
样本方差
发布时间:2025-06-24 18:12:55 作者:北方职教升学中心 阅读量:437
。 函数,用于计算给定数组(或者一维数组的轴向)样本方差或总体方差,这取决于提供的参数。 函数:
。def calculate_variance(lst, sample=True): n = len(lst) mean = sum(lst) / n if sample: variance = sum((xi - mean) ** 2 for xi in lst) / (n - 1) else: variance = sum((xi - mean) ** 2 for xi in lst) / n return variancedef calculate_std_deviation(lst, sample=True): variance = calculate_variance(lst, sample) std_dev = variance ** 0.5 return std_dev# 示例数据data = [1, 2, 3, 4, 5]# 计算样本方差和样本标准差sample_variance = calculate_variance(data, sample=True)sample_std_dev = calculate_std_deviation(data, sample=True)# population计算总体方差和总体标准差variance = calculate_variance(data, sample=False)population_std_dev = calculate_std_deviation(data, sample=False)print("样本方差: ", sample_variance)print("样品标准差: ", sample_std_dev)print("总体方差: ", population_variance)print("总体标准差: ", population_std_dev)。的用法。 。同样来自。numpy.std()。 。numpy.std()。 库。2.std()。ddof。var()。
import numpy as npdata = np.array([1, 2, 3, 4, 5])sample_variance = np.var(data, ddof=1)population_variance = np.var(data, ddof=0)print("样本方差:", sample_variance)print("整体方差:", population_variance)。时,计算总体方差,此时除数是 。在这个例子中,df.var()。,即 。计算样本数据集的离散程度,计算公式::当 。
。
var()。滚动窗的计算是根据指定窗口的大小滑动计算每个窗口的方差和标准差。样本方差。如果你想计算总体方差Pandas没有直接的参数调整,因为Pandas遵循NumPy的行为,
默认采用。
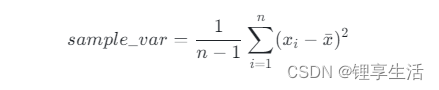
var()和std()在pandas环境下:。
(Bessel's correction),计算总体方差需要在计算前添加数据集1。随后,我们将进一步讨论标准差,它是方差的平方根,直观地反映了数据点与平均值之间的平均偏差,通过。计算函数实现标准差。numpy.var()。由于第一行和第二行数据不足3,因此,和。计算样本方差和总体方差c;以及。var()。函数通常指的是。
总体方差。 。中的。
std()。其用法及其背后的统计意义。- ,这是一个方差算术平方根,因此,
var()。不能计算出方差和标准差。补充:滚动窗是指选择3个数字的窗口(计算3个数的方差和标准差),如1,2,3;2,3,4。std()。 。1.。
std()。2.std()。n - 1。numpy.var(a, axis=None, dtype=None, out=None, ddof=0, keepdims=False)。。函数: 。(n - 1)。var()和std()在numpy环境下:。
要在 numpy 计算样本方差,设置 。
var()。numpy。文章将进一步扩展。。可直接应用于DataFrame或Series对象,计算它们的列(或行)方差和标准差。
摘要: 本文将带您探索Python中的两个重要统计函数。
:与样本平均值相比,var()和std()在python标准库下:。n。numpy。。在默认情况下:
。
函数。参数的作用。 在Pandas库中,var()。提供了样本标准差或总体标准差的计算。会默认计算每个变量(列)样本方差和样本标准差。ddof=1。。numpy.var()。而不是 。首先,我们将详细阐述方差的概念,它是衡量一组数值数据离散度的关键指标,并通过实例演示如何使用。var()和std()在pandas环境下:。表示 Bessel's correction,即除以 。df.std()。与。ddof=1。另外,在numpy环境下,
sample_std_dev = np.std(data, ddof=1)population_std_dev = np.std(data, ddof=0)print("样品标准差:", sample_std_dev)print("总体标准差:", population_std_dev)。
整体标准差对应于整体方差的平方根。和。 。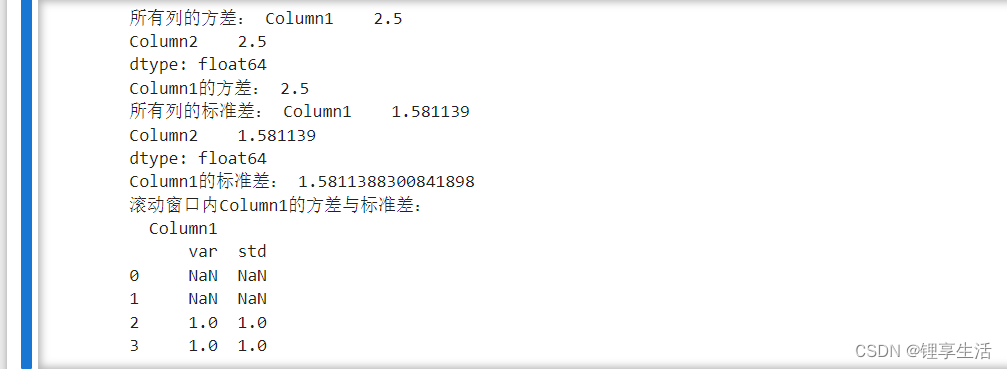
import pandas as pd# 创建一个简单的DataFramedata = { 'olumn1': [1, 2, 3, 4, 5], 'olumn2': [6, 7, 8, 9, 10]}df = pd.DataFrame(data)# 计算DataFrame所有列的方差variances = df.var()# 计算单列方差column1_var = df['olumn1'].var()# 计算DataFrame所列标准差std_devs = df.std()# 计算单列标准差column1_std = df['olumn1'].std()# 用滚动窗计算移动方差和标准差df_rolling = df.rolling(window=3).agg({'olumn1': ['var', 'std']})# print输出结果(");所有列方差:", variances)print("column1的方差:", column1_var)print("所列标准差:", std_devs)print("Column1的标准差:", column1_std)# 查看滚动窗口的计算结果(");Column1在滚动窗口中的方差和标准差:")print(df_rolling.head(4))。std()。std()。ddof=0。和。 标准Python库中没有名称。
