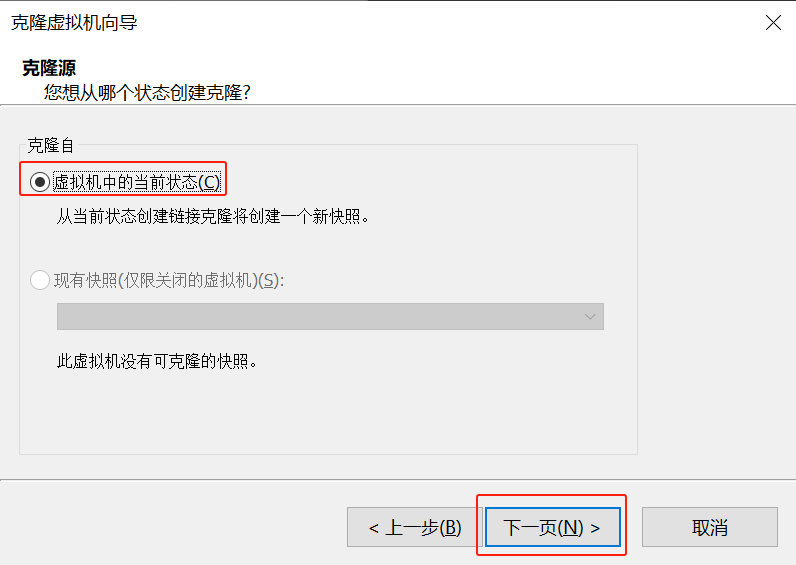
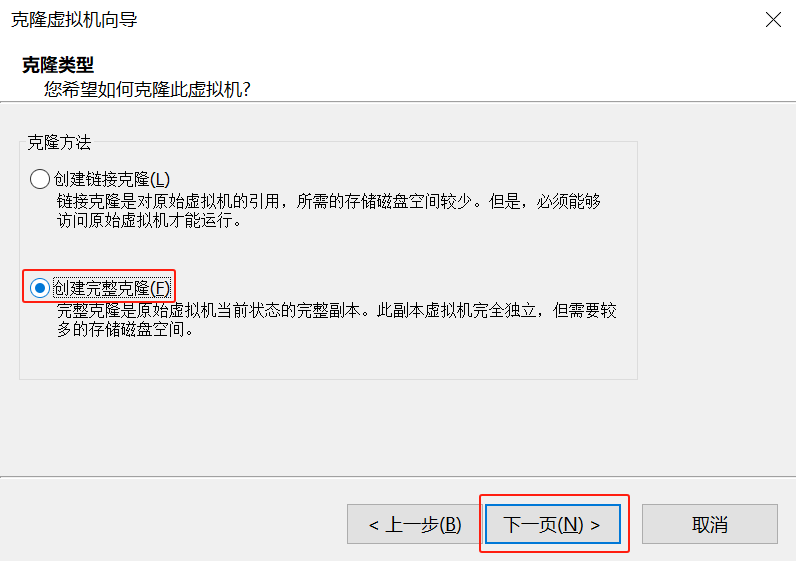
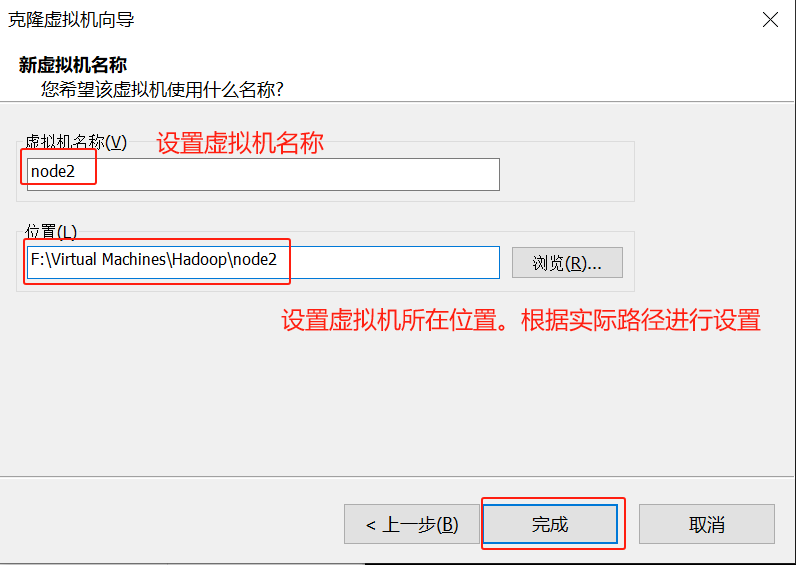
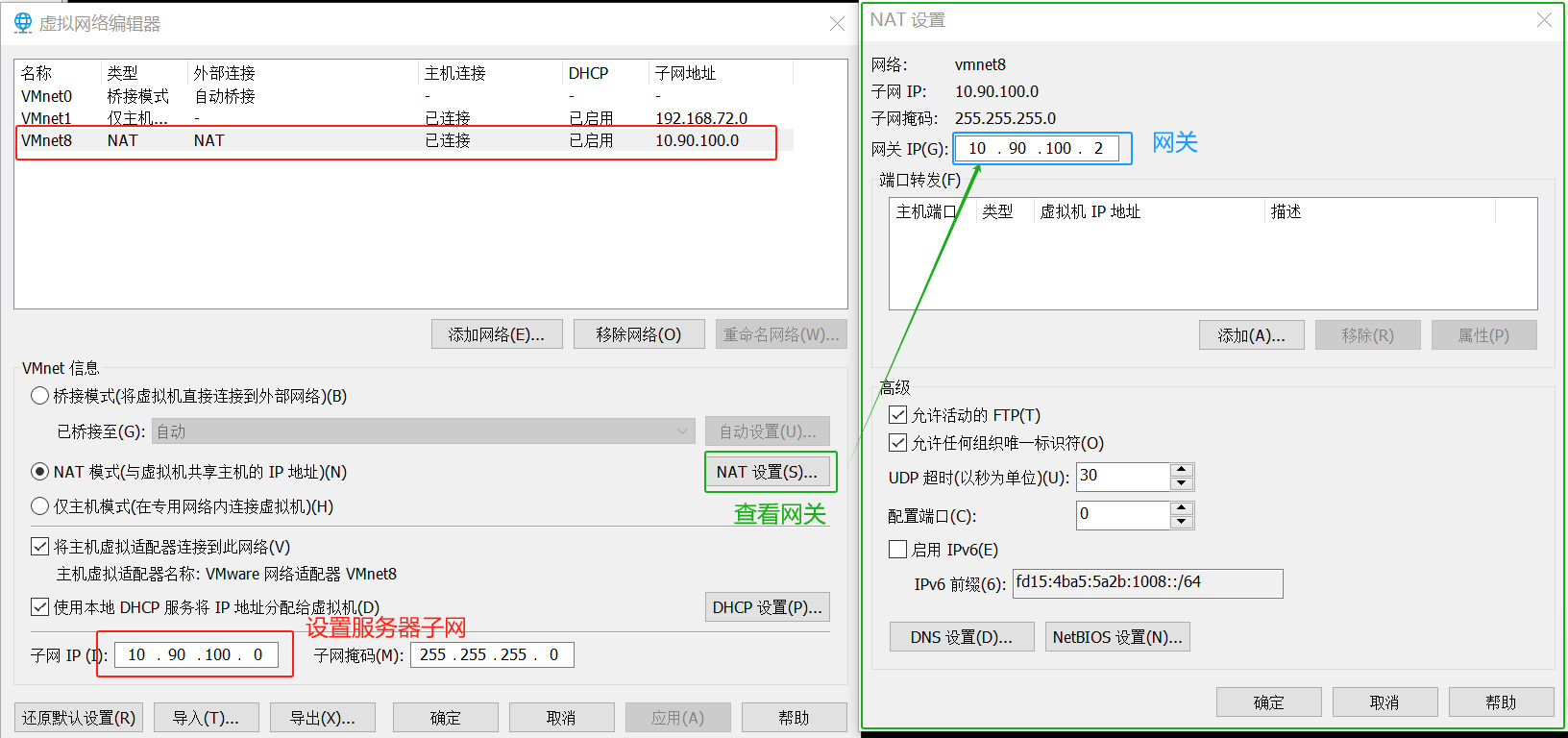
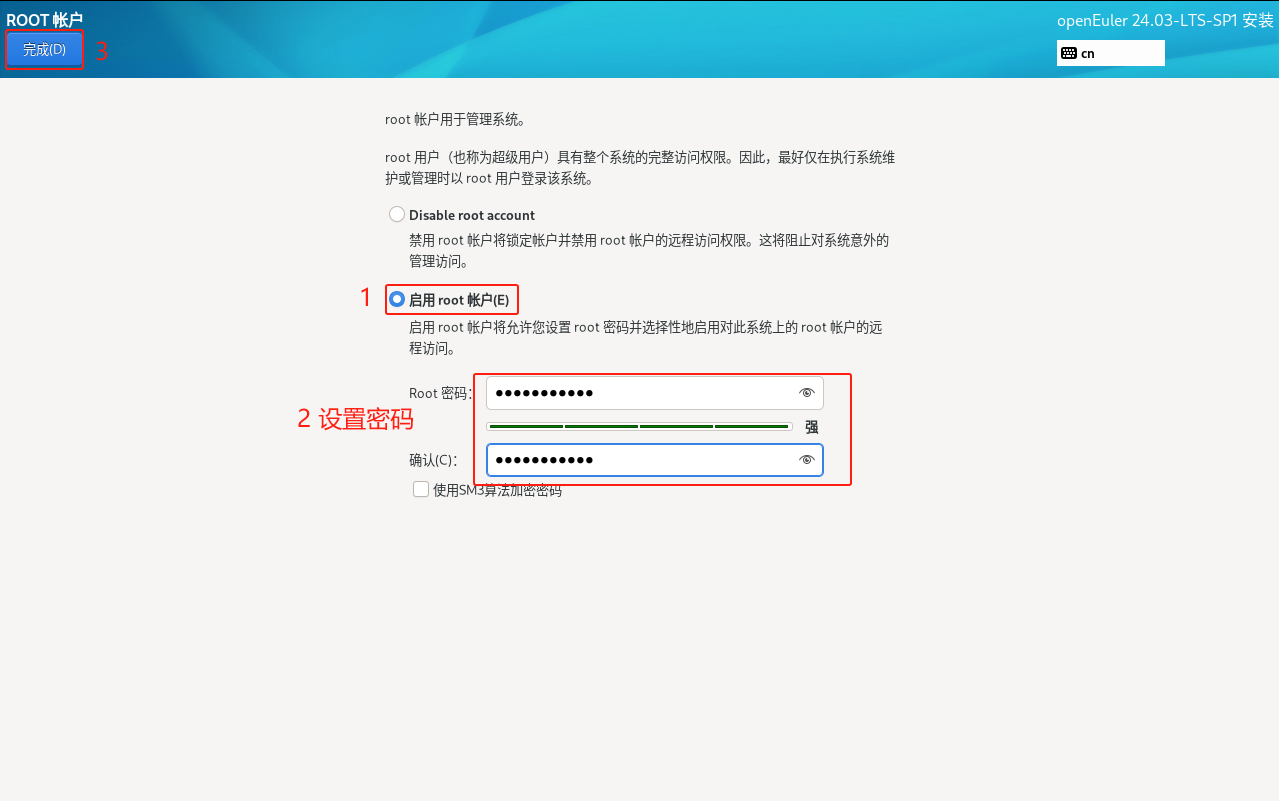
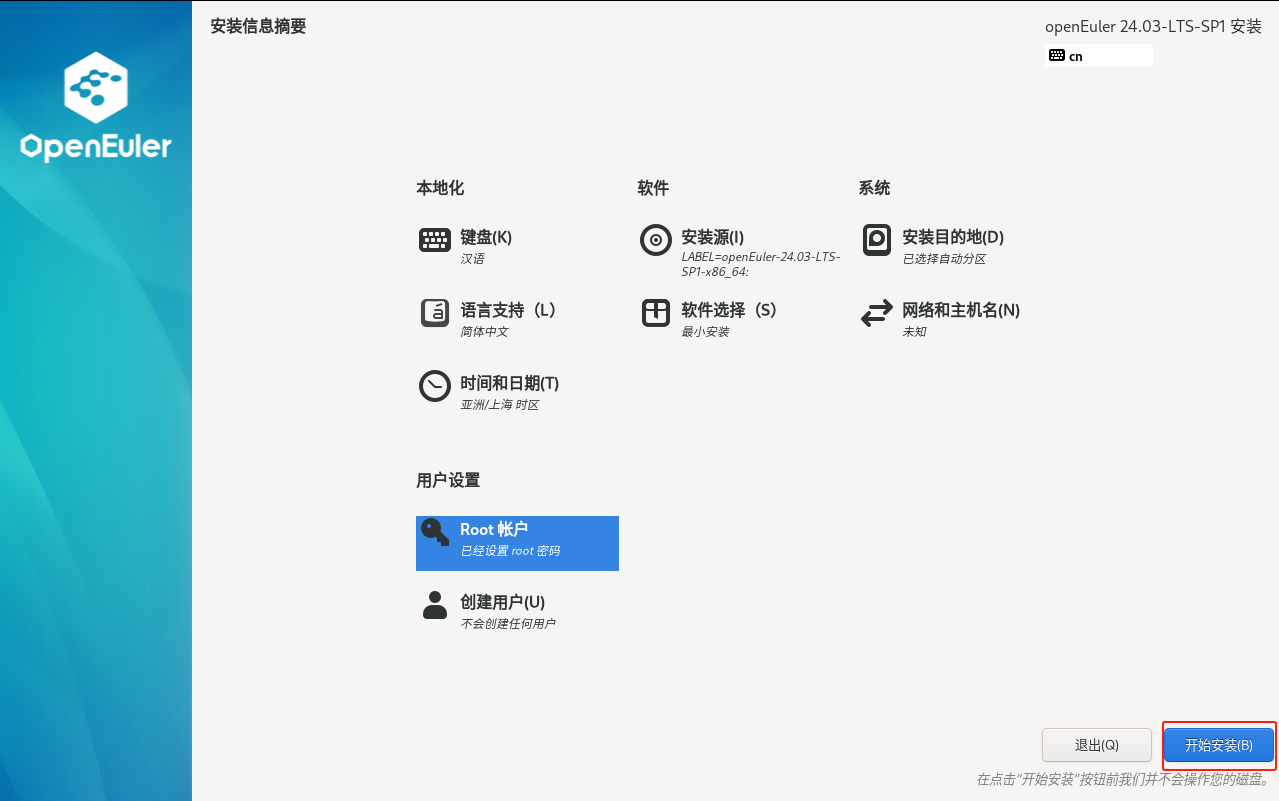
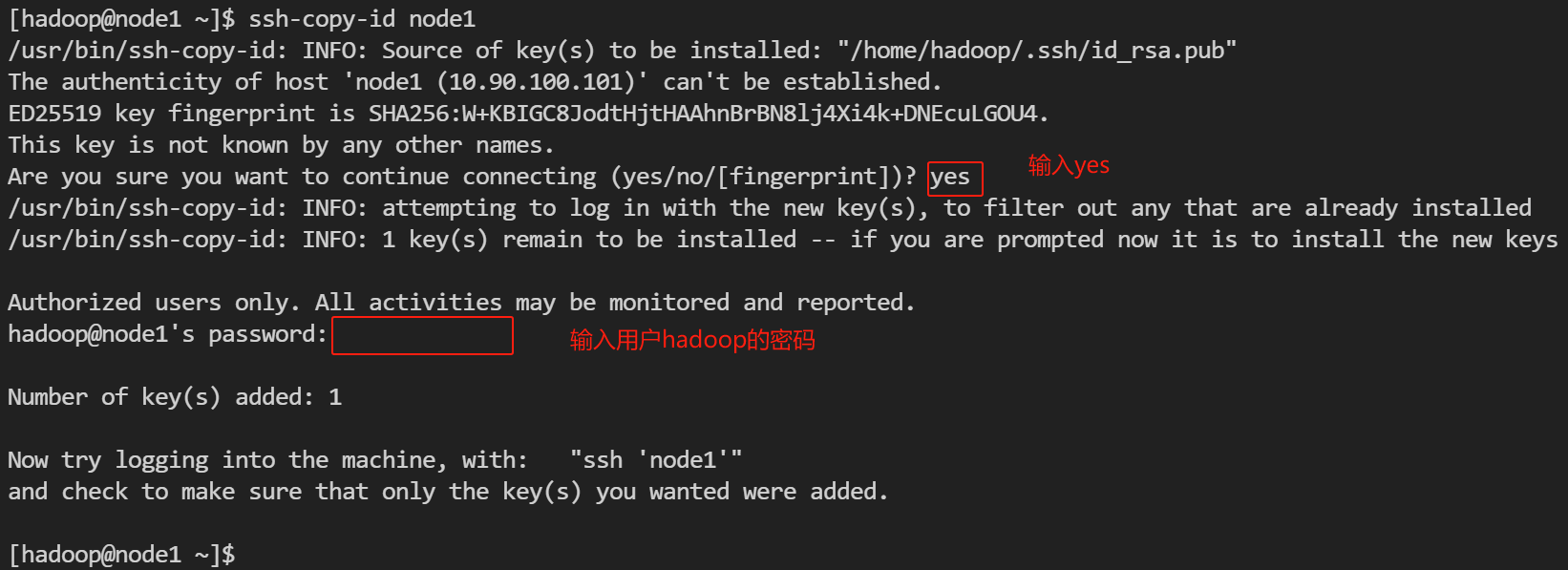
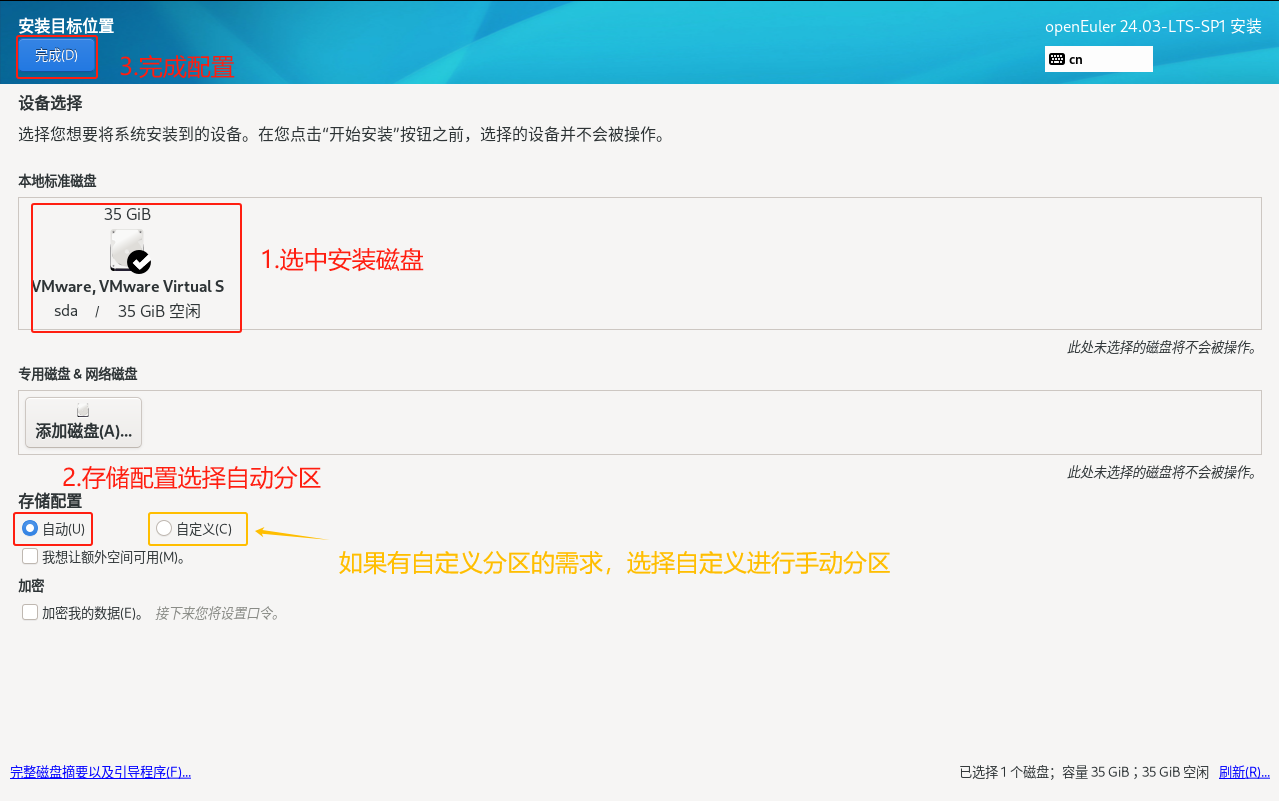
这里以自动分区为例
发布时间:2025-06-24 18:55:38 作者:北方职教升学中心 阅读量:638
- 在node1主机上的用户主目录下创建
bin目录
[hadoop@node1 ~]$ cd~[hadoop@node1 ~]$ mkdirbin[hadoop@node1 ~]$ lsbin进入新建的bin目录,并在该目录下创建分发脚本文件xsync
[hadoop@node1 ~]$ cdbin[hadoop@node1 bin]$ vimxsyncxsync文件的内容如下
