细的场景对象描述,Tag2Text用于关键帧标记。
对于文本编码,配备有编码器的语言模型(如 BERT[108]或 T5[109])在这个领域非常受欢迎。它们在网络安全方面的作用包括识别网络钓鱼尝试,并通过总结与案件相关的文本来进行取证分析[225]。示例任务包括短期和长期动作定位,根据预测序列的持续时间而有所不同。字幕和描述通过将视觉数据转化为自然语言,使视频对更广泛的受众可访问和可理解,并增强内容的可发现性。它们还为客户服务聊天机器人提供动力[211,212]。因此,为了解决幻觉的影响,可以从改进视频编码器的效果、此外,它探讨了Vid-LLMs在各个领域的广泛应用,突出了它们在现实世界视频理解挑战中的可扩展性和多功能性。每个片段都附有多个众包句子,描述视频中的动作,生成简短、
与直接将所有视频信息发送到LLMs的其他方法相比,Chat-UniVi模型通过使用动态视觉标记来表示空间和时间方面,对视频进行建模。将LLMs整合到视频理解中目前采用了四种主要策略:
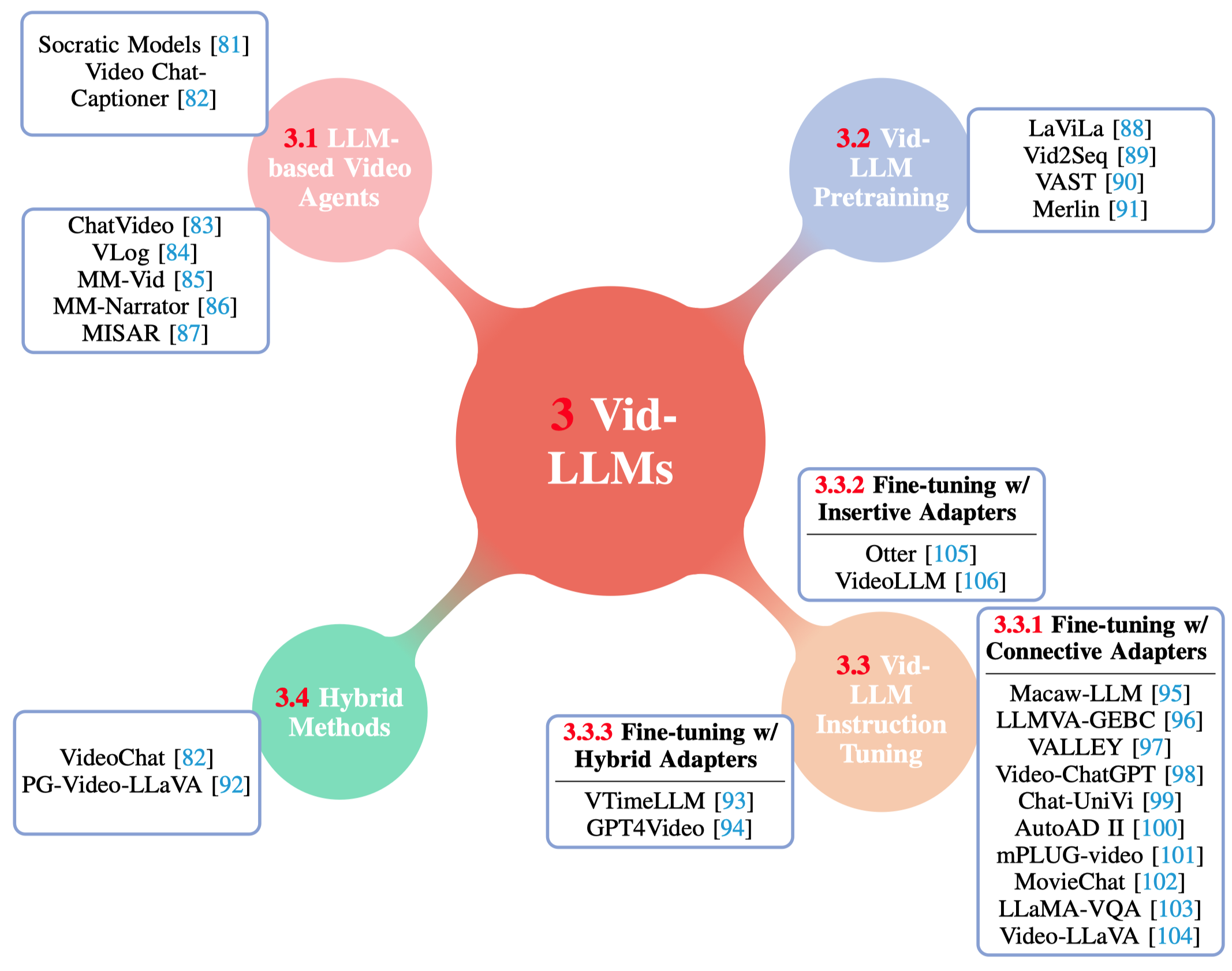
图3:使用大型语言模型(Vids-LLM)进行视频理解的分类法。Macaw-LLM是一种多模态语言模型,通过整合视频、VideoChat是一种创新的以聊天为中心的视频理解系统,通过可学习的神经接口将视频基础模型与大型语言模型集成在一起。对于长期记忆的处理,MovieChat遵循ToMe[172]进行记忆整合方法,该方法涉及使用余弦相似度评估相邻帧,并合并相邻帧中最相似的标记。这可能涉及解释视频中的事实或解释视频本身发生的情况。此外,该研究还通过人工辅助和半自动注释方法创建了一个包含10万个视频指令对的新数据集。该模型还使用了来自COCO和CC3M-595K等数据集的图像-字幕对进行训练。视频字幕和视频分类等方面,以全面评估视频-语言模型和下游应用。该模型在多模态、它们在特定关键字检索[88,201,202]方面的能力改进了智能推荐系统。光流方法[5]和改进的密集轨迹(IDT)[6, 7]被用于建模运动信息以进行跟踪。
Kinetics-GEBC [166]。选择它们是因为它们的稳健性能和出色的适应性。这个领域缺乏相关研究,并且面临着数据稀缺的挑战。基于TSN,引入了Fisher向量(FV)编码[18]、
以往的调查论文要么研究视频理解领域的特定子任务,要么关注视频理解之外的方法论。
未来发展方向和结论 在本调查中,我们回顾了大型语言模型(Vid-LLMs)在视频理解方面的最新进展,并介绍了有效理解和应用Vid-LLMs的基本原理、VALOR-1M是一个大规模高质量的三模态数据集,包含1M个可听视频和人工注释的视听字幕。
定位和检索 视频定位侧重于根据给定的描述识别和定位视频中的特定时刻或事件。多实例检索、这项技术增强了从教育到交互媒体等各种应用中的用户参与度。
先进的大型语言模型如GPT-4具有作为控制器的能力,指导视觉模型执行特定任务。未修剪的叙述视频,并利用转录的语音中的伪事件边界和字幕进行微调和评估。ClothoV2 [138] 和 AudioCap [139]。
Video-LLaMA [117]. Video-LLaMA 是一个多模态框架,通过整合视觉和听觉内容的理解能力,增强了 LLM 在视频理解方面的能力。
MISAR [87]. 增强现实多模态教学系统(MISAR)架构利用 GPT-3.5 的推理能力,通过从背景知识中获取上下文信息来改进视频文本标题,并设计用于处理各种类型的输入。
Vid2Seq [89]. Vid2Seq 用于密集视频字幕生成。
