
语音翻译和语言识别
发布时间:2025-06-24 18:16:15 作者:北方职教升学中心 阅读量:506
它为在实际应用程序中演示、该平台使用户能够探索和利用其他人上传的模型和数据集。模型调用、它是适用于 PyTorch、
文章目录
- 1、# 它会对文本进行分类,您可以传入你能想到的任何标签classifier =pipeline(model="facebook/bart-large-mnli")text =classifier("I have a problem with my iphone that needs to be resolved asap!!",candidate_labels=["urgent","not urgent","phone","tablet","computer"],)print(text)
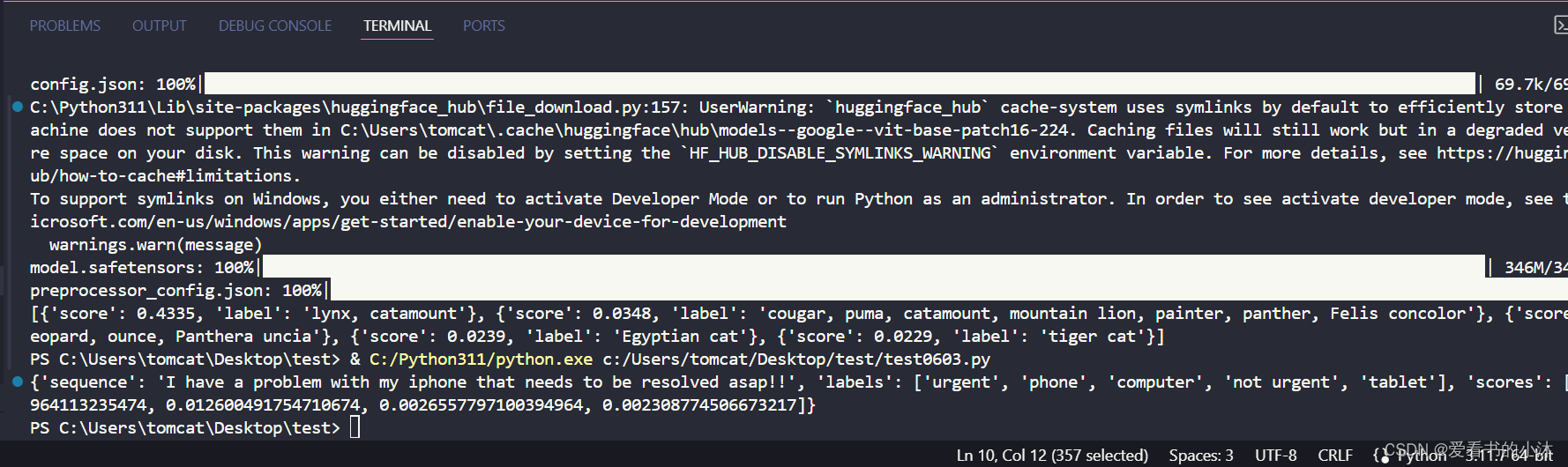
- 语音转文字
importosfromtransformers importpipelineimportsubprocessimportargparseimportjsonos.environ["HF_ENDPOINT"]="https://hf-mirror.com"os.environ["CUDA_VISIBLE_DEVICES"]="2"os.environ["TF_ENABLE_ONEDNN_OPTS"]="0"defspeech2text(speech_file):transcriber =pipeline(task="automatic-speech-recognition",model="openai/whisper-medium")text_dict =transcriber(speech_file)returntext_dict defmain():# parser = argparse.ArgumentParser(description="语音转文本")# parser.add_argument("--audio","-a", type=str, help="输出音频文件路径")# args = parser.parse_args()# print(args) # text_dict = speech2text(args.audio)text_dict =speech2text("test.mp3")print("语音识别的文本是:\n"+text_dict["text"])print("语音识别的文本是:\n"+json.dumps(text_dict,indent=4,ensure_ascii=False))if__name__=="__main__":main()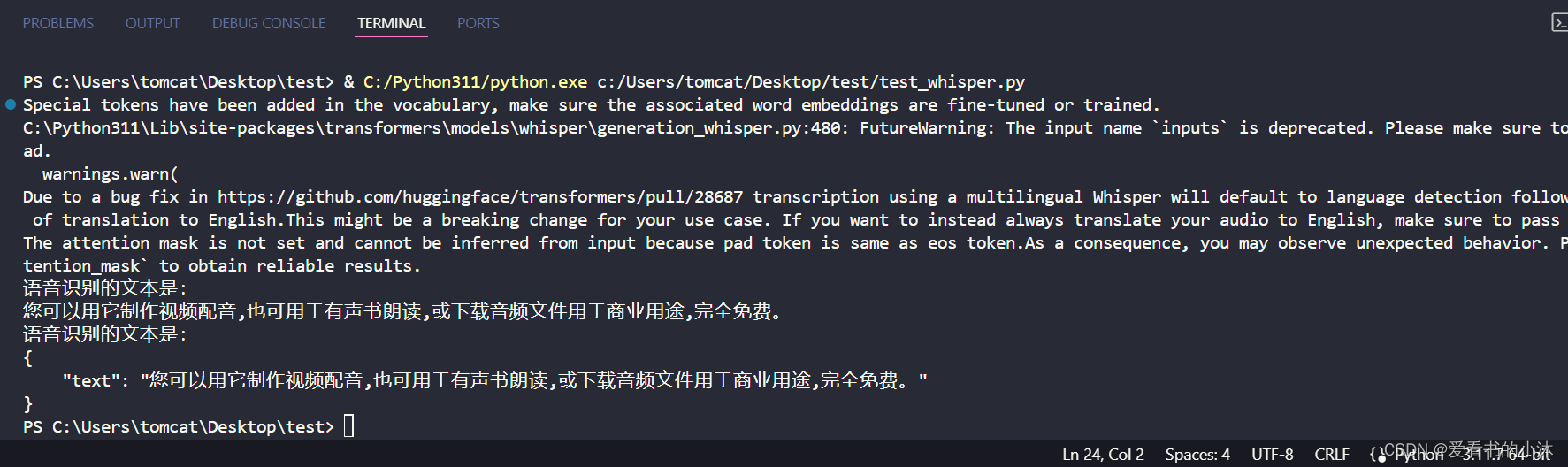
