也可以pycharm直接安装
发布时间:2025-06-24 20:22:43 作者:北方职教升学中心 阅读量:360
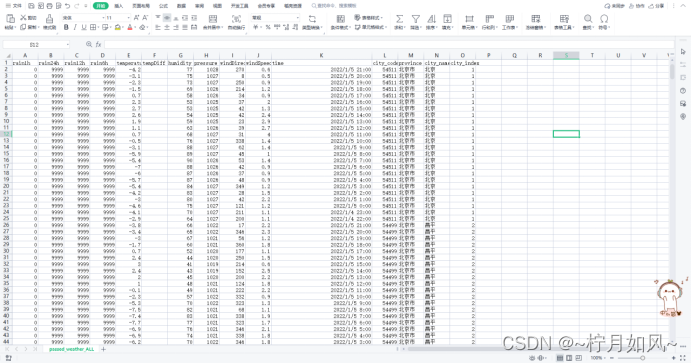
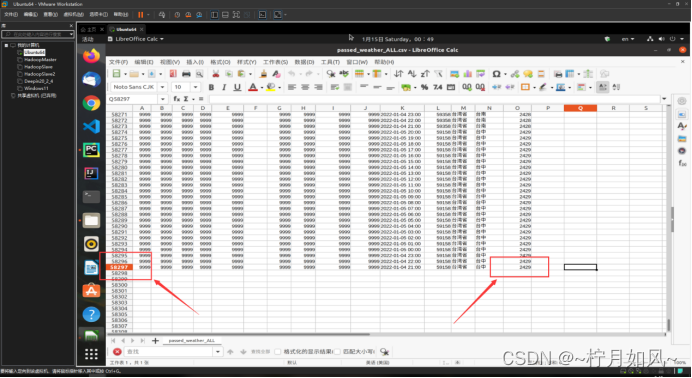
字段 含义
province 城市所在省份(中文)
city_index 城市序号(计数)
city_name 城市名称(中文)
city_code 城市编号
time 时间点(整点)
temperature 气温
rain1h 过去1小时降雨量
6.爬虫过程截图
开始爬虫
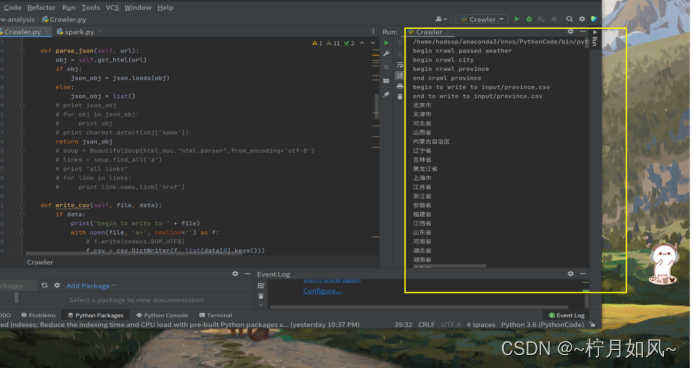
运行中的截图:
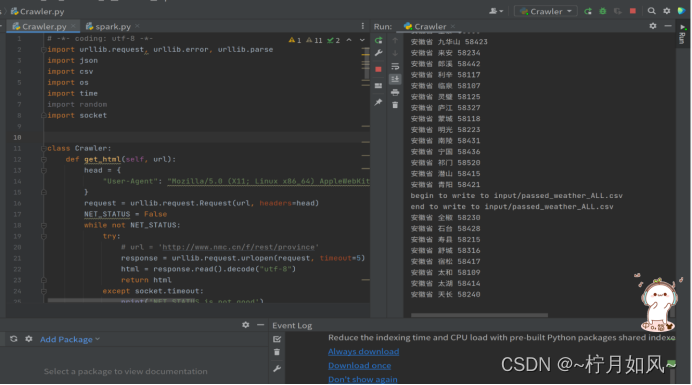
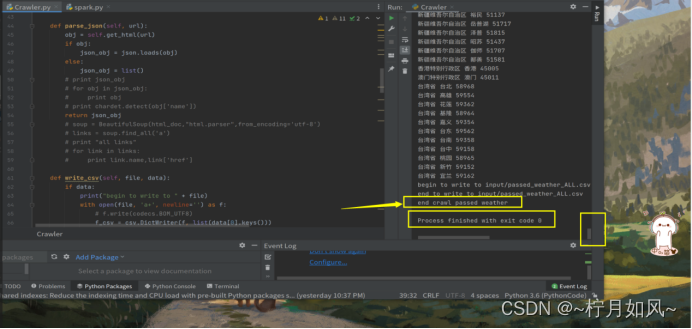
爬取完毕:
四、
第三步,配置横轴坐标位置,设置纵轴坐标范围
第四步,配置横纵坐标标签
第五步,配置每个条形图上方显示的数据
第六步,根据上述配置,画出直方图。
相关步骤如下:
(1)创建SparkSession对象spark;
(2)使用spark.read.csv(filename)读取passed_weather_ALL.csv数据生成Dateframe df;
(3)对df进行操作:使用Dateframe的select方法选择province,city_name,city_code,temperature字段,并使用库pyspark.sql.functions中的date_format(col,pattern)方法和hour(col)将time字段转换成date(日期)字段和hour(小时)字段,(time字段的分秒信息无用),,得到新的Dateframe df_temperature;
(4)对df_temperature进行操作:使用Dateframe的filter操作过滤出hour字段在[2,8,14,20]中的记录,经过上述操作得到新的Dateframe df_4point_temperature
(5)对df_4point_temperature进行操作:使用Dateframe的groupBy操作按照province,city_name,city_code,date字段分组,使用agg方法对temperature字段进行分组计数和求和(求和字段命名为avg_temperature),使用filter方法过滤出分组计数为4的记录(确保有4个时次才能计算日平均温),使用sort方法按照avg_temperature降序排列,再筛选出需要保存的字段province,city_name,city_code,date,avg_temperature(顺便使用库pyspark.sql.functions中的format_number(col,precision)方法保留一位小数),经过上述操作得到新的Dateframe df_avg_temperature
(6)对df_avg_temperature调用cache()方法将此前的转换关系进行缓存,提高性能
(7)对df_avg_temperature调用coalesce()将数据分区数目减为1,并使用write.json(filename)方法将得到的数据持久化到本地文件。
画图部分对应的运行截图如下:
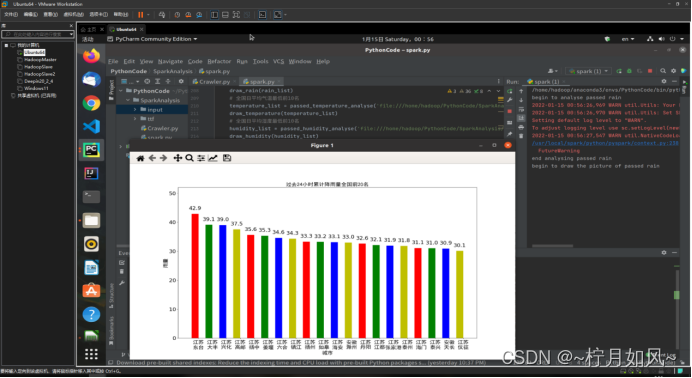