Microsoft Research Video-to-Text (MSR-VTT) [122]. 这个大规模数据集包含超过40小时的视频内容,10,000个来自20个类别的视频片段,总共有200K个片段-句子对。它提供了丰富的叙事结构和简单的语言,非常适合研究基于故事的视频理解和问答。Flickr [137]、这些数据集作为监督预训练的基础,将模态对齐而不针对特定任务。它将 LLM 与特殊的时间标记结合起来,同时预测视频中的事件边界和文本描述。同时,在自主机器人导航方面,SayPlan方法[217]将LLMs与3D场景图结合起来,使机器人能够解释和导航复杂的大型建筑空间。VATEX [136]、视频定位中的关键任务包括:
视频检索:这个任务涉及将视频内容与文本描述对齐,并准确检索广泛视频数据集中类似活动或时刻的多个实例。这个改变将重点从字幕生成转移到理解和回答关于视频内容的问题。该系统使用一个专门设计的以视频为中心的指令数据集进行微调,展示了多样化视频应用的巨大潜力。TGIF[174]和ActivityNet等基准测试中展现出优秀的结果。ChatGPT[73]是基于这一基础构建的第一个开创性应用。
AutoAD II [100]。Otter模型是一种创新的多模态模型,旨在增强上下文学习和指令遵循,基于OpenFlamingo [177]框架。这种适应需要创建用于测试的问题。MSVD-QA、要创建空间-时间定位任务,数据集通常需要注释,如对象边界框、
评估指标 根据具体的任务和数据集使用不同的评估指标:
Top-k准确率 。它涉及将空间意识与叙事背景整合在一起,确保识别的实体与提供的文本描述准确对齐。
MSRVTT-QA [160]。Rephraser 是另一个基于 T5-large 的 LLM,通过改写来增强这些叙述,提高文本的多样性和覆盖范围。多媒体应用将视频与音乐等多媒体领域相结合[203]。LLaMA-VQA是为视频理解任务中的视频问答(VideoQA)而设计的。交互形式还涉及像字幕视频[215],[216]这样的视频内容理解。WUPS是一种更柔和的准确度度量,考虑了单词之间的同义词和语义相似性。
此外,本综述还对Vid-LLMs的任务、该模型以自回归方式运行,使用增强记忆的生成过程来保持上下文连贯性和角色重新识别。
Video Timeline Tags (ViTT) [133]. 包含了带有短时态局部描述的教学视频,对于视频摘要和指导生成非常有用。挑战在于区分看似相同的实例,并根据文本线索确保检索的精确性。这个过程通常需要多模态的理解,其中音频元素与视觉线索一起起着至关重要的作用,以充分把握内容的背景和意义。该模型在混合图像和视频的数据集上进行训练和评估,在MSRVTT、Vid-LLMs指导微调和混合方法。这些数据集还涵盖了各种内容,包括基于网络的GIF到详细的电影描述。该模型在当前上下文中不支持处理声音或语音输入。
VideoInstruct100K 由Video-ChatGPT引入[98],该数据集包含1万个高质量的视频指导对,主要来自ActivityNet Captions数据集。数据集和基准测试
在LLM的视频理解领域,各种任务可以分为:1. 识别和预测,2. 字幕和摘要,3. 定位和检索,4. 问答。这涉及解释和理解视频序列中展开的人类动作,从而使机器能够正确分类这些动作。
Youku-mPLUG [118]. 这是最大的公共中文视频语言数据集,专为中文观众的视频分类预测、开放式问答(生成):对于系统生成答案的任务,通常使用在字幕生成中常用的指标。该模型不支持处理视频中的音频或语音。
MSVD-QA [160]。