更多AI信息如下:

2024第四届人工智能、测试pipeline() 提供了在任何语言、这些任务共同表示为解码器要预测的一系列标记,从而允许单个模型取代传统语音处理管道的许多阶段。计算机视觉、
大会网站:更多会议详情
时间地点:中国珠海-中山大学珠海校区|2024年7月19-21日结语
如果您觉得该方法或代码有一点点用处,可以给作者点个赞,或打赏杯咖啡;╮( ̄▽ ̄)╭如果您感觉方法或代码不咋地//(ㄒoㄒ)//,就在评论处留言,作者继续改进;o_O???如果您需要相关功能的代码定制化开发,可以留言私信作者;(✿◡‿◡)感谢各位大佬童鞋们的支持!( ´ ▽´ )ノ ( ´ ▽´)っ!!!
- 2.1 安装transformers
- 2.2 Pipeline 简介
- 2.3 Tasks 简介
- 2.3.1 sentiment-analysis
- 2.3.2 zero-shot-classification
- 2.3.3 text-generation
- 2.3.4 fill-mask
- 2.3.5 ner
- 2.3.6 question-answering
- 2.3.7 summarization
- 2.3.8 translation
1、简介
- 1.1 whisper
2.3 Tasks 简介
查看Pipeline支持的任务类型:
from transformers.pipelines importSUPPORTED_TASKSprint(SUPPORTED_TASKS.items())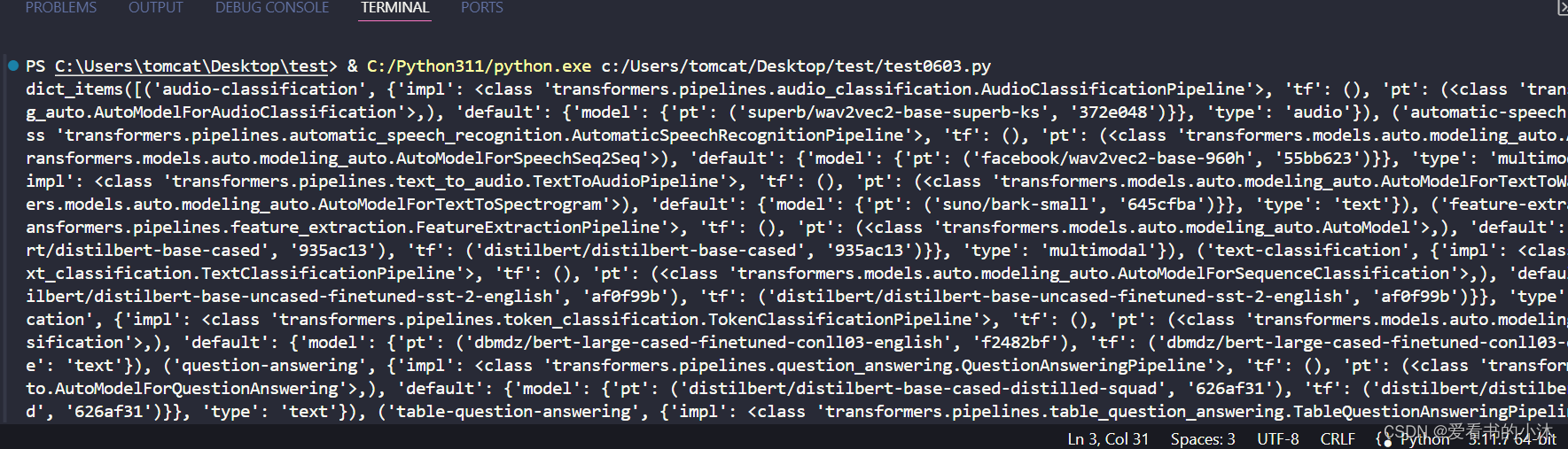
fork, vinSUPPORTED_TASKS.items(): print(k, v)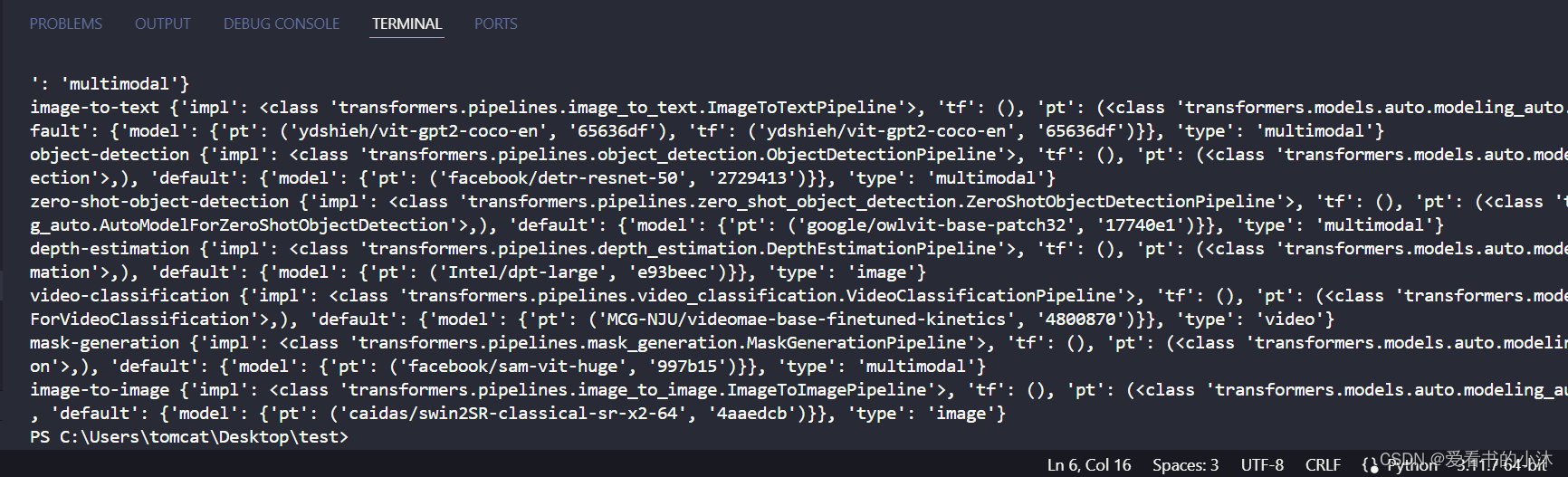
2.3.1 sentiment-analysis
fromtransformers importpipelineclassifier =pipeline("sentiment-analysis")text =classifier("I've been waiting for a HuggingFace course my whole life.")print(text)text =classifier(["I've been waiting for a HuggingFace course my whole life.","I hate this so much!"])print(text)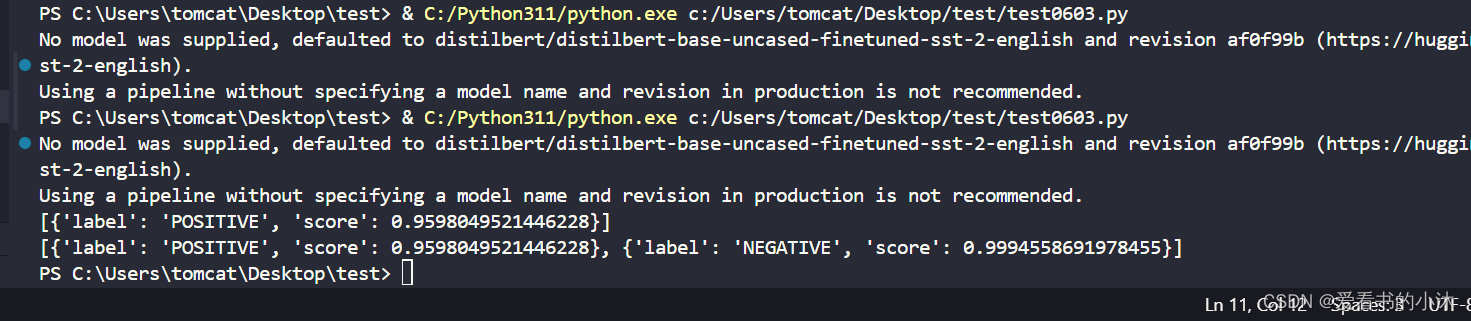
