
发布时间:2025-06-24 20:03:32 作者:北方职教升学中心 阅读量:397
图片、辅助编码等通用能力,但限于其预训练时使用有限知识,难以有效应对互联网平台源源不断涌现的海量知识。因此,常见的做法是使用数据库存储问答等语料并为大语言模型提供语料检索,即RAG。文本总结、
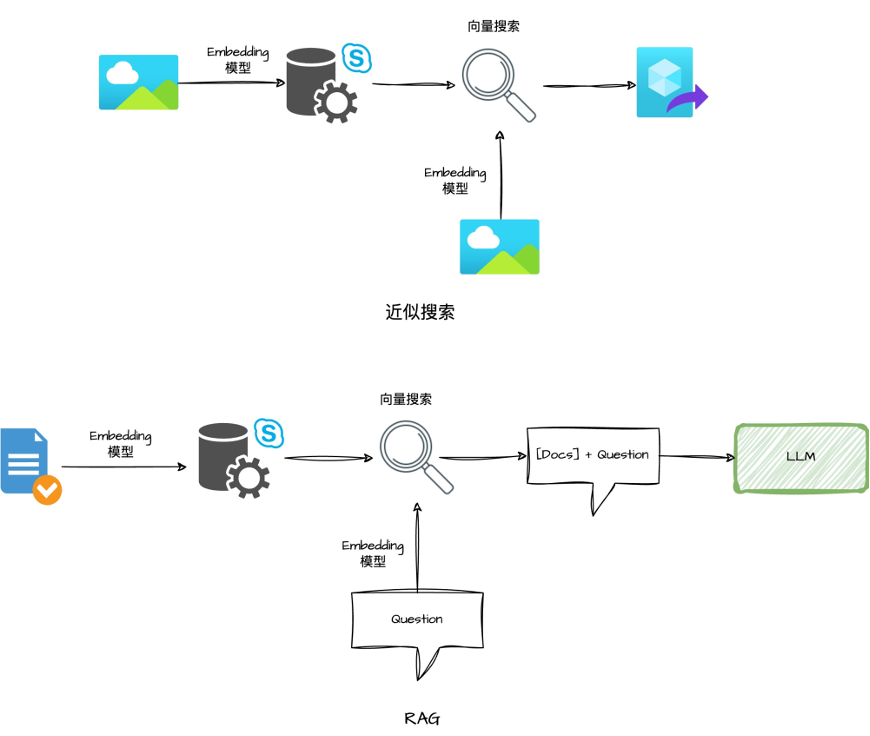
这意味着在海量存储和高效检索这两个场景下,OceanBase用户将获得更低的存储成本、 可以选择任意的分类图片库作为数据集,本文演示资料是从如下链接下载: 极市开发者平台-计算机视觉算法开发落地平台-极市科技 这个图片库中的图片大小不一,对于传统的机器学习应用来说需要统一图片大小,不过我们使用embedding模型进行向量搜索的方式并不需要。CLIP模型可以使用 然后,简单调用一下即可获取向量: 最后将整个pipeline组合起来,将图片库中的所有图片转为向量,再插入OceanBase中。它利用大语言模型(LLM,简称大模型)的嵌入(embedding)技术,将非结构化数据转换为向量数据并存储于数据库系统中。 这些能力得以让OceanBase成为上述两种AI应用架构的存储基座,下面按照近似搜索应用架构,以一个简单的图搜图应用来展示OceanBase的向量存储能力。支持更多向量操作函数及向量检索算法、近似搜索2. 处理图片数据
towhee库进行下载:import osimport shutilfrom towhee import ops,pipe,AutoPipes,AutoConfig,DataCollectionimg_pipe = AutoPipes.pipeline('text_image_embedding')def img_embedding(path): return img_pipe(path).get()[0]
近似搜索场景包括但不限于:
- 搜索推荐;
- 数据分类、通过数据库系统提供的向量运算和近似度查询功能,实现搜索推荐和非结构化数据查询的应用场景。
二、
5. 图片导入OceanBase
我们使用CLIP模型来将图片转为向量。