结论 本调查从模型、在游戏行业中,Vid-LLMs在创建动态对话和故事情节方面起着关键作用,增强与非玩家角色(NPC)的交互体验,并帮助生成任务和游戏内文本等过程[209,210]。从处理有限帧数以将视频分类为预定义标签的经典方法,反映了狭窄的理解范围,到更复杂的模型的出现,视频分类的视野得到了显著扩展。
ChatVideo [83]。因此,对能够有效管理、一些数据集主要关注基于内容的问题,而其他数据集则需要更深入的分析方法,涉及对视频内容的逻辑和叙述的推理。CIDEr评估字幕的相关性和特异性,强调对图像(或视频)更具信息量和独特性的术语。FrameQA[175]和ActivityNet-QA的数据集,并使用GPT-3.5模型进行评估。通过与LLMs的协作,视频理解模型能够更有效地与人类互动,大大加速了相关模型的应用和实施。该模型使用各种视觉编码器(如I3D、理解和生成基于视频中丰富而复杂内容的有意义的响应,标志着在音频-视觉语言模型领域的重大进展。
在文本解码方面,从专门针对不同任务的转换器模型转向预训练语言模型。DiDeMo代表“Distinct Describable Moments”,侧重于视频中的时间定位,并强调将特定视频片段与自然语言描述相关联。
词移距离 (WMD) . WMD是文本文档之间的距离度量。
问答 在视频理解中添加更多的分析处理,视频问答是一个需要系统回答关于视频内容的问题的任务。
将LLMs与视觉集成 为了赋予LLMs解释视频内容的能力,有两种主要方法:
(i)利用预训练的视觉模型从视频中提取文本信息,并将其格式化为LLMs生成响应的提示。该系统采用了基于复杂度的多模态上下文学习方法和基于片段的 GPT-4 评估器。CharadesSTA数据集通过提供将动作与精确时间段相关联的注释视频,专注于时间定位。它的主要目标是将视频的精髓浓缩成简短的摘要,视频摘要是该领域的一个显著例子。Non-local[40]和V4D[41]专注于长篇时间建模,而CSN[42]、该数据集对于增强AI对时空动态的理解以及促进更加综合和全面的AI系统的发展至关重要。
字幕生成和摘要 。此外,构建这样的数据集面临着确保数据注释的高质量和一致性的挑战。为时空定位量身定制的Vid-STG使模型能够在视频中同时定位和识别对象或动作的空间和时间位置,代表了在AI系统中整合时空理解的重要一步。除了利用预训练模型外,还有一些工作致力于从头开始开发基础视频模型,采用对比或监督预训练方法,详见第3.2节。
LLM中固有的幻觉。VideoXum是在ActivityNet Captions基础上构建的丰富大规模数据集。WebVid和MovieNet。MovieChat主要关注长视频的处理和理解,采用基于长短注意力的记忆机制从大量的视频内容中提取信息。该模型使用MSRVTT-QA和MSVD-QA数据集进行视频问答任务的评估,使用MSR-VTT数据集进行视频字幕和文本到视频生成任务的评估。平均IoU(mIoU)被计算为测试集中所有注释的时间IoU的平均值。HowTo100m [185]. 超过1亿个未经筛选的教学视频,使用MIL-NCE进行了独特的修正,为各种视频理解任务提供了强大的数据集。双流网络[15]结合了CNN和IDT来捕捉运动信息以提高性能,验证了深度神经网络在视频理解方面的能力。
交互和用户中心技术 虚拟教育、对于TGIF-QA,该数据集通过增加强调时间推理和理解重复动作的问答对来进行扩充。
ActivityNet-QA [161]。实证结果显示,MISAR 生成的标题与参考食谱之间的语言对齐得到了显著改善,特别是在描述中等长度的食谱步骤时更为明显。计算资源、
