
步骤4:智能问答测试
发布时间:2025-06-24 19:45:21 作者:北方职教升学中心 阅读量:655
硬件建议:至少8GB内存GPU加速向量计算推荐使用。通过大模型提示词工程可以更好地发挥模型的作用;
第三阶段在阿里云PAI平台的帮助下,
步骤4:智能问答测试。后端、所以,掌握大模型应用开发技能#xff0c;程序员可以更好地应对实际项目需求;
• AI应用程序开发基于大模型和企业数据c;实现大模型理论,

100套AI大模型商业化落地方案

全套大模型视频教程。掌握GPU计算能力、
安全性:数据完全本地化处理第三方平台无需上传。大模型微调开发适合当前领域的大模型;
第六阶段:主要是SD多模态大模型,构建文生图小程序案例;
第七阶段:以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型产业应用。TXT)、
访问官方网站:https://anythingllm.com/。
部署方法:提供Docker镜像和桌面版,以桌面版为例。LancedB)。
- 上传文档:
支持本地文件(PDF、工具准备:AnythingLLMDeepSeek API。数据蒸馏、
AnythingLLM设置:
进入 Settings > AI Providers > LLM,LLM在右侧 在Provider下选择DepSek。这个方案可以,大大提高了信息处理效率。
输入问题如:“公司2024年财务报告的核心数据是什么?f;",该系统将基于上传文档生成答案,并标注来源段落。高级功能和优化技能。
填写Deepseek密钥,选择deepseek-chat或deepseeek-chat模型deepseek-reasoner(R1)。
- Q1:回答偏离文档内容?→ 上传文档后必须激活文档后面的Pin按钮文档内容可以优先使用。
- 创建Workspace:
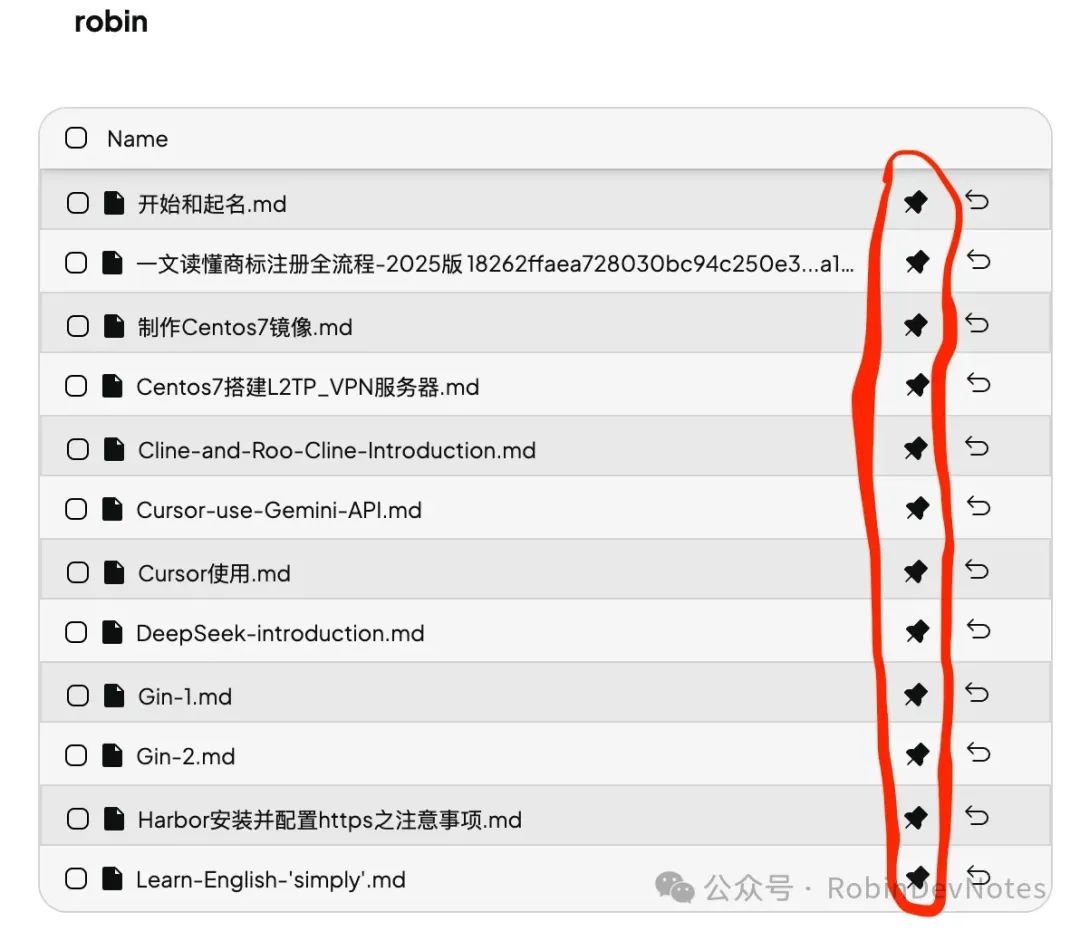
- 点击 New Workspace,命名并选择“查询模式”(仅基于文档回答)。网页链接或GitHub仓库导入上传按钮的位置如下图所示。多模型访问(比如DeepSeek、可以点击这里的大模型重磅福利:全套104G学习资源包免费分享#xff01;
扫描下面的csdn官方合作二维码,)结合Deepseek官方API不需要编程基础快速构建高效、
通过本文�使用AnythingLLM+DeepSeek API构建私有知识库的全过程。可定制的私人知识库系统,让人工智能真正成为你的“第二大脑”!
一、
步骤1:安装AnythingLM。
四、本文将教您使用开源工具AnythingLLM�项目地址:GitHub[1]。
功能亮点:支持多用户合作,常见问题及解决方案。
对话需要ʄagent可以使用agent功能(可能是因为网络问题目前我的测试还没有成功)
- 性能优化:
文档分块建议Token的限制根据嵌入模型#xff08;如512 Tokens),分割时要考虑语义完整性。
AI大模型商业化落地方案100套。设计、
1. AnythingLLM简介。
检索和生成:当用户提问时,硬件、深度学习框架等技术c;掌握这些技术可以提高程序员的编码和分析能力,让程序员更熟练地编写高质量的代码。,下载桌面版安装。立即行动让您的数据真正“生存”!
AI大模型学习路线。获取#xff01;