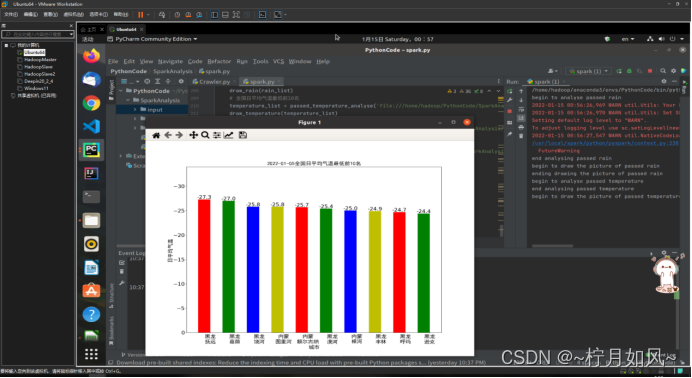
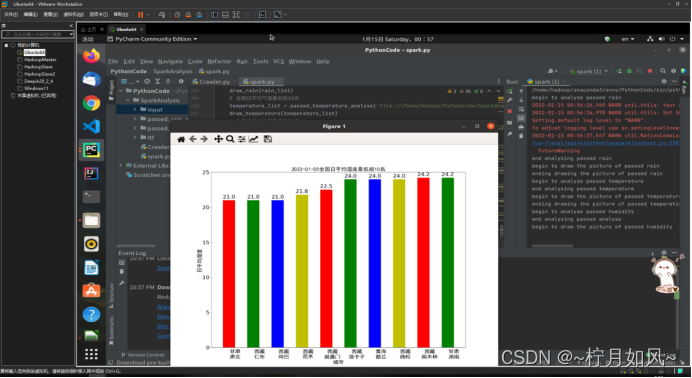

保存的matplotlib作的图:
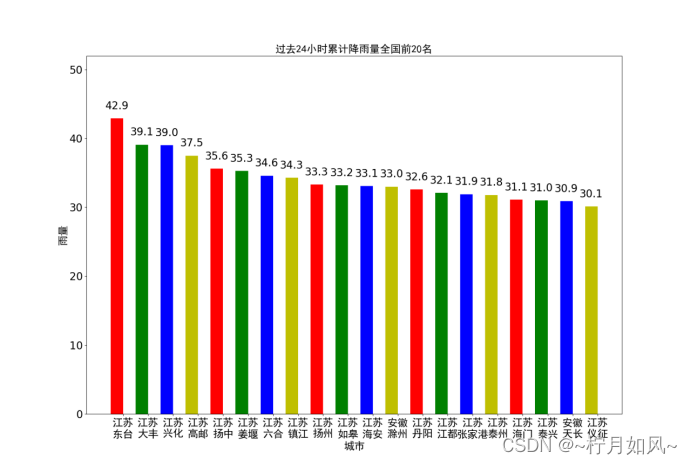
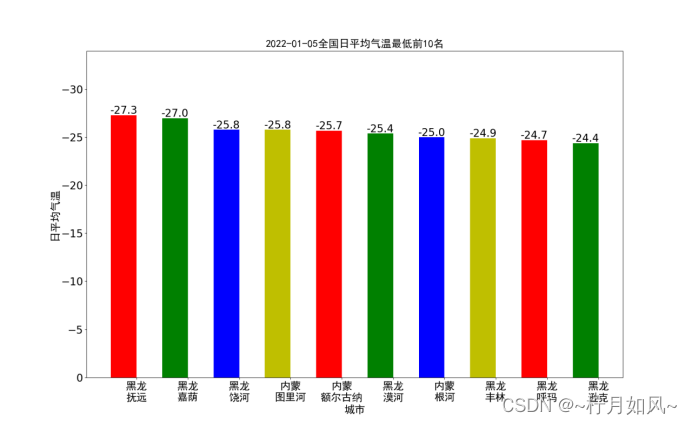
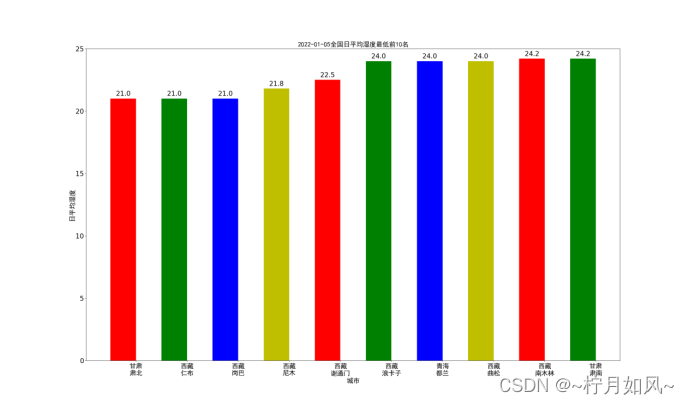
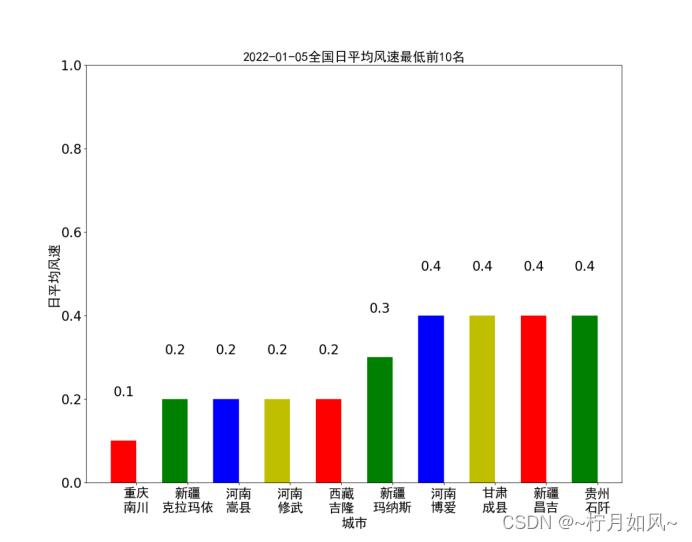
六、否则坐标轴等出现中文的地方是乱码。唯一需要注意的是,有些城市可能不存在或者全部缺失最近24小时整点数据,需要进行过滤,以免出错。14时、求和、08时、源代码等
链接:https://pan.baidu.com/s/1ofcoqahctrHA04lXP4ihog?pwd=nyrf
提取码:nyrf
实验环境
(1)Linux: Ubuntu 20.04
(2)Python: 3.6
(3)Spark: 3.2.0
(4)pycharm
安装完上述环境以后,为了支持Python可视化分析,还需要执行如下命令安装新的组件:
二、数据获取
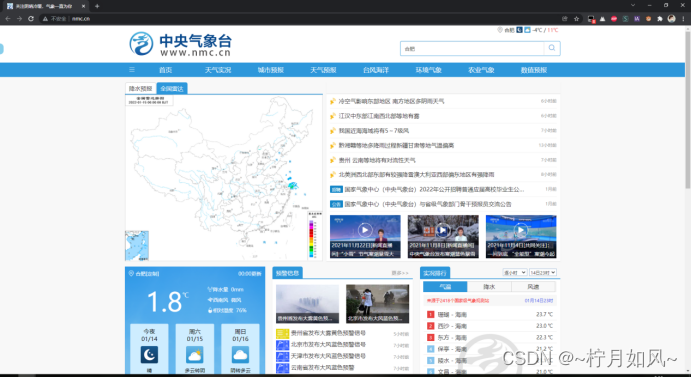
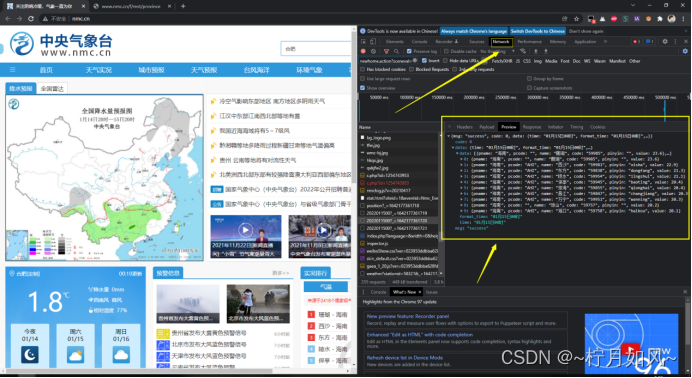
1.观察数据获取方式
打开中央气象台官方网站(网址:http://www.nmc.cn/),任意点击左侧栏“热点城市”中的一个城市。可使用pip命令安装。不需要像平常爬取HTML网页时还需要对网页源码进行解析,查找相关数据。
第二步,设置数据(累积雨量或者日平均气温)和横轴坐标(城市名称),配置直方图。排序df_rain_sum.cache()df_rain_sum.coalesce(1).write.csv("file:///home/hadoop/PythonCode/SparkAnalysis/passed_rain_analyse.csv")print("end analysing passed rain")returndf_rain_sum.head(20)defpassed_temperature_analyse(filename):print("begin to analyse passed temperature")spark =SparkSession.builder.master("local").appName("passed_temperature_analyse").getOrCreate()df =spark.read.csv(filename,header=True)df_temperature =df.select(df['province'],df['city_name'],df['city_code'],df['temperature'].cast(DecimalType(scale=1)),F.date_format(df['time'],"yyyy-MM-dd").alias("date"),F.hour(df['time']).alias("hour"))df_4point_temperature =df_temperature.filter(df_temperature['hour'].isin([2,8,12,20]))df_avg_temperature =df_4point_temperature.groupBy("province","city_name","city_code","date")\ .agg(F.count("temperature"),F.avg("temperature").alias("avg_temperature"))\ .filter("count(temperature) = 4")\ .sort(F.asc("avg_temperature"))\ .select("province","city_name","city_code","date",F.format_number('avg_temperature',1).alias("avg_temperature"))df_avg_temperature.cache()avg_temperature_list =df_avg_temperature.collect()df_avg_temperature.coalesce(1).write.json("file:///home/hadoop/PythonCode/SparkAnalysis/passed_temperature_analyse.json")print("end analysing passed temperature")returnavg_temperature_list[0:10]defpassed_humidity_analyse(filename):print("begin to analyse passed humidity")spark =SparkSession.builder.master("local").appName("passed_humidity_analyse").getOrCreate()df =spark.read.csv(filename,header=True)df_humidity =df.select(df['province'],df['city_name'],df['city_code'],df['humidity'].cast(DecimalType(scale=1)),F.date_format(df['time'],"yyyy-MM-dd").alias("date"),F.hour(df['time']).alias("hour"))df_4point_humidity =df_humidity.filter(df_humidity['hour'].isin([2,8,12,20]))df_avg_humidity =df_4point_humidity.groupBy("province","city_name","city_code","date")\ .agg(F.count("humidity"),F.avg("humidity").alias("avg_humidity"))\ .filter("count(humidity) = 4")\ .sort(F.asc("avg_humidity"))\ .select("province","city_name","city_code","date",F.format_number('avg_humidity',1).alias("avg_humidity"))df_avg_humidity.cache()avg_humidity_list =df_avg_humidity.collect()df_avg_humidity.coalesce(1).write.json("file:///home/hadoop/PythonCode/SparkAnalysis/passed_humidity_analyse.json")print("end analysing passed analyse")returnavg_humidity_list[0:10]defpassed_windSpeed_analyse(filename):print("begin to analyse passed windSpeed")spark =SparkSession.builder.master("local").appName("passed_windSpeed_analyse").getOrCreate()df =spark.read.csv(filename,header=True)df_windSpeed =df.select(df['province'],df['city_name'],df['city_code'],df['windSpeed'].cast(DecimalType(scale=1)),F.date_format(df['time'],"yyyy-MM-dd").alias("date"),F.hour(df['time']).alias("hour"))df_4point_windSpeed =df_windSpeed.filter(df_windSpeed['hour'].isin([2,8,12,20]))df_avg_windSpeed =df_4point_windSpeed.groupBy("province","city_name","city_code","date")\ .agg(F.count("windSpeed"),F.avg("windSpeed").alias("avg_windSpeed"))\ .filter("count(windSpeed) = 4")\ .sort(F.asc("avg_windSpeed"))\ .select("province","city_name","city_code","date",F.format_number('avg_windSpeed',1).alias("avg_windSpeed"))df_avg_windSpeed.cache()avg_windSpeed_list =df_avg_windSpeed.collect()df_avg_windSpeed.coalesce(1).write.json("file:///home/hadoop/PythonCode/SparkAnalysis/passed_windSpeed_analyse.json")print("end analysing passed windSpeed")returnavg_windSpeed_list[0:10]defdraw_rain(rain_list):print("begin to draw the picture of passed rain")font =FontProperties(fname='ttf/simhei.ttf')name_list =[]num_list =[]foritem inrain_list:name_list.append(item.province[0:2]+'\n'+item.city_name)num_list.append(item.rain24h)index =[i +0.25fori inrange(0,len(num_list))]rects =plt.bar(index,num_list,color=['r','g','b','y'],width=0.5)plt.xticks([i +0.25fori inindex],name_list,fontproperties=font,fontsize=20)plt.yticks(fontsize=20)plt.ylim(ymax=(int(max(num_list)+10)/100)*100,ymin=0)plt.xlabel("城市",fontproperties=font,fontsize=20)plt.ylabel("雨量",fontproperties=font,fontsize=20)plt.title("过去24小时累计降雨量全国前20名",fontproperties=font,fontsize=20)forrect inrects:height =rect.get_height()plt.text(rect.get_x()+rect.get_width()/2,height +1,str(height),ha="center",va="bottom",fontsize=20)plt.show()print("ending drawing the picture of passed rain")defdraw_temperature(temperature_list):print("begin to draw the picture of passed temperature")font =FontProperties(fname='ttf/simhei.ttf')name_list =[]num_list =[]date =temperature_list[0].date foritem intemperature_list:name_list.append(item.province[0:2]+'\n'+item.city_name)num_list.append(float(item.avg_temperature))index =[i +0.25fori inrange(0,len(num_list))]rects =plt.bar(index,num_list,color=['r','g','b','y'],width=0.5)plt.xticks([i +0.25fori inindex],name_list,fontproperties=font,fontsize=20)plt.yticks(fontsize=20)plt.ylim(ymax=math.ceil(float(max(num_list)))-10,ymin=0)plt.xlabel("城市",fontproperties=font,fontsize=20)plt.ylabel("日平均气温",fontproperties=font,fontsize=20)plt.title(date +"全国日平均气温最低前10名",fontproperties=font,fontsize=20)forrect inrects:height =rect.get_height()plt.text(rect.get_x()+rect.get_width()/2,height +0.1,str(height),ha="center",va="bottom",fontsize=20)plt.show()print("ending drawing the