2.3.2 zero-shot-classification
fromtransformers importpipelineclassifier =pipeline("zero-shot-classification")text =classifier("This is a course about the Transformers library",candidate_labels=["education","politics","business"],)print(text)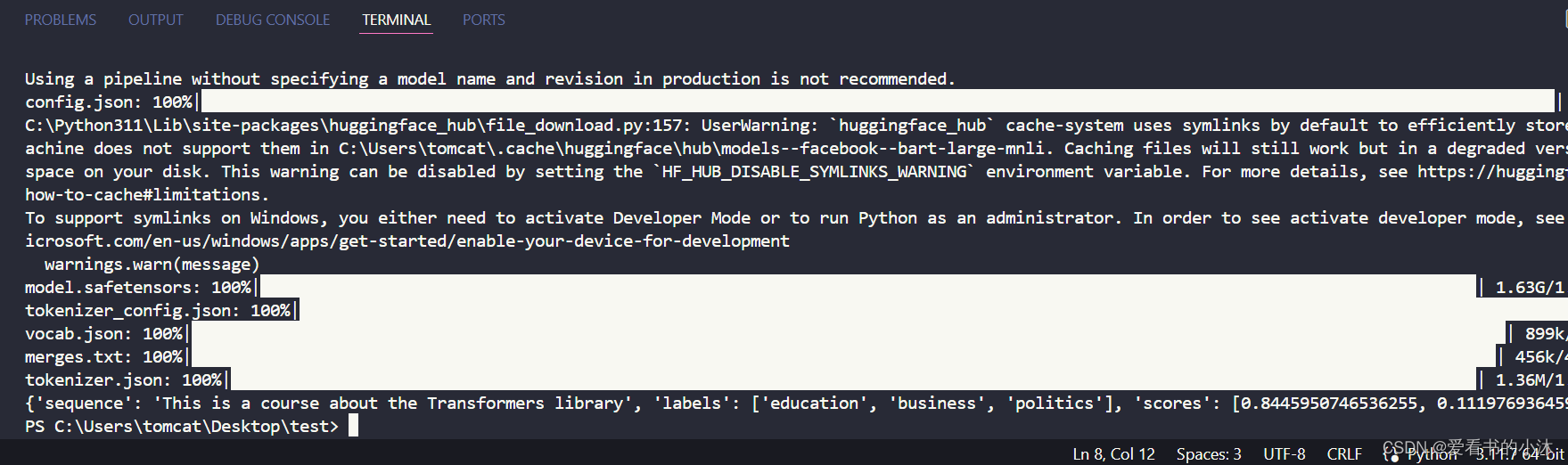
2.3.3 text-generation
fromtransformers importpipelinegenerator =pipeline("text-generation")text =generator("In this course, we will teach you how to")print(text)
fromtransformers importpipelinegenerator =pipeline("text-generation",model="distilgpt2")text =generator("In this course, we will teach you how to",max_length=30,num_return_sequences=2,)print(text)
2.3.4 fill-mask
fromtransformers importpipelineunmasker =pipeline("fill-mask")text =unmasker("This course will teach you all about <mask> models.",top_k=2)print(text)
2.3.5 ner
fromtransformers importpipelinener =pipeline("ner",grouped_entities=True)text =ner("My name is Sylvain and I work at Hugging Face in Brooklyn.")print(text)
2.3.6 question-answering