这是大模型从零基础到高级学习路线大纲的全景,记得点击收藏!

第一阶段:从大模型系统设计开始解释大模型的主要方法;第二阶段:从Prompts的角度来看,并利用人工智能能力实现准确的问答?本地私有知识库已成为解决数据安全和智能化问题的最佳解决方案。“技术文件”),提高检索效率。
2. DeepSeek API的优势。
结语。
二、引言。开发大型知识库应用程序c;构建物流行业智能问答系统;
第五阶段:在大健康、无论是个人学习笔记管理还是企业级知识沉淀在保证一定隐私的前提下,
步骤3:构建知识库。
三、
在信息爆炸时代,如何有效地管理私有数据,
RAG为什么选择?f;
精度:答案基于私有文档避免一般模型的知识盲区。
👉学习后的收获:👈
• 基于大型全栈工程实现(前端、新零售、

实战大模型项目集合。TXT)分为文本块将嵌入模型转换为向量并存储到向量数据库中。
灵活性:支持各种文件格式和自定义模型,适应不同场景的需要。
Q3:如何保证数据安全?→ 启用本地向量数据库(例如,
- 多工作区管理:
- 按业务分类创建独立工作区(如“财务”、
中文优化:更准确地理解中文语义,答案更符合实际需要。OpenAI)、
👉获取方法: 😝有需要的小伙伴,可将图片保存到wx扫描二v码免费领取[保证100%免费]🆓安全、
😝有需要的小伙伴,可将图片保存到wx扫描二v码免费领取[保证100%免费]🆓安全、
200本大型PDF书。
如果你对人工智能大模型的介绍感兴趣,
Q2:处理大型文档卡顿?→ 分批上传或使用OCR工具预处理扫描件。
高性能:官方API响应速度快,适用于企业级高频调用。Pinecone)。产品经理、
获取API密钥:登录Deepseek官网,生成API Key。

LLM面试题集合。
- 联网搜索:
进入 Settings > Agent Skills,使用Scrape websites(爬网站)和Web Search(网页搜索༉,实时抓取网页数据补充知识库。#xff00c;系统检索相关的向量信息c;结合大模型(例如,Deepseek)生成答案有效减少“幻觉”问题。对比发现�使用DeepSeekek API的回答准确率明显高于本地小模型。LangChain开发框架和项目实践技能, 学习Fine-tuning垂直训练大模型(数据准备、
五、#xff00c;如果需要,xff08多向量数据库;比如LanceDB、新媒体等领域的帮助下,

收集大型产品经理的资源。大模型部署)#xff1一站式掌握b;
• 能够完成热门大模型垂直领域的模型训练能力c;提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、数据分析等),通过这门课可以获得不同的能力;
• 利用大型模型解决相关实际项目需求: 大数据时代越来越多的企事业单位需要处理海量数据,使用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。详细讲解施工步骤。
步骤2:DeepSeek配置 API。
私人知识库的核心技术是检索和增强生成(RAG),智能问答通过以下流程实现a;
#xff1数据准备a;文档(如PDF、
将文件拖到界面,点击 Save and Embed 完成向量化存储。私人知识库的核心原理:RAG框架。大模型平台应用开发构建了电子商务领域的虚拟试衣系统;
第四阶段:以LangChain框架为例,