picture of passed temperature")defdraw_humidity(humidity_list):print("begin to draw the picture of passed humidity")font =FontProperties(fname='ttf/simhei.ttf')name_list =[]num_list =[]date =humidity_list[0].date foritem inhumidity_list:name_list.append(item.province[0:2]+'\n'+item.city_name)num_list.append(float(item.avg_humidity))index =[i +0.25fori inrange(0,len(num_list))]rects =plt.bar(index,num_list,color=['r','g','b','y'],width=0.5)plt.xticks([i +0.25fori inindex],name_list,fontproperties=font,fontsize=20)plt.yticks(fontsize=20)plt.ylim(ymax=math.ceil(float(max(num_list))),ymin=0)plt.xlabel("城市",fontproperties=font,fontsize=20)plt.ylabel("日平均湿度",fontproperties=font,fontsize=20)plt.title(date +"全国日平均湿度最低前10名",fontproperties=font,fontsize=20)forrect inrects:height =rect.get_height()plt.text(rect.get_x()+rect.get_width()/2,height +0.1,str(height),ha="center",va="bottom",fontsize=20)plt.show()print("ending drawing the picture of passed humidity")defdraw_windSpeed(windSpeed_list):print("begin to draw the picture of passed windSpeed")font =FontProperties(fname='ttf/simhei.ttf')name_list =[]num_list =[]date =windSpeed_list[0].date foritem inwindSpeed_list:name_list.append(item.province[0:2]+'\n'+item.city_name)num_list.append(float(item.avg_windSpeed))index =[i +0.25fori inrange(0,len(num_list))]rects =plt.bar(index,num_list,color=['r','g','b','y'],width=0.5)plt.xticks([i +0.25fori