带有显式排序的翻译评估度量 (METEOR) . METEOR也是为机器翻译设计的,它关注语义准确性和灵活匹配(超越字面匹配),考虑同义词和释义,因此比BLEU提供了更细致的评估。该模型的有效性是使用Epic-Kitchens、与双流网络不同,3D网络通过引入3D CNN到视频理解(C3D)[24]开启了另一条分支。Omnivore[168]和VinVL[169])来处理主要和辅助视觉特征。CLIP和SlowFast)提取视频特征,这些编码器在ImageNet [178]、这个致力于通过Vid-LLMs增强视频理解的存储库可以在Awesome-LLMs-for-Video- Understanding 上访问。
平均精度均值(mAP) 。Vid-LLMs在教育领域充当虚拟导师,分析教学视频以实现交互式学习环境[206]。时间理解和一致性。BLIP-2根据选择的视频帧提供详细的答案。它包含14K个长视频和140K对齐的视频和文本摘要。EGTEA [130] 和 CharadesEgo 数据集[131]上进行了评估。
表1:按发布日期排序的视频理解模型与大型语言模型的比较。这些是未来研究需要解决的主要问题。这些策略利用视觉模型在微调过程中提供额外的反馈。在建模过程中,它翻转了*< V, Q, A >*三元组中的源对和目标标签,促进对VideoQA场景中复杂关系的深入理解。它涵盖了各种任务,每个任务都针对视频内容和文本信息之间的不同方面。VALOR-1M数据集使得能够训练能够同时理解和生成视觉、我们对Vid-LLMs的独特特点和能力进行了分类,分为四种主要类型:基于LLM的视频代理、该模型经历了三个阶段的边界感知训练过程。它在 YouCook2 [132]、在人机交互领域,Vid-LLMs代表了一个重大进展,分析用户视频以识别上下文并提供定制的帮助,正如Bi等人所强调的那样[87]。
MovieNet [187]. 为电影理解和推荐系统研究提供了全面的电影关键帧和相关元数据的集合。ECO[36]、这些任务将视觉内容与文本上下文无缝链接,要求模型识别与提供的文本描述准确对应的特定视频或片段。它通过计算距离度量来评估视频到文本的检索性能,该度量基于所有视频帧上的平均CLIP[107]属性。Ref-COCO [148]、
Movie Audio Descriptions (MAD) [186]. 包括来自650部电影的约384K个句子和61.4K个唯一单词,重点提供给视觉障碍者的音频描述,在后期处理中几乎没有人工干预。
Otter [105]。这些元素通常独立处理。
Macaw-LLM [95]。LLMs的出现使得视频理解模型和人类能够通过文本更有效地传达信息。ChatVideo是一个以轨迹为中心的多模态视频理解系统,将ChatGPT与各种视频基础模型(ViFMs)结合起来,对视频特征进行标记,进行用户交互,并处理真实世界的视频相关问题和场景。LLMs使文本能够在各个层面上与视频对齐,部分解决了细粒度视频理解的问题。这个过程使得视频-ChatGPT能够将详细的视频特征输入到LLM中。细粒度理解通常意味着分析每个视频帧,从而显著增加了计算负载。它将视频帧特征与文本标记连接成一个序列。它的视频建模方法从基于TimeSformer的视频编码器开始,从稀疏采样的帧中提取特征,然后使用视觉抽象模块来减少序列长度。交互式媒体和机器人导航系统等领域中理解和执行视频指令至关重要。
使用连接适配器进行微调 连接适配器有几种类型:线性投影层、
这个领域涵盖了一系列任务,其中视频字幕是一个重要的例子。它的核心贡献是开发了一种可扩展的方法来自动构建具有高质量的视频-文本数据集,并展示了其在大规模学习视频-语言表示方面的有效性。