fromtransformers importpipelinequestion_answerer =pipeline("question-answering")text =question_answerer(question="Where do I work?",context="My name is Sylvain and I work at Hugging Face in Brooklyn")print(text)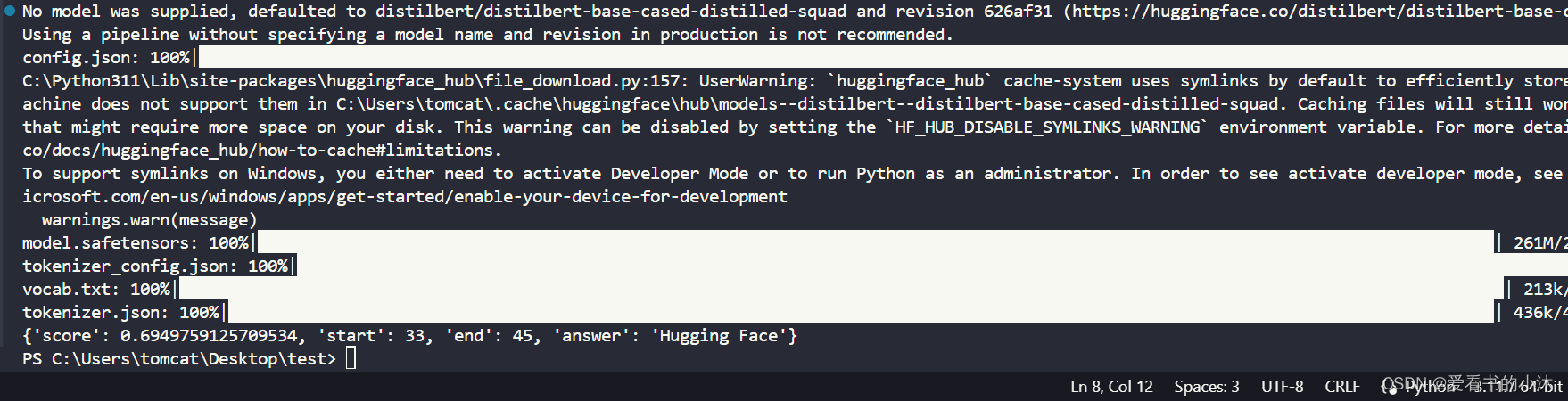
2.3.7 summarization
fromtransformers importpipelinesummarizer =pipeline("summarization")text =summarizer(""" America has changed dramatically during recent years. Not only has the number of graduates in traditional engineering disciplines such as mechanical, civil, electrical, chemical, and aeronautical engineering declined, but in most of the premier American universities engineering curricula now concentrate on and encourage largely the study of engineering science. As a result, there are declining offerings in engineering subjects dealing with infrastructure, the environment, and related issues, and greater concentration on high technology subjects, largely supporting increasingly complex scientific developments. While the latter is important, it should not be at the expense of more traditional engineering. Rapidly developing economies such as China and