#!/bin/bash#1. 判断参数个数if[$#-lt1]thenechoNot Enough Arguement!exit;fi#2. 遍历集群所有机器forhostinnode1 node2 node3doecho====================$host====================#3. 遍历所有目录,挨个发送forfilein$@do#4. 判断文件是否存在if[-e$file]then#5. 获取父目录pdir=$(cd-P$(dirname $file);pwd)#6. 获取当前文件的名称fname=$(basename$file)ssh$host"mkdir -p $pdir"rsync-av$pdir/$fname$host:$pdirelseecho$filedoes not exists!fidonedone修改权限,改文件增加执行权限:
[hadoop@node1 bin]$ chmod+x xsync [hadoop@node1 bin]$ lsxsync#xsync文件所在的路径[hadoop@node1 bin]$ pwd/home/hadoop/bin配置环境变量
[hadoop@node1 bin]$ cd~[hadoop@node1 ~]$ vim.bashrc在用户级的环境变量文件.bashrc中添加xsync脚本文件的配置,方便后续执行脚本实现分发操作。
在node2、
在node2、
- 修改环境变量
修改node2、
[hadoop@node1 ~]$ vim.bashrc 在.bashrc文件最后一行添加环境变量的配置
exportPATH=/home/hadoop/bin:$PATH添加之后的结果如下
[hadoop@node1 ~]$ cat.bashrc # Source default setting[-f/etc/bashrc ]&&./etc/bashrc# User environment PATHexportPATHexportPATH=/home/hadoop/bin:$PATH执行source命令让环境变量配置生效。执行以上操作后,查看node2和node3主机 /opt/software/目录下是否有hadoop相关文件。
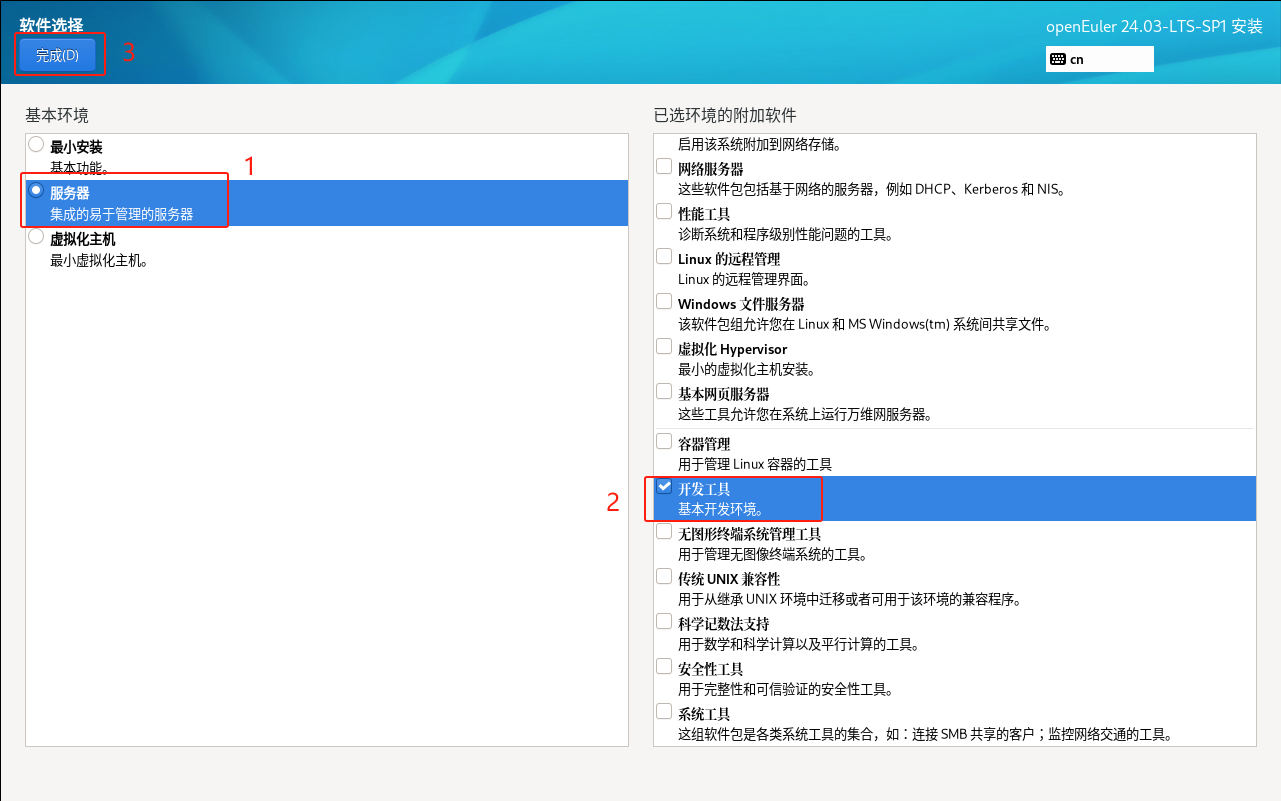
注意:
在生产环境中以实际部署服务器类型为准,并选择相应的软件安装。
重启系统看到登录提示即表示已经安装完成。
ONBOOT设置为yes,表示开机启动网卡。3.5 验证
3.5.1 进程验证
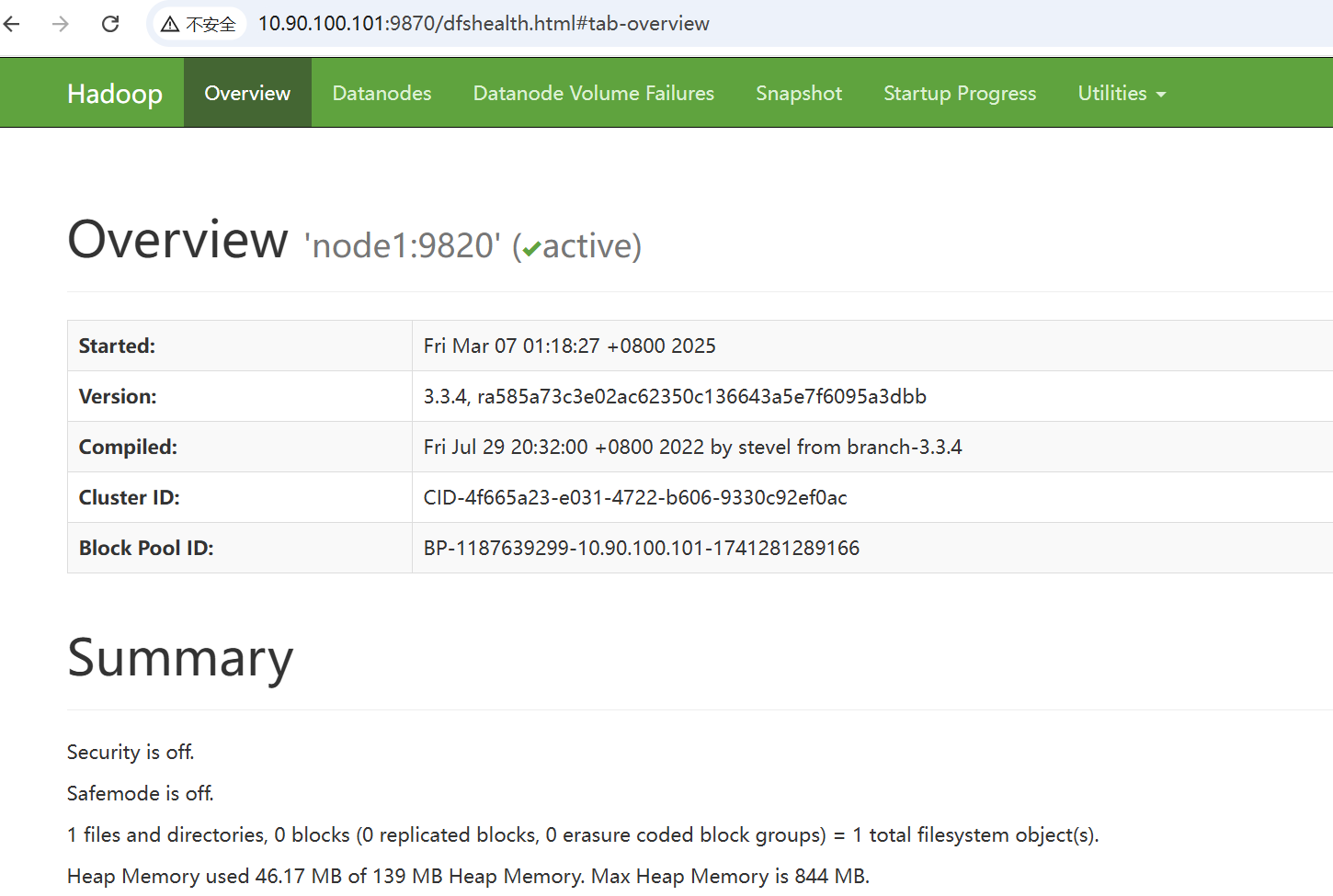
分别在集群的主机node1、
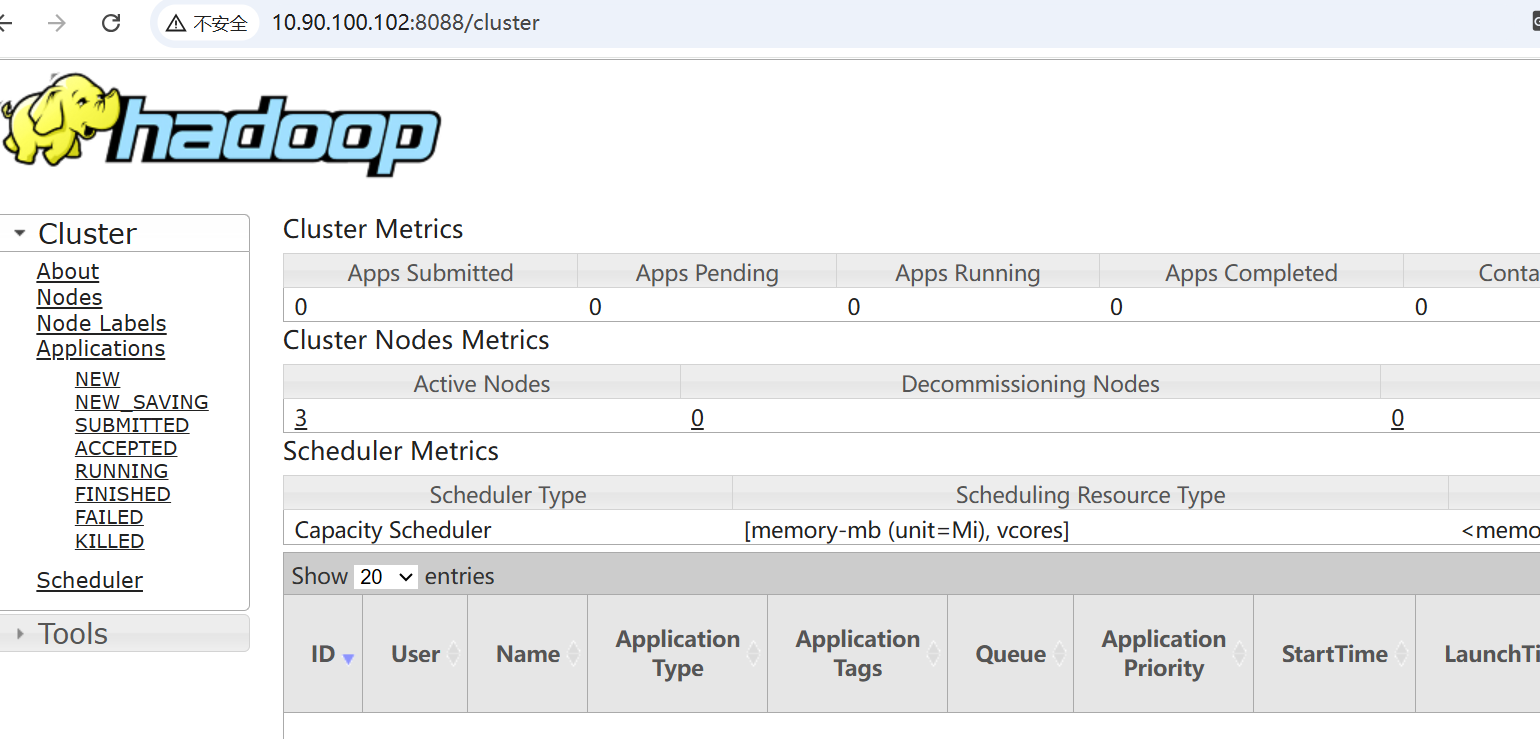
3.2 配置Hadoop 集群
- 核心配置文件
配置core-site.xml