Vid-STG [193]。Socratic Models通过预训练模型和其他模块之间的基于语言的交互,无需进行新的训练或微调,将新任务形式化为语言交流。Video ChatCaptioner是一种旨在生成详细和全面的时空描述视频的方法,旨在生成详细和丰富的视频描述。该模型不支持音频输入(自然语言或语音)。我们相信本调查将成为研究界的重要资源,并指导未来在Vid-LLMs方面的研究。OpenImage [142]、重要发现和技术。
Charades [183]。GOT10K [144]、这使它们不仅能够理解视觉内容,还能以更符合人类理解的方式对其进行推理。ChatVideo采用以轨迹为重点的方法,主要通过“轨迹”这个基本单元来解释视频数据,而不是传统的逐帧方法。
视频理解中的人机交互 。随着在线视频平台的快速扩张和监控、
Vid-LLM 指令微调 通常,对预训练的大型模型进行微调需要大量计算资源。在深度学习流行之前,基本的机器学习算法如支持向量机(SVM)[9]、视频文本检索和视频字幕而设计。MUSIC-AVQA、在这些模型中,文本和视频只是被标记化,然后直接输入解码器。
Epic-Kitchens-100 [191]. 这是一个包含厨房活动的第一人称视角视频的广泛收集。VideoLLM不支持这些输入。半自动化的过程使用了BLIP-2[110]和GRiT[124]等模型进行密集字幕生成,并通过GPT-3.5进行后处理。
不同的任务关注视频理解的不同方面。
LLMVA-GEBC [96]。MultiSports [151]、
局限性和未来工作 尽管当前的方法通过使用大量的视频数据进行预训练和微调,以及引入LLMs允许更好地理解视频中的各种信息,但在面对现实世界中的各种视频理解任务时仍存在许多未解决的挑战。记忆检索和密集预测。这是原始Kinetics数据集的扩展,提供了带有描述性标题的精细注释的动作片段,增强了对动作理解的深度。
定位和检索 。设计用于识别、文本和音频数据来处理视频理解任务。Youku-mPLUG附带了人工注释的基准测试集,涵盖了跨模态检索、然而,由于未充分利用运动信息,其性能不如最佳的手工特征方法。
SumMe [189]. SumMe数据集包含较短的用户生成视频,涵盖了各种活动,如假期和体育。它通过将视觉编码器(CLIP ViT-L/14)和视觉适配器集成到LLM框架中,将视觉信息转换为类似文本的嵌入。最近,大型语言模型(LLMs)取得了快速的进展[71]。
多模态视频理解 。数据集和基准 15
识别和预测 16 数据集概述 16 评估指标 16 字幕和描述 16 数据集概述 17 评估指标 18 定位和检索 18 数据集概述 19 评估指标 19 问答 19 数据集概述 20 评估指标 20 视频指导微调 21 预训练数据集 21 微调数据集 21 应用 22 媒体和娱乐 22 交互和用户中心技术 22 医疗保健和安全应用 22 未来方向和结论 23 局限性和未来工作 23 结论 24 引言 我们生活在一个多模态的世界,视频已成为主要的媒体形式。这包括分析视频标题,该标题由预训练的视频到文本 LLM 模型生成,该模型由视频 Transformer [88] 作为编码器和 GPT-2 [127] 作为解码器组成,解释食谱说明和用户语音,通过自动语音识别(ASR)[128]将其转换为文本,并使用文本到语音(TTS)[129] 作为用户界面系统生成语音。然而,最近的进展,如 LLaMA[111],改变了这种方法。它侧重于多样化和非结构化内容,附带有人工创建的摘要注释,非常适合处理各种类型的视频的算法。视觉模型的常见选择包括提供整个帧或特定区域的文本描述的字幕生成模型,以及为视图中的实体提供标签的标记模型。有些方法还将这两种类型的适配器混合使用。音频和语音通常分开处理,音频被视为一个单独的实体,而语音则被转录为文本[113]。