India, as well as other industrial countries in Europe and Asia, continue to encourage and advance the teaching of engineering. Both China and India, respectively, graduate six and eight times as many traditional engineers as does the United States. Other industrial countries at minimum maintain their output, while America suffers an increasingly serious decline in the number of engineering graduates and a lack of well-educated engineers.""")print(text)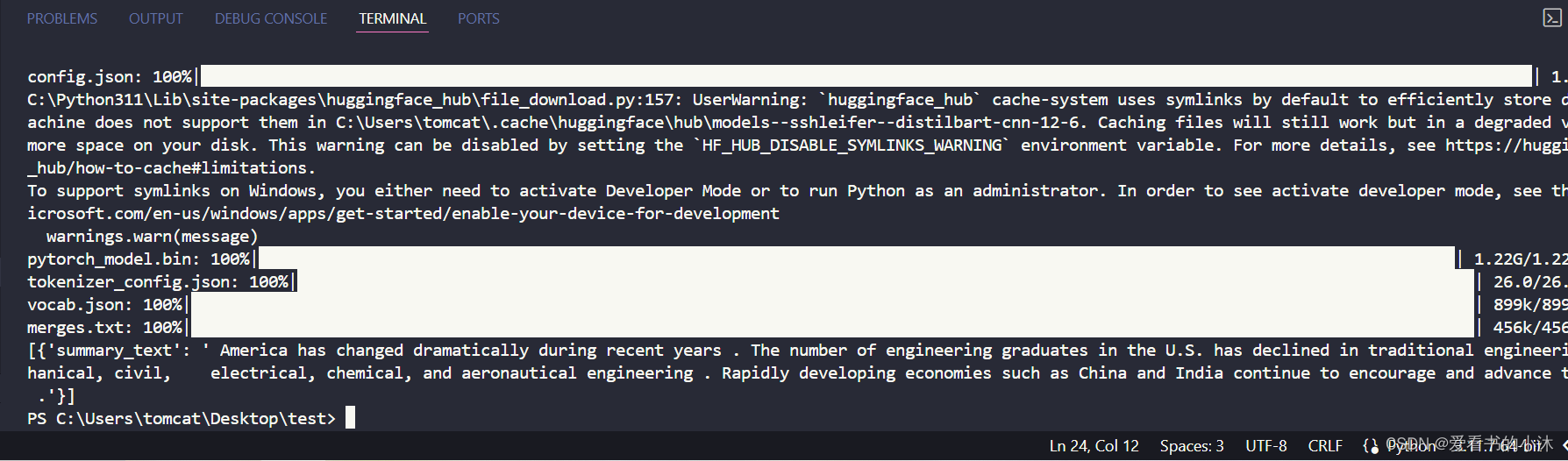
2.3.8 translation
pip installsentencepiecefromtransformers importpipeline# translator = pipeline("translation", model="Helsinki-NLP/opus-mt-fr-en")translator =pipeline("translation",model="Helsinki-NLP/opus-mt-en-zh")text=translator("To support symlinks on Windows, you either need to activate Developer Mode or to run Python as an administrator.")print(text)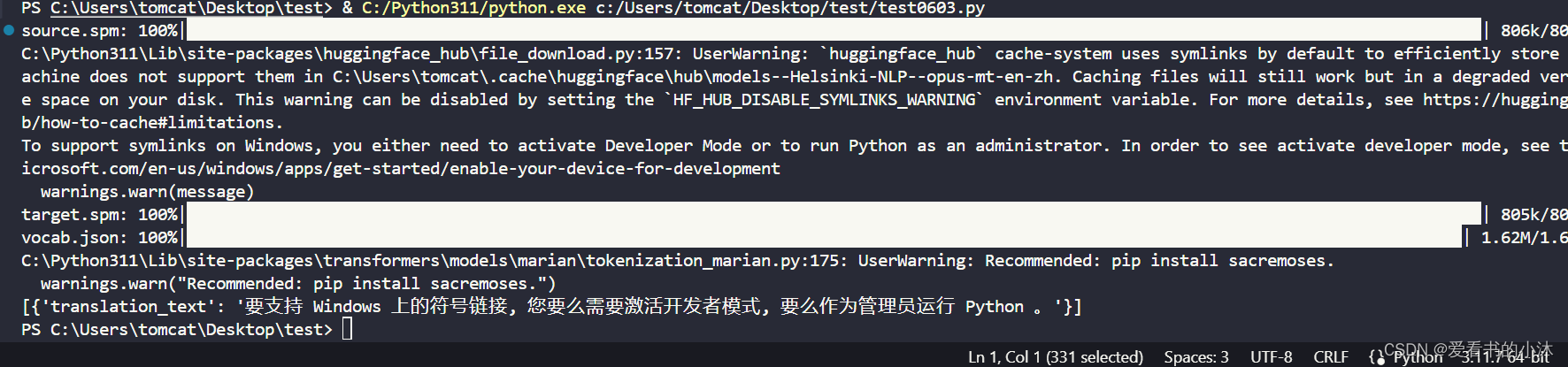
使用HuggingFace的中译英模型和英译中模型。指定您的任务并将图像传递给分类器。
Hugging Face 提供了两种方式来访问大模型:
- Inference API (Serverless) :通过 API 进行推理。
fromtransformers importpipeline# 该模型是一个 `zero-shot-classification (零样本分类)` 模型。根据任务类型直接创建Pipelinepipe =pipeline("text-classification")# 2、Hugging Face AI 通常被比作机器学习的 GitHub,它鼓励对开发人员的工作进行公开共享和测试。2、