[hadoop@node1 software]$ cd$HADOOP_HOME/etc/hadoop[hadoop@node1 hadoop]$ vimcore-site.xml配置后完整内容如下:
<?xml version="1.0" encoding="UTF-8"?><?xml-stylesheet type="text/xsl" href="configuration.xsl"?><configuration><!-- 指定NameNode的地址 --><property><name>fs.defaultFS</name><value>hdfs://node1:9820</value></property><!-- 指定hadoop数据的存储目录 --><property><name>hadoop.tmp.dir</name><value>/opt/software/hadoop-3.3.4/data</value></property><!-- 配置HDFS网页登录使用的静态用户为hadoop --><property><name>hadoop.http.staticuser.user</name><value>hadoop</value></property><!-- 配置该hadoop(superUser)允许通过代理访问的主机节点 --><property><name>hadoop.proxyuser.hadoop.hosts</name><value>*</value></property><!-- 配置该hadoop(superUser)允许通过代理用户所属组 --><property><name>hadoop.proxyuser.hadoop.groups</name><value>*</value></property><!-- 配置该hadoop(superUser)允许通过代理的用户--><property><name>hadoop.proxyuser.hadoop.users</name><value>*</value></property></configuration>- 配置hdfs-site.xml
[hadoop@node1 hadoop]$ vimhdfs-site.xml 配置后完整内容如下:
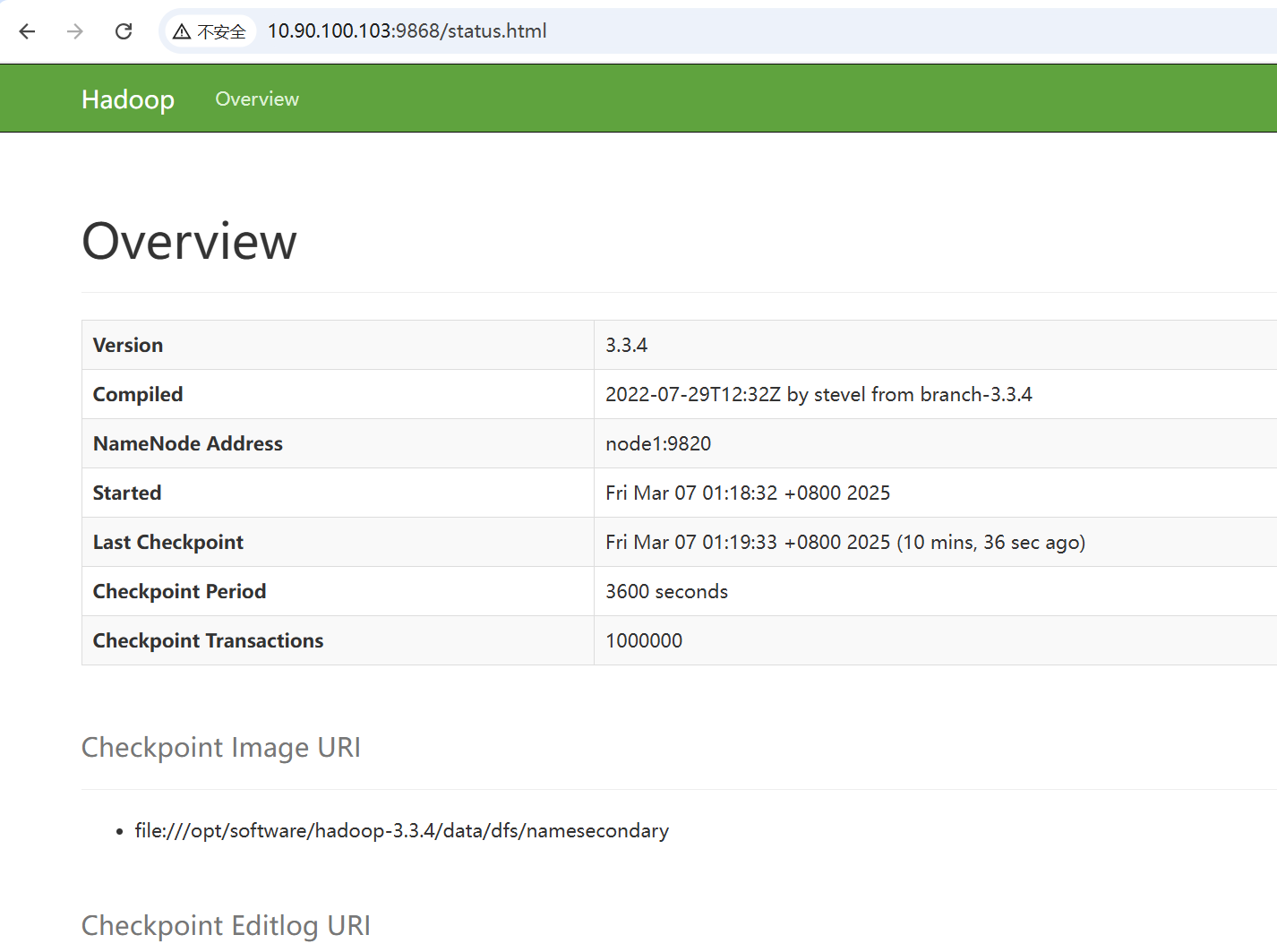
<?xml version="1.0" encoding="UTF-8"?><?xml-stylesheet type="text/xsl" href="configuration.xsl"?><configuration><!-- nn web端访问地址--><property><name>dfs.namenode.http-address</name><value>node1:9870</value></property><!