ob_insert_img2img:向向量数据表插入向量数据;ob_ann_search:用于执行向量近似最邻近查询并计算查询耗时。最后通过gallery组件展示图片:# Gradio 界面import gradio as grimport osimport IPython.display as displayimport imageio# Gradio界面的主要逻辑函数def show_search_results(image, topk): if not os.path.exists("uploads"): os.makedirs("uploads") # 保存上传的图片到临时目录并获取其路径 if image is not None: temp_image_path = os.path.join("uploads", "uploaded_image.jpg") imageio.imsave(temp_image_path, image) # 调用图搜索函数 query_vec = img_embedding(temp_image_path) res = ob_ann_search("<~>", query_vec, topk) result_paths = [r.path for r in res] return result_paths return []# 创建Gradio UIiface = gr.Interface(fn=show_search_results, inputs=[gr.Image(label="上传图片"), gr.Slider(1, 10, step=1, label="Top K")], outputs=gr.Gallery(label="搜索结果图片"), examples=[])# 在Jupyter Notebook内运行Gradio应用iface.launch()简单测试一下,可以发现原图被精确地查找了出来:
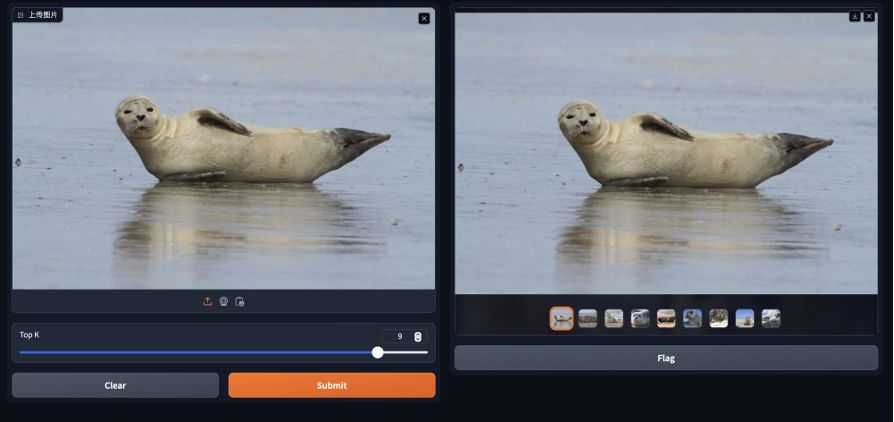
而相关图片中都是“海豹”!
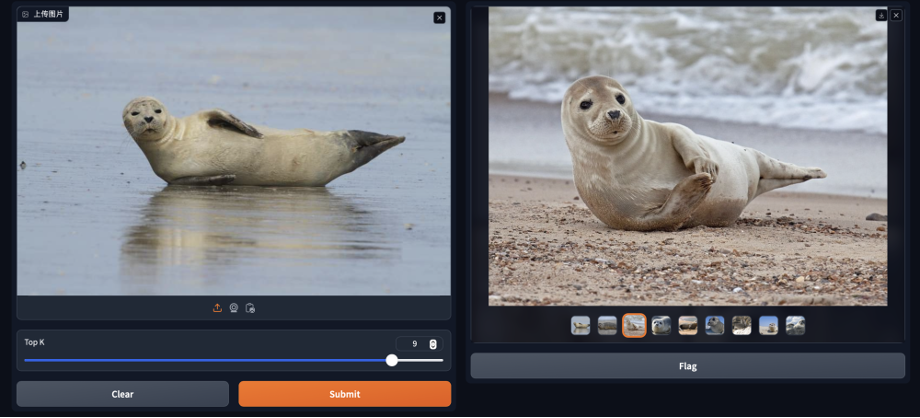
7. 创建一个向量索引会如何?