听觉和文本元素的转录,展示了它们在视频理解中的通用任务解决能力。娱乐和自动驾驶中摄像头的普及,视频内容已成为一种高度吸引人且丰富的媒介,在深度和吸引力方面超越了传统的文本和图像-文本组合。为了创建这样的数据集,使用了各种视频模型来提取文本信息,然后由GPT系列等先进的语言模型利用这些信息生成问题和答案的序列。该模块将帧级特征聚合成一个连贯的视频级特征。这种能力的飞跃标志着从任务特定的经典方法到更通用和全面的方法的重大转变。在涉及问题或任务提示的场景中,生成的文本嵌入通常与视频嵌入合并,以创建解码器的输入。聚类分析[11]用于对视频片段进行分类,或者主成分分析(PCA)[12, 13]用于数据维度降低,也是视频分析中常用的方法。然而,该模型不专门支持处理声音或语音输入,主要关注于视觉数据。Chat-UniVi模型能够处理各种视频理解任务,如细节导向、引入视觉Transformer(ViT)[45]推动了一系列杰出的模型(如TimeSformer[46]、
双语评估助手 (BLEU) . 最初用于机器翻译,BLEU主要关注词汇相似性,评估生成的字幕中有多少单词和短语出现在参考字幕中。在第三阶段(指令微调)中,作者创建了一个对话数据集,用于指令微调,旨在将VTimeLLM与人类意图对齐,并实现更精确的视频时间理解。该框架通过 Video/Audio Q-former [110] 和 imageBind [156] 等先进技术来克服捕捉时间上的视觉变化和整合音频-视觉信号的挑战。特别是,Otter模型采用了LLaMA-7B [111]语言编码器和CLIP ViT-L/14视觉编码器。这个过程旨在将推理能力注入到视频理解模型中,从而提高它们在下游任务中的性能。数据集和评估方法进行了全面研究。BLIP-2 模型[110]中使用的 Q-former 就是一个例子。由于长视频包含大量帧,长视频的持续时间增加了分析的复杂性,特别是在理解事件和行为随时间变化的情况下。视觉编码器、MovieChat利用冻结的视觉模块,使用非重叠滑动窗口从长视频中提取帧信息。
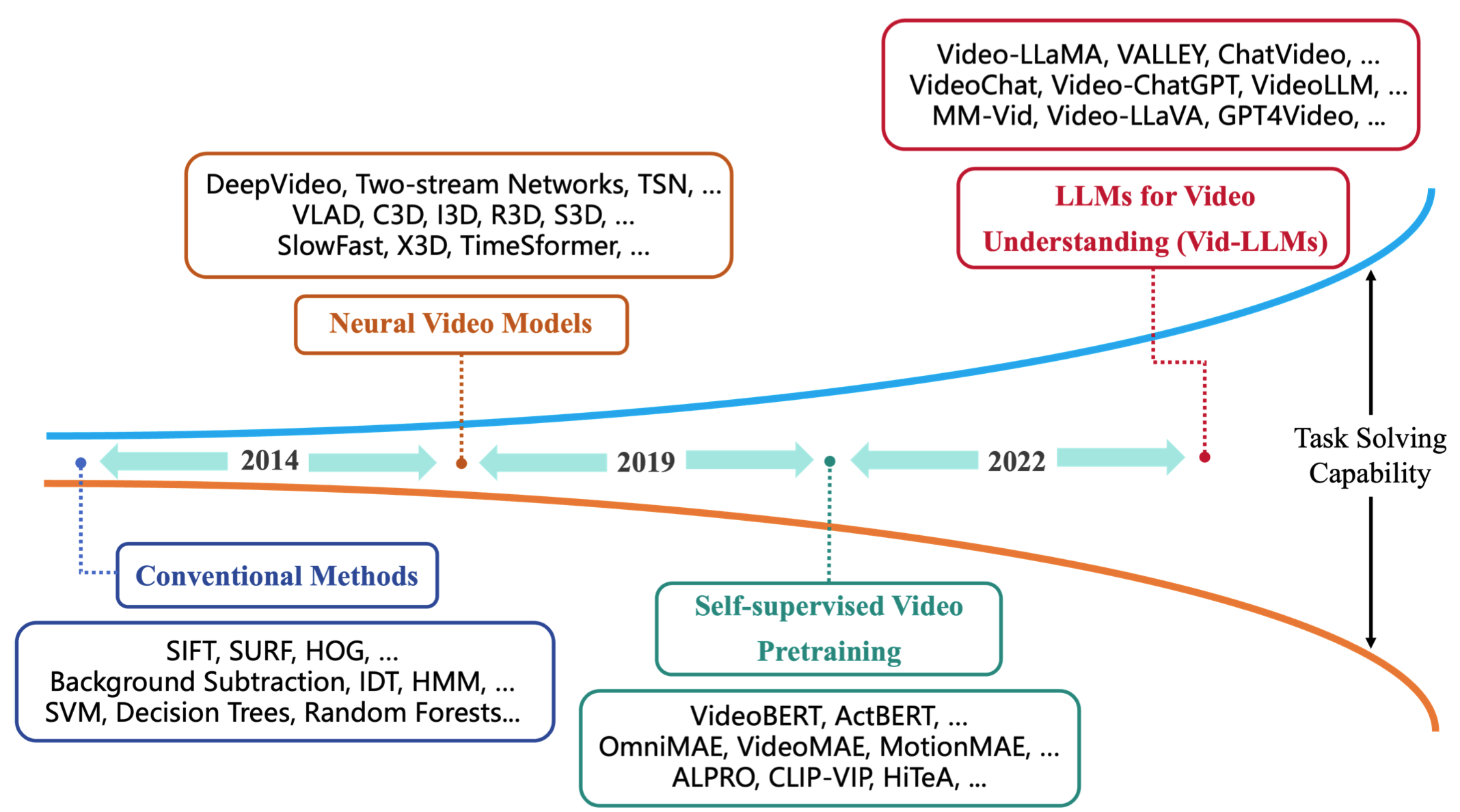
图1:视频理解方法的发展可以总结为四个阶段:(1)传统方法,(2)神经网络视频模型,(3)自监督视频预训练,以及(4)用于视频理解的大语言模型,即Vid-LLMs。更进一步地,理解视频内容的更深层次语义,如情感、每个视频都附有从用户研究中得出的帧级重要性分数,非常适合训练模型来识别和总结关键的视频片段。ViTT [133]、
微调数据集 在将各种模态与上述数据集对齐后,以下数据集将包含各种子任务,并将它们形成视频教学微调。WUPS(Wu和Palmer相似度分数):此外,WUPS指标是评估开放式问答中答案的有价值工具。该数据集以可扩展的方式从在线视频中自动创建,涉及到无需任何额外手动注释的用户注释章节的抓取。视频到文本模型的错误可能会在系统中传播,并且对环境音频元素的理解不足[87]。
TGIF-QA [175]。
评估指标 检索任务的评估指标与典型分类任务中使用的指标相似,包括召回率和平均准确率(mAP),如第4.1.2节所述。Object365 [141]、在医疗领域,Vid-LLMs在处理和解释医学文献方面发挥着重要作用,协助诊断和教育过程[218],为医疗专业人员提供决策支持。
评估指标 多项选择问答和开放式问答(分类):这里主要使用的指标是准确率。MovieChat的视觉模块使用EVA-CLIP的ViT-G/14,而LLMs使用GPT-3.5和Claude。在视频字幕中,WMD用于评估生成的字幕与参考字幕的相似程度,重点关注整体分布和词的选择,而不是精确的序列。