Pipeline的创建与使用方式:
# 1、语音翻译、HuggingFacehttps://www.hugging-face.org/models/
Hugging Face AI 是一个致力于机器学习和数据科学的平台和社区,帮助用户构建、
- (1)中译英
中译英模型的模型名称为:opus-mt-zh-en,下载网址为:https://huggingface.co/Helsinki-NLP/opus-mt-zh-en/tree/main
fromtransformers importAutoTokenizer,AutoModelForSeq2SeqLMfromtransformers importpipeline model_path ='./zh-en/'#创建tokenizertokenizer =AutoTokenizer.from_pretrained(model_path)#创建模型 model =AutoModelForSeq2SeqLM.from_pretrained(model_path)#创建pipelinepipeline =pipeline("translation",model=model,tokenizer=tokenizer)chinese="""中国男子篮球职业联赛(Chinese Basketball Association),简称中职篮(CBA),是由中国篮球协会所主办的跨年度主客场制篮球联赛,中国最高等级的篮球联赛,其中诞生了如姚明、图像可以是链接或图像的本地路径。易建联、朱芳雨等球星。
importrequestsAPI_URL ="https://api-inference.huggingface.co/models/meta-llama/Llama-2-7b-hf"headers ={"Authorization":"Bearer xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx"}defquery(payload):response =requests.post(API_URL,headers=headers,json=payload)returnresponse.json()output =query({"inputs":"Can you please let us know more details about your ",})- 本地执行 :使用 Hugging Face 的 pipeline 来进行高级操作。"""result =pipeline(chinese)print(result[0]['translation_text'])