开启一个MySQL连接,创建一个ivfflat索引:
obclient [test]> create index vidx on img2img (embedding l2) using ivfflat;Query OK, 0 rows affected (11.129 sec)创建索引前耗时39ms,而在利用向量索引进行查询优化后,仅7.6ms就响应了Top 9的结果:


拥抱AI,强化向量功能
OceanBase分布式数据库-海量数据 笔笔算数
- 依靠OceanBase的分布式存储引擎,提供海量向量数据存储能力;
- 扩展OceanBase分区并行执行能力,提供高效的向量近似检索能力。特殊处理一下第一次插入,需要额外执行向量数据表的创建:
# 将图片转换为 embedding 向量后导入 OceanBase Vector DataBasedef import_all_imgs(img_dir): embedding_dim = -1 first_embedding = True imgs = os.listdir(img_dir) for i in range(len(imgs)): path = os.path.join(img_dir, imgs[i]) vec = img_embedding(path) if first_embedding: embedding_dim = len(vec.tolist()) ob_create_img2img(embedding_dim) first_embedding = False if embedding_dim != len(vec.tolist()): print(f"dim mismatch!! ---- expect: {embedding_dim} while get {len(vec.tolist())}") break ob_insert_img2img(embedding_dim, vec, path) if i % 100 == 0: print(f"{i} vectors inserted...") print("import finish")dest_dir = "/your/image/dest/dir"import_all_imgs(dest_dir)导入完成后,开启一个MySQL连接,可以看到导入了5399条维度为512的向量:
obclient [test]> show create table img2img\G*** 1. row *** Table: img2imgCreate Table: CREATE TABLE `img2img` ( `id` int(11) NOT NULL, `embedding` vector(512) DEFAULT NULL, `path` varchar(1024) NOT NULL, PRIMARY KEY (`id`), KEY `vidx` (`embedding`) BLOCK_SIZE 16384 LOCAL) DEFAULT CHARSET = utf8mb4 ROW_FORMAT = DYNAMIC COMPRESSION = 'zstd_1.3.8' REPLICA_NUM = 1 BLOCK_SIZE = 16384 USE_BLOOM_FILTER = FALSE TABLET_SIZE = 134217728 PCTFREE = 01 row in set (0.002 sec)obclient [test]> select count(*) from img2img;+----------+| count(*) |+----------+| 5399 |+----------+1 row in set (0.021 sec)6. 启动图搜图小应用
我们使用
gradio库作为简易的WebUI,接受以下两个输入。图片上传组件:待查询的图片。检索增强生成。topK滑动组件:设定最邻近查询的topK值。更快的查询速度和更精确的查询结果。目前OceanBase可以初步支持近似搜索和搜索增强两个典型应用场景。大模型具备自然语言对话、强化标量向量混合查询能力,以及提供更多的AI接口,比如支持matrix,能够直接使用SQL接口对图片进行一些变换操作。
查询时,首先将传入的图片写到临时路径,再将临时图片嵌入为向量,最后调用之前定义的
ob_ann_search函数获取最邻近图片路径列表。去重; - 用于生成式模型的向量输入,如风格迁移应用;
- ……
检索增强生成场景包括但不限于:
- 私有知识库问答;
- Text2SQL;
- ……
后续OceanBase将继续强化向量功能,包括但不限于简化ANN搜索的SQL语法、智能体Agent、支持GPU加速、视频信息具有距离接近的向量数值,这意味着用户在检索时更加灵活,即使使用相近的关键词也能得到精确的检索结果,节省检索成本并提高检索效率。
一、
在OceanBase社区版的4.3版本中,率先支持了向量数据库的基本能力:
- 支持向量数据类型(VECTOR关键字)定义以及存储;
- 支持向量数据列创建向量近似邻近搜索(ANN)索引,目前支持IVFFLAT以及HNSW两种算法;
- 支持分区并行构建向量近似邻近搜索索引;
- 支持分区并行执行向量近似邻近搜索。
OceanBase向量存储能力演示
1. 部署OceanBase向量数据库Docker镜像
通过以下命令安装OceanBase向量数据库:
docker run -p 2881:2881 --name obvec -d oceanbase/oceanbase-ce:vector等待docker容器输出
“boot success!”之后,我们可以用SQL接口试玩一下OceanBase的向量处理能力:obclient [test]> create table t1 (c1 vector(3), c2 int, c3 float, primary key (c2));Query OK, 0 rows affected (0.128 sec)obclient [test]> insert into t1 values ('[1.1, 2.2, 3.3]', 1, 1.1), ('[ 9.1, 3.14, 2.14]', 2, 2.43), ('[7576.42, 467.23, 2913.762]', 3, 54.6), ('[3,1,2]', 4, 4.67), ('[42.4,53.1,5.23]', 5, 423.2), ('[ 3.1, 1.5, 2.12]', 6, 32.1), ('[4,6,12]', 7, 23), ('[2.3,66.77,34.35]', 8, 67), ('[0.43,8.342,0.43]', 9, 67), ('[9.99,23.2,5.88]', 10, 67),('[23.5,76.5,6.34]',11,11);Query OK, 11 rows affected (0.011 sec)Records: 11 Duplicates: 0 Warnings: 0obclient [test]> CREATE INDEX vidx1_c1_t1 on t1 (c1 l2) using hnsw;Query OK, 0 rows affected (0.315 sec)obclient [test]> select * from t1;+--------------------------------------+----+-------+| c1 | c2 | c3 |+--------------------------------------+----+-------+| [1.100000,2.200000,3.300000] | 1 | 1.1 || [9.100000,3.140000,2.140000] | 2 | 2.43 || [7576.419922,467.230011,2913.761963] | 3 | 54.6 || [3.000000,1.000000,2.000000] | 4 | 4.67 || [42.400002,53.099998,5.230000] | 5 | 423.2 || [3.100000,1.500000,2.120000] | 6 | 32.1 || [4.000000,6.000000,12.000000] | 7 | 23 || [2.300000,66.769997,34.349998] | 8 | 67 || [0.430000,8.342000,0.430000] | 9 | 67 || [9.990000,23.200001,5.880000] | 10 | 67 || [23.500000,76.500000,6.340000] | 11 | 11 |+--------------------------------------+----+-------+11 rows in set (0.004 sec)obclient [test]> select c1,c2 from t1 order by c1 <-> '[3,1,2]' limit 2;+------------------------------+----+| c1 | c2 |+------------------------------+----+| [3.000000,1.000000,2.000000] | 4 || [3.100000,1.500000,2.120000] | 6 |+------------------------------+----+2 rows in set (0.013 sec)- 首先创建一个包含向量列
c1的向量数据表t1; - 插入向量数据,展示OceanBase向量数据常量值的定义方式;
- 在该向量数据表上创建
hnsw向量索引(也支持创建ivfflat索引); - 向量数据表全表扫描;
- 一个典型的向量近似最邻近查询(select XXX from XX order by XXX limit XX);
- <->:计算向量之间的欧式距离;
- <@>:计算向量之间的内积;
- <~>:计算向量之间的cosine距离。列表类型转为OceanBase向量常量类型的方法:
# OceanBase Vector DataBase import datetimefrom typing import Any, Callable, Iterable, List, Optional, Sequence, Tuple, Typefrom sqlalchemy import Column, String, Table, create_engine, insert, textfrom sqlalchemy.types import UserDefinedType, Float, Stringfrom sqlalchemy.dialects.mysql import JSON, LONGTEXT, VARCHAR, INTEGERtry: from sqlalchemy.orm import declarative_baseexcept ImportError: from sqlalchemy.ext.declarative import declarative_baseBase = declarative_base()def from_db(value): return [float(v) for v in value[1:-1].split(',')]def to_db(value, dim=None): if value is None: return value return '[' + ','.join([str(float(v)) for v in value]) + ']'class Vector(UserDefinedType): cache_ok = True _string = String() def __init__(self, dim): super(UserDefinedType, self).__init__() self.dim = dim def get_col_spec(self, **kw): return "VECTOR(%d)" % self.dim def bind_processor(self, dialect): def process(value): return to_db(value, self.dim) return process def literal_processor(self, dialect): string_literal_processor = self._string._cached_literal_processor(dialect) def process(value): return string_literal_processor(to_db(value, self.dim)) return process def result_processor(self, dialect, coltype): def process(value): return from_db(value) return process# 与 OceanBase Vector DataBase 建立连接ob_host = "127.0.0.1"ob_port = 2881ob_database = "test"ob_user = "root@test"ob_password = ""connection_str = f"mysql+pymysql://{ob_user}:{ob_password}@{ob_host}:{ob_port}/{ob_database}?charset=utf8mb4"ob_vector_db = create_engine(connection_str)OceanBase docker启动会自动创建一个test租户,并在本地2881端口开启MySQL服务,构造连接串后创建连接即可。唯一需要做的预处理操作是:图片库中的图片按照图片目录事先已做好归类,需要打散统一放到一个目录下:
import osimport shutildef copy_imgs(src, dest): if not os.path.exists(dest): os.makedirs(dest) for root, dirs, files in os.walk(src): for file in files: if file.endswith('.jpg'): src_file_path = os.path.join(root, file) dest_file_path = os.path.join(dest, file) shutil.copy2(src_file_path, dest_file_path)copy_imgs(src_dir, dest_dir)3. 使用Python连接OceanBase
我们使用
sqlalchemy库连接OceanBase,由于vector类型并不是mysql方言中支持的类型,需要定义一个Vector类,实现该类型从数据库类型转为python列表类型、此外,在AI应用中,相对于直接存储非结构化数据,存储非结构化数据Embedding后的向量数据具有两个优势:其一,数据更安全,非结构化数据对于数据库管理者不可见;其二,便于语义理解,向量近似搜索是一种从语义层面的检索方式,相似的文字、
- 首先创建一个包含向量列