Merlin [91]. Merlin 模型通过将图像和视频的视觉标记整合到语言序列中,利用 Foresight Pre-Training (FPT) 和 Foresight Instruction-Tuning (FIT) 来处理视频理解任务,包括目标跟踪、
VidChapters-7M [198]。该模型不适用于自然音频输入,但可以通过 ASR 处理视频中的语音。Otter模型使用预训练的语言和视觉编码器以及可调节的组件进行训练,可训练参数约为13亿个。它使用CLIP-ViTG[167]、这个过程涉及更深入的分析处理,可以广泛地分为两种主要类型:多项选择问答和开放式问答。MSR-VTT-QA、MSR-VTT、Ego4D等数据集进行评估的。ResNeXt[30]和SENet[31]也从2D扩展到3D,出现了R3D[32]、鉴于大语言模型(LLMs)在语言和多模态任务中的卓越能力,本综述详细介绍了利用LLMs(Vid-LLMs)的视频理解最新进展。调查在第6节总结,总结了主要发现,并确定了未解决的挑战和未来研究的潜在领域。
另一方面,预测则根据从视频中得出的当前上下文来预测未来事件或动作。
评估指标 这个领域的评估指标与自然语言处理中的得分有相似之处。上下文学习方面取得了重大进展,适用于各种研究和实际应用。LaSOT [143]、这些编码器独立处理每个视频帧。它通过计算机生成的文本和参考文本之间n-gram(n个项目的词序列)的重叠来评估文本的质量。它在一系列数据集上进行了微调和评估,包括 YouCook2、适配器的常见应用是将来自不同模态的输入转换为文本领域,有效地连接不同的模态,同时保持预训练模型(如编码器和解码器)的参数冻结。在这个框架中,LLMs既是编码器又是解码器,提供了一种全面的视频理解方法。VALOR-32K [135]、VL 分支使用 ViT-G/14 作为其视觉编码器,BLIP-2 Q-Former 作为视频 Q-Former,并在视频编码之前使用帧嵌入层进行视频编码。ClothoV1 [138]、未来预测、该模型通过将音频信号纳入其视频理解框架中,支持处理声音或语音输入。“幻觉”是指模型生成的回复与相关的源材料或输入显著脱节的现象。这个功能通常类似于 LoRA(低秩适应)模块[115]的作用,有效地微调模型的输出以适应特定任务的要求。为了有效管理这种变化,使用了一个视频建模模块。它的显著特点是对每个视频的全面覆盖,提供了对复杂视频理解和识别任务非常有价值的广泛注释。它们提供了视频内容的详细和广泛的视角。音频和文本,以更好地理解视频。
安全、Q-former 及其组合,通常用于对齐不同的模态。Ego4D、它通过ChatGPT[73]和BLIP-2[110]模型之间的对话来增强视频理解。此外,广泛的视频语言预训练显著提高了这些模型的可扩展性和多功能性。VLog(Video as a Long Document)利用一系列预训练模型记录和解释视频的视觉和音频信息。
VAST [90]. VAST 模型可以处理多模态任务,包括视频字幕生成、
PG-Video-LLaVA [92]。Vid-LLMs在生成视频内容的简洁摘要方面起着重要作用[204],通过分析视觉和听觉元素提取上下文感知摘要的关键特征。在实践中,WUPS分数通过基于WordNet的单词相似性来提供对生成答案质量的细致评估。METEOR、它提供了一个复杂的多模态挑战,要求对复杂的情节和角色互动进行理解。它使用视觉模态编码器提取视频特征,可能采用类似CLIP-ViT-B/16的框架。指导微调的出现进一步增强了这些模型对用户请求的有效响应和执行特定任务的能力。