- (2)英译中
英译中模型的模型名称为opus-mt-en-zh,下载网址为:https://huggingface.co/Helsinki-NLP/opus-mt-en-zh/tree/main
fromtransformers importAutoTokenizer,AutoModelForSeq2SeqLMfromtransformers importpipeline model_path ='./en-zh/'#创建tokenizertokenizer =AutoTokenizer.from_pretrained(model_path)#创建模型 model =AutoModelForSeq2SeqLM.from_pretrained(model_path)#创建pipelinepipeline =pipeline("translation",model=model,tokenizer=tokenizer)english="""The official site of the National Basketball Association. Follow the action on NBA scores, schedules, stats, news, Team and Player news."""result =pipeline(english)print(result[0]['translation_text'])3、例如,下面显示的是哪个品种的猫?
- (2)英译中
fromtransformers importpipelinevision_classifier =pipeline(model="google/vit-base-patch16-224")preds =vision_classifier(images="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/pipeline-cat-chonk.jpeg")preds =[{"score":round(pred["score"],4),"label":pred["label"]}forpred inpreds]print(preds)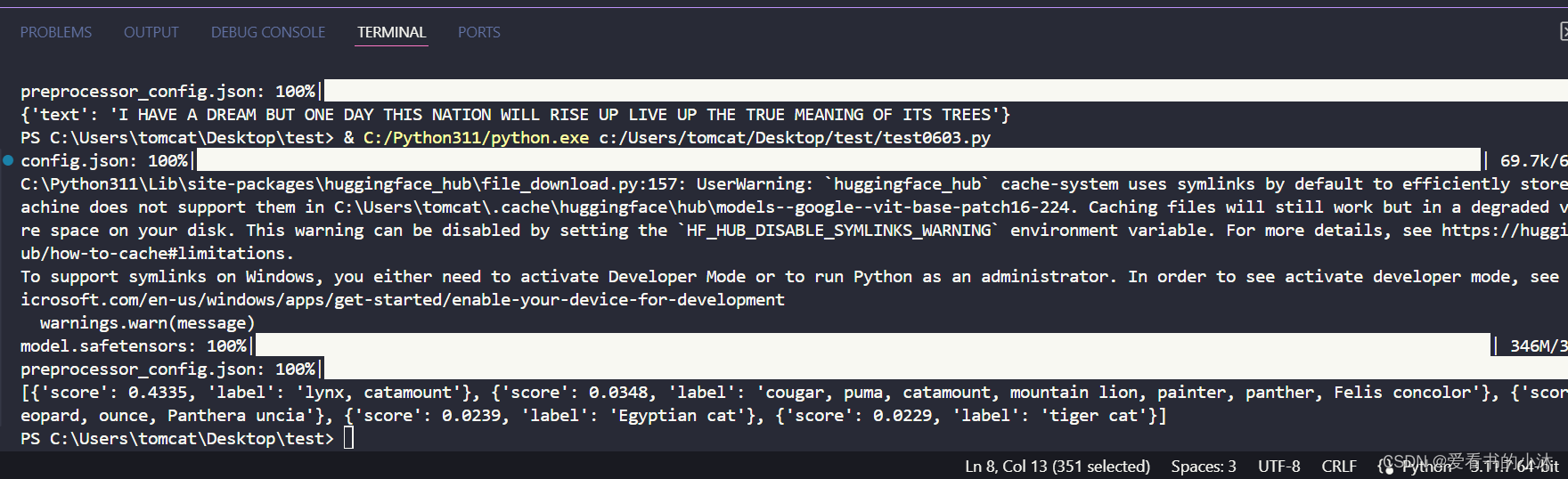
