
1、安装llama.CPP所需的环境
发布时间:2025-06-24 18:00:14 作者:北方职教升学中心 阅读量:969
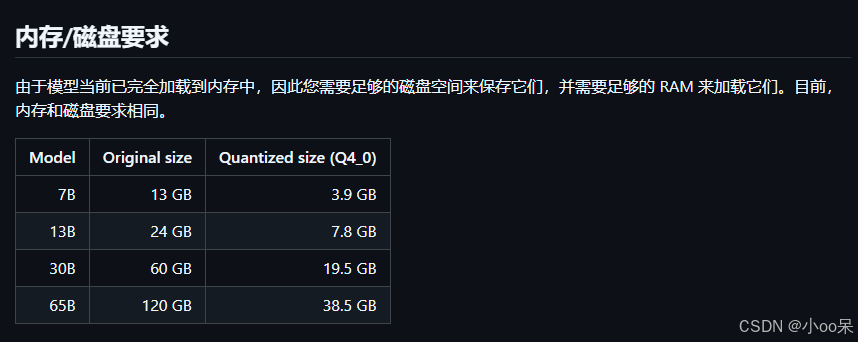
量化前后模型性能和参数规模的bian列在表中。
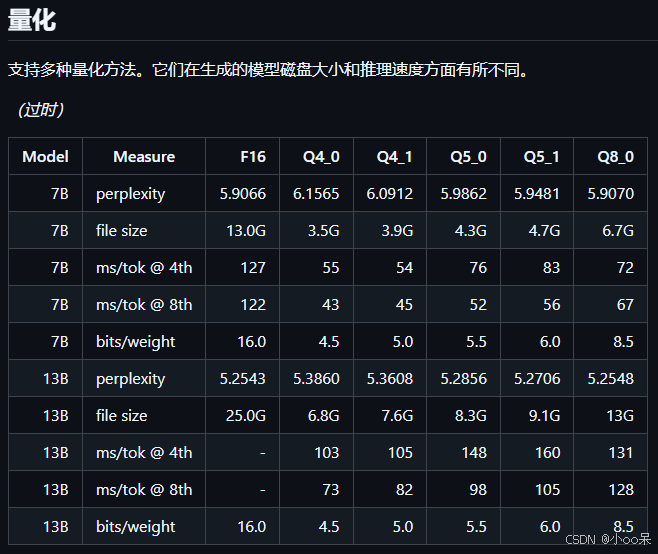
【注】 llama.cpp还提供了更多的量化格式转换,说明可见下表:
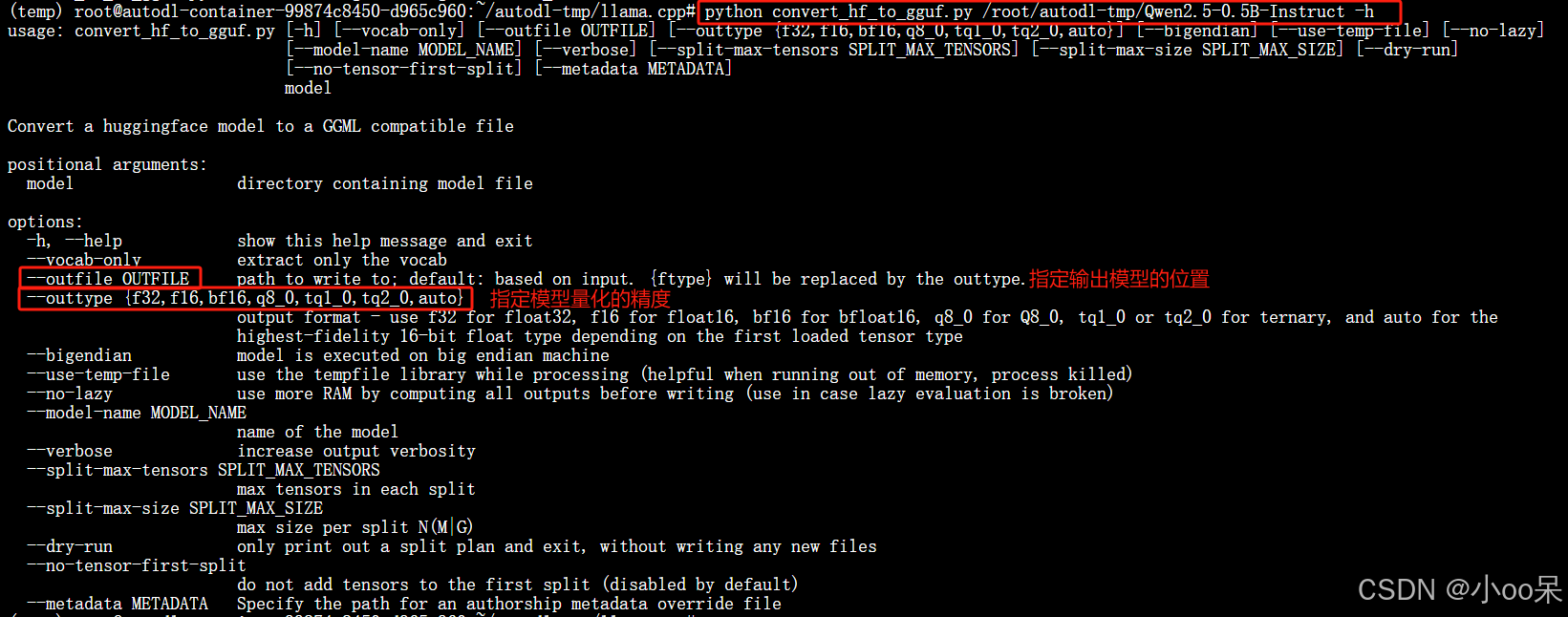

2、下载llama.cpp。1、安装llama.CPP所需的环境。
llama.CPP的主要目标是以最小的设置和最先进的性能在本地和云中实现LLM推理。
4、
pip install -r requirements.txt。一、除了将大模型转换为FP16的量化精度外,

