CVPR2025国际学术会议中国实时人像视频生成研究成果入选CVPR
封面新闻记者 欧阳宏宇。
近日,IEEE国际计算机视觉与模式识别会议( Conference on Computer Vision and Pattern Recognition)CVPR 2025年发表论文录用结果,其中一篇来自中国的论文将AI应用于社交平台案例研究《Teller: Real-Time Streaming Audio-Driven Portrait Animation with Autoregressive Motion Generation》(基于自回归动作生成的实时流式音频驱动人像动画系统)被接收。
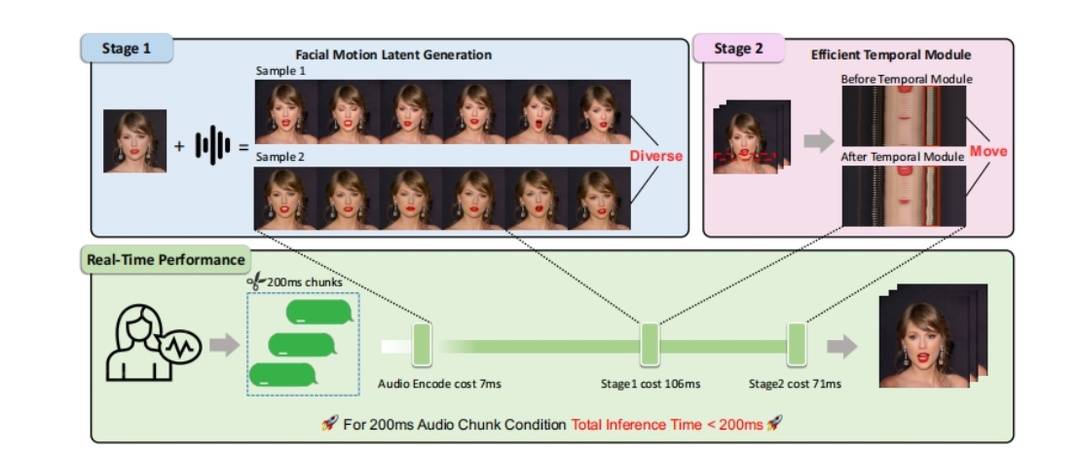
据报道,研究小组在论文中提出了一个新的实时音频驱动肖像动画(即Talking) Head)自回归框架不仅解决了视频屏幕生成耗时的行业挑战,而且实现了说话时头部生成和人体各部位运动的自然性和现实性。
该论文的动机是解构diffusion-base模型的关键步骤,重构LLM和1step-diffusion,集成视频模式,使soulx大模型成为同时生成文本、语音和视频的unified Model。
具体来说,Soul来自Soul app的研究团队将talking head任务分为FMLG(面部Motion生成)、ETM(高效身体Movement生成)模块。FMLG基于自回归语言模型,利用大模型强大的学习能力和高效的多样性采样能力,生成准确多样的面部Motion。另一方面,ETM利用一步扩散来产生逼真的身体肌肉、饰品的运动效果。
实验结果表明,与扩散模型相比,该方案的视频生成效率显著提高,在生成质量、微妙动作、面部身体动作协调性和自然性方面表现良好。这证明了国内社会领域的互联网技术在促进多模态能力建设,特别是视觉能力突破方面取得了阶段性成果。
谈到研究团队关注的视觉交互逻辑,该平台首席技术官陶明解释说,从交互信息的复杂性来看,人与人之间的面对面交流是最快、最有效的信息传播方式。“因此,我们认为在网上人机交互的过程中,需要有这样的表达方式。”。
在他看来,该方案的提出将有助于人工智能构建实时生成的“数字世界”,并能够以生动的数字形象与用户自然互动。
根据公开信息,CVPR是人工智能领域最具学术影响力的顶级会议之一,也是中国计算机学会(CCF)推荐A类国际学术会议。CVPR在2024年谷歌学术指标列出的世界上最具影响力的科学期刊/会议中排名第二,仅次于Nature。根据会议的官方统计,这次CVPR 2025年会议总共投稿13008篇,录用2878篇,录用率仅为22.1%。
本文地址:http://cdn.baiduyun.im/video/www.bfzx365.com/video/972b40698621.html
版权声明
本文仅代表作者观点,不代表本站立场。
本文系作者授权发表,未经许可,不得转载。