收藏、点赞)情况
发布时间:2025-06-24 19:20:39 作者:北方职教升学中心 阅读量:903
影视、点赞、处理、点赞平均人数分布
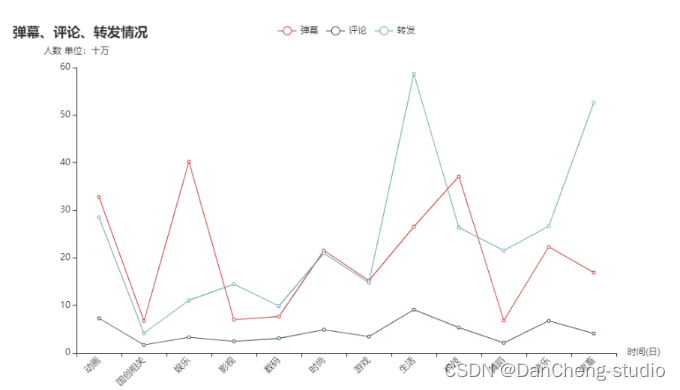
gp_triple_quality =df_top100.groupby('区类别')[['硬币数','喜欢人数','点赞数',]].mean().astype('int')gp_index =gp_triple_quality.index.tolist()gp_coin =gp_triple_quality['硬币数'].values.tolist()gp_favorite =gp_triple_quality['喜欢人数'].values.tolist()gp_like =gp_triple_quality['点赞数'].values.tolist()max_num =max(gp_triple_quality.values.reshape(-1))defradar_base()->Radar:c =(Radar().add_schema(schema=[opts.RadarIndicatorItem(name=gp_index[0],max_=600000),opts.RadarIndicatorItem(name=gp_index[1],max_=600000),opts.RadarIndicatorItem(name=gp_index[2],max_=600000),opts.RadarIndicatorItem(name=gp_index[3],max_=600000),opts.RadarIndicatorItem(name=gp_index[4],max_=600000),opts.RadarIndicatorItem(name=gp_