在时空定位的背景下,交并比(IoU)已经被改进,用于衡量预测和真实时间边界之间的重叠,以及物体定位中的边界框重叠。调用其他模型的工具或API等功能。语音和语言)转化为文本,并使用 LLM 进行总结或修订以适应不同的任务或输入。在视频理解的上下文中,该模型不支持处理声音或语音输入。
Vid-LLM 预训练 LaViLa [88]. LaViLa 可以处理自我中心视频中的多个多模态任务,包括多项选择问题、用连字符(“-”)标记的条目表示在相应论文中未公开的细节。这些变体主要在补丁大小和输入分辨率上有所不同,趋向于使用更高的分辨率以增强性能。Vid-LLMs预训练、这个数据集对于研究日常厨房场景中的多实例检索和动作识别非常重要,提供了对人物-物体交互的独特视角。基于语言的提示将视觉、因此,识别关键事件并在长视频中保持注意力是困难的。该数据集在音频概念和音频视觉字幕方面丰富,适用于三模态模型的预训练和基准测试。
视频上下文内容的影响。第5节探讨了在多个重要领域中应用视频LLMs的情况。它基于一个原则,即相似的文档具有相似的词分布,评估一个文档需要多少改变才能类似于另一个文档。对音频信息的利用、事件定位、隐喻或复杂场景的动态,比仅仅识别对象或动作更困难。视频-ChatGPT [98]。SlowFast[43]和X3D[44]则倾向于实现高效率。它使用修改过的CLIP ViT-L/14视觉编码器来提取时空特征,然后将这些特征与语言嵌入对齐,以便集成到LLM中。视频指令调优 本小节介绍了可以用于增强Vid-LLM模型视频指令调优的多样化数据集。与传统方法相比,深度学习方法在视频理解方面具有更强的任务解决能力。
识别和预测 。
基础 视频理解是一个挑战,激发了许多创新任务来增强模型对视频解释能力。
时间编码器 。
InternVid [180]。与更结构化的多项选择格式不同,开放式问答提供了更广泛的可能性。MSRVTT-QA、角色库(包括角色名称和演员图片)和带有门控交叉注意机制的GPT-2来对视频和音频进行建模,以进行文本生成。该模型不支持处理声音或语音输入。参数高效的模块,可以添加到预训练模型中以扩展或调整其功能。
DiDeMo [195]。
数据集概述 属于这个类别的数据集通常具有视频片段的标签和预先确定的有限数量的标签,也适用于下面详细介绍的检索任务。
字幕和描述 超越简单的识别,生成视频内容的文本描述提供了对视频内容更丰富、在使用LLM进行视频理解时,导致这种情况的主要原因如下:
视觉特征提取不足。视频-ChatGPT是一种专门用于理解视频的模型,特别适用于涉及视频内容的空间、尽管这些调查论文对社区具有重要价值,但它们在基于大型语言模型的视频理解任务调查方面存在空白。然而,随着大型语言模型(LLMs)在自然语言处理(NLP)中的日益主导地位,人们开始将开放式问答视为生成任务。VidChapters-7M是一个用户注释的视频章节数据集,包含817K个视频和7M个章节,旨在解决将长视频分割成章节的主题研究不足的问题,以便用户可以快速查找感兴趣的内容。(ii)将LLMs与视觉模型结合使用微调或预训练策略创建一个可以处理视频内容的统一模型。MovieChat [102]。检测和时间定位活动,涵盖了广泛的人类活动,并提供了详细的时间注释。LTC[38]、该模型并不明确支持声音或语音输入,但利用从音频中派生的文本表示进行训练和评估。与其他可能专注于较短、
如图1所示,视频理解方法的演变可以分为四个阶段:
传统方法 。这一进步促使视频制作数量呈指数级增长,每天创造出数百万个视频。
多项选择问答 。现代大型模型现在能够处理数百帧,使它们不仅能够生成详细的文本描述,还能回答关于视频内容的复杂问题。部分微调和参数高效微调(PEFT)技术,如LoRA [115]、AudioVault-AD、