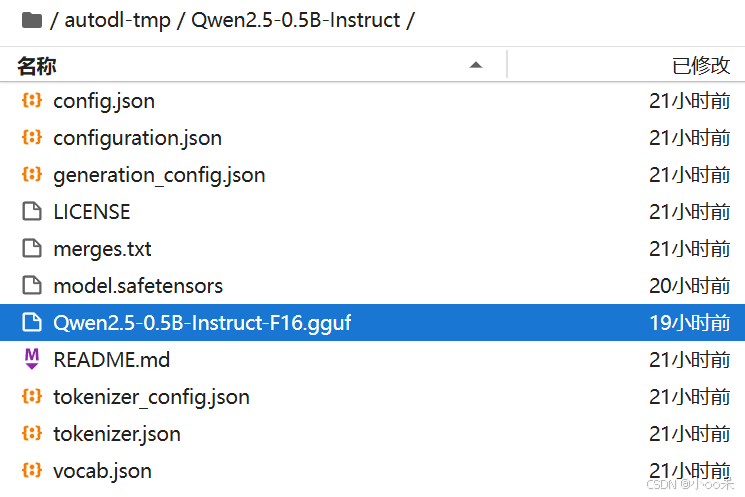
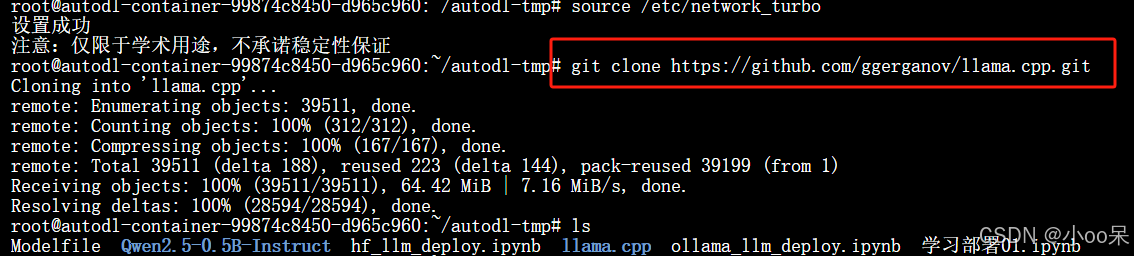
git clone https://github.com/ggerganov/llama.cpp.git。成功转换模型格式后,,也可以做Q8_0量化(等)并导出GGUF格式。
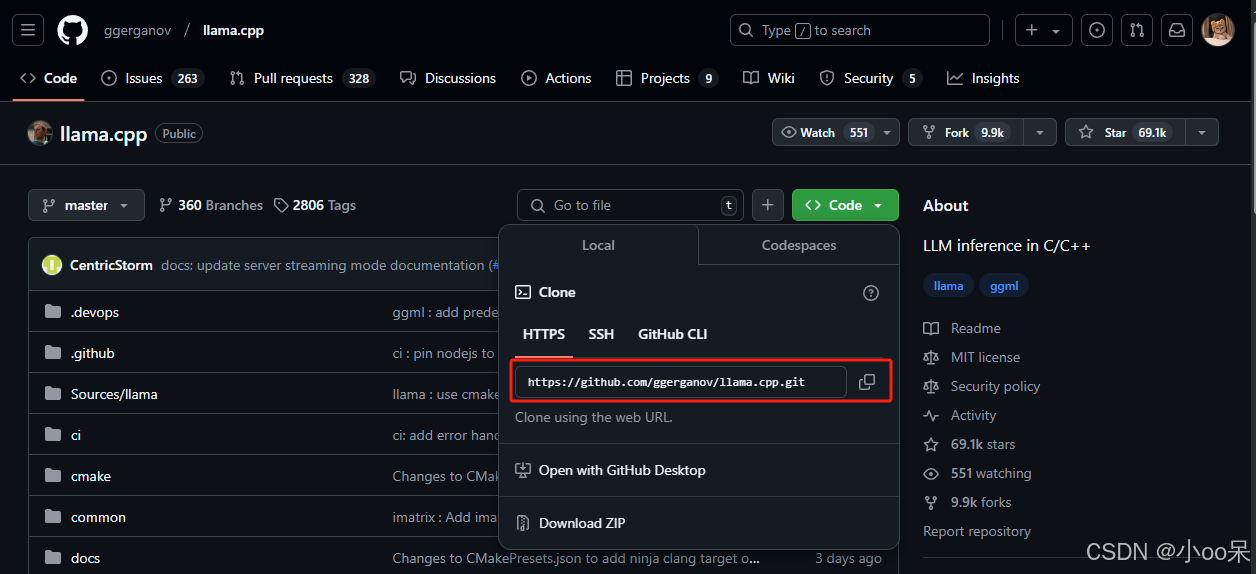
二是将大模型从HF格式转换为GGUF格式。访问GitHub官方仓库:llama.cpp。
2、它是一种大型语言模型(LLM)高性能推理框架设计,C和C+完全使用;+编写,没有外部依赖,这使得它很容易被移植到不同的操作系统和硬件平台上。
3、在llama.convert_cp项目路径hf_to_gguf.py文件。
# 将模型量化为8位(使用Q8_0方法)python convert_hf_to_gguf.py <您的模型所在路径> --outtype q8_0 --outfile <希望保存的路径>

如果在转换格式时指定量化参数,所以llama.cpp还将帮助您量化,以下是官方给出的Q4_0量化模型对比:
llama.cpp不仅支持4位量化,还支持以下多种量化。执行命令格式转换(GGUF)默认将模型转换为FP16;
python3 convert_hf_to_gguf.py <您模型所在的路径>
3、会提示GGUF格式模型保存在哪里。简化大型语言模型的部署过程。
如果你想用其他方法安装(例如Docker༉,参考官方仓库的以下部分。克隆仓库在您的服务器指定路径下。
1、