-- 2nn web端访问地址--><property><name>dfs.namenode.secondary.http-address</name><value>node3:9868</value></property></configuration>- 配置yarn-site.xml
[hadoop@node1 hadoop]$ vimyarn-site.xml配置后完整内容如下:
<?xml version="1.0"?><configuration><!-- 指定MR走shuffle --><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><!-- 指定ResourceManager的地址--><property><name>yarn.resourcemanager.hostname</name><value>node2</value></property><!-- 环境变量的继承 --><property><name>yarn.nodemanager.env-whitelist</name><value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value></property><!-- yarn容器允许分配的最大最小内存 --><property><name>yarn.scheduler.minimum-allocation-mb</name><value>512</value></property><property><name>yarn.scheduler.maximum-allocation-mb</name><value>2048</value></property><!-- yarn容器允许管理的物理内存大小 --><property><name>yarn.nodemanager.resource.memory-mb</name><value>2048</value></property><!-- 关闭yarn对物理内存和虚拟内存的限制检查 --><property><name>yarn.nodemanager.pmem-check-enabled</name><value>false</value></property><property><name>yarn.nodemanager.vmem-check-enabled</name><value>false</value></property></configuration>- 配置mapred-site.xml
[hadoop@node1 hadoop]$ vimmapred-site.xml 配置后完整内容如下:
<?xml version="1.0"?><?xml-stylesheet type="text/xsl"href="configuration.xsl"?><configuration><!-- 指定MapReduce程序运行在Yarn上 --><property><name>mapreduce.framework.name</name><value>yarn</value></property></configuration>- 配置workers
[hadoop@node1 hadoop]$ vimworkers把原有的内容替换成如下内容:
node1node2node3注意:该文件中添加的内容结尾不允许有空格,文件中不允许有空行。修改所属用户的命令如下:
[hadoop@node1 ~]$ sudochownhadoop:hadoop -R/opt/software#验证所属用户是否修改成功[hadoop@node1 ~]$ cd/opt[hadoop@node1 opt]$ ll总计 8drwxr-xr-x. 4root root 40962025年 3月 7日 patch_workspacedrwxr-xr-x. 2hadoop hadoop 40963月 6日 23:33 software#所属用户已经是hadoop- 建立JDK 软链接,以方便后续使用,操作命令如下。相关操作命令如下:
- 查看进程操作
[hadoop@node1 ~]$ hdp.sh jps- 启动集群
[hadoop@node1 ~]$ hdp.sh start- 停止集群
[hadoop@node1 ~]$ hdp.sh stop