inindex],name_list,fontproperties=font,fontsize=20)plt.yticks(fontsize=20)plt.ylim(ymax=math.ceil(float(max(num_list))),ymin=0)plt.xlabel("城市",fontproperties=font,fontsize=20)plt.ylabel("日平均风速",fontproperties=font,fontsize=20)plt.title(date +"全国日平均风速最低前10名",fontproperties=font,fontsize=20)forrect inrects:height =rect.get_height()plt.text(rect.get_x()+rect.get_width()/2,height +0.1,str(height),ha="center",va="bottom",fontsize=20)plt.show()print("ending drawing the picture of passed windSpeed")defmain():sourcefile ="input/passed_weather_ALL.csv"ifnotos.path.exists(sourcefile):crawler =Crawler()crawler.run('ALL')rain_list =passed_rain_analyse('file:///home/hadoop/PythonCode/SparkAnalysis/'+sourcefile)draw_rain(rain_list)temperature_list =passed_temperature_analyse('file:///home/hadoop/PythonCode/SparkAnalysis/'+sourcefile)draw_temperature(temperature_list)humidity_list =passed_humidity_analyse('file:///home/hadoop/PythonCode/SparkAnalysis/'+sourcefile)draw_humidity(humidity_list)windSpeed_list =passed_windSpeed_analyse('file:///home/hadoop/PythonCode/SparkAnalysis/'+sourcefile)draw_windSpeed(windSpeed_list)if__name__ =='__main__':main()
附录:csv文件、数据可视化
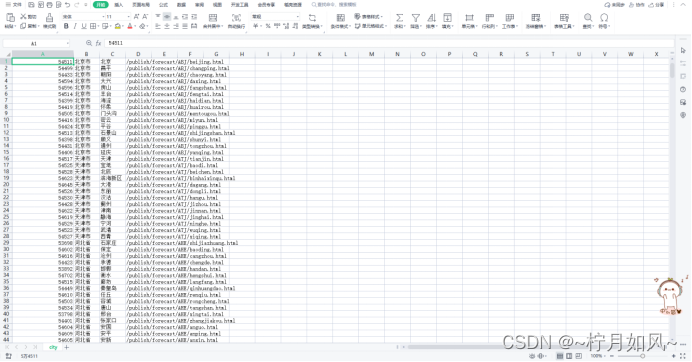
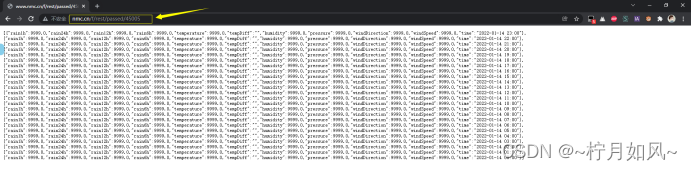
六、实验数据介绍本次实验所采用的数据,从中央气象台官方网站(网址:http://www.nmc.cn/)爬取,主要是最近24小时各个城市的天气数据,包括时间点(整点)、由于所有城市过去24小时整点天气数据数量太多,为了避免内存不足,每爬取50个城市的数据后,就会进行一次保存。源代码等
本实验采用Python语言,从网页爬取气象数据,并使用大数据处理框架Spark对气象数据进行处理分析,并对分析结果进行可视化。各个城市最近24小时整点天气数据(passed_weather_ALL.csv)。
(7)对df_rain_sum调用head()方法取前若干条数据(即24小时累积降水量Top-N的列表)供数据可视化使用。打开火狐(Firefox)浏览器或者谷歌(chrome)浏览器的Web控制台。风力、