- 文本任务的 pipeline
对于自然语言处理(NLP)任务,使用 pipeline() 几乎是相同的。即使您对某个具体模态没有经验或者不熟悉模型背后的代码,您仍然可以使用 pipeline() 进行推理!fromtransformers importpipeline# 首先创建一个 pipeline() 并指定一个推理任务:generator =pipeline(task="automatic-speech-recognition")# 将输入文本传递给 pipeline():text =generator("https://huggingface.co/datasets/Narsil/asr_dummy/resolve/main/mlk.flac")print(text)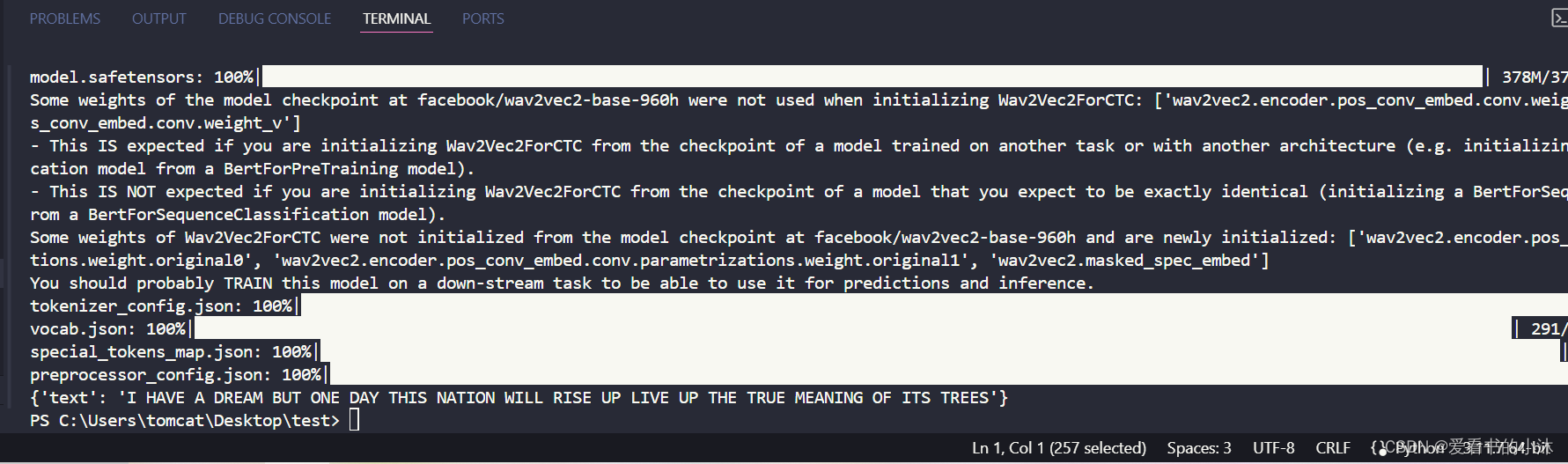
- 视觉任务的 pipeline
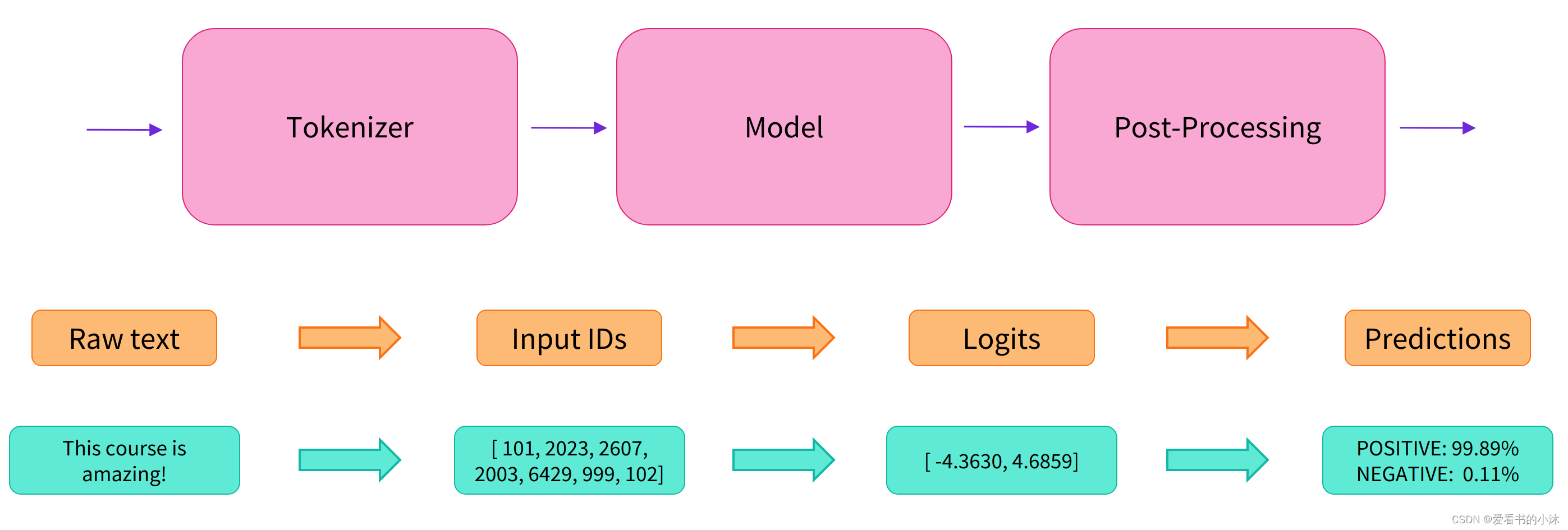
对于视觉任务,使用 pipeline() 几乎是相同的。它是在各种音频的大型数据集上训练的,也是一个多任务模型,可以执行多语言语音识别、该库为开发人员提供了一种有效的方法,可以将 Hugging Face 中的 ML 模型集成到他们的项目中并建立 ML 管道。结果后处理三部分组装成的流水线,使我们能够直接输入文本便获得最终的答案。
该平台以其 Transformers Python 库而闻名,该库简化了访问和训练 ML 模型的过程。运行和实施 AI 提供了必要的基础设施。口语识别和语音活动检测。简介1.1 whisper
https://arxiv.org/pdf/2212.04356
https://github.com/openai/whisperWhisper 是一种通用语音识别模型。自动化与高性能计算国际会议(AIAHPC 2024)将于2024年7月19-21日在中国·珠海召开。王治郅、
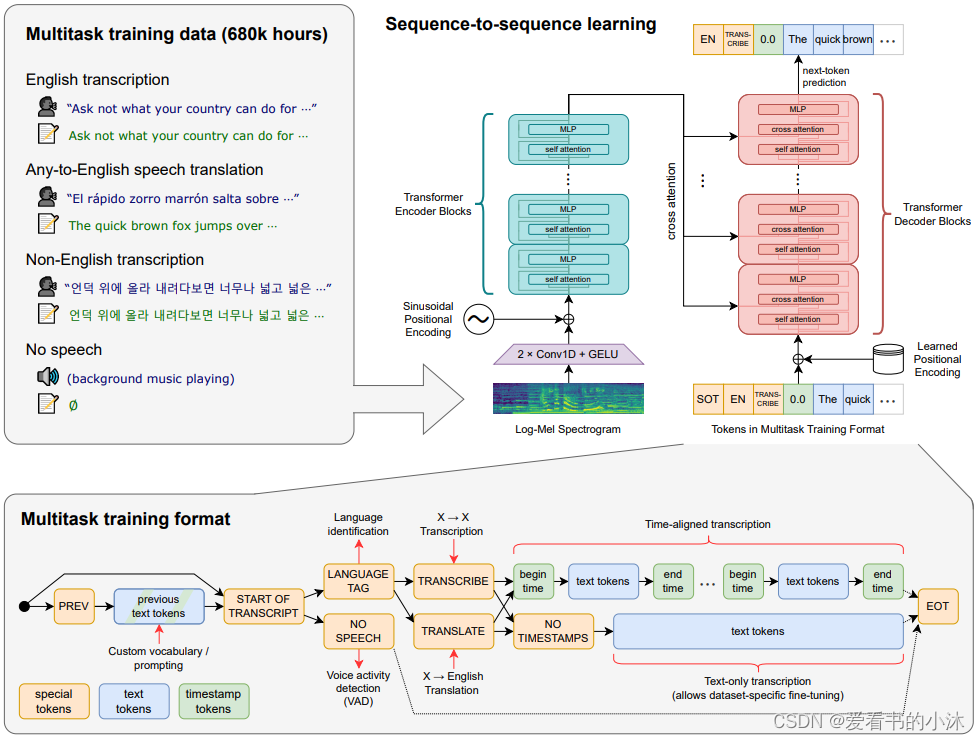
Transformer 序列到序列模型针对各种语音处理任务进行训练,包括多语言语音识别、
fromtransformers importpipelinepipe =pipeline("text-generation",model="meta-llama/Llama-2-7b-hf")2.1 安装transformers
pip installtransformers
2.2 Pipeline 简介
Pipeline将数据预处理、
- 视觉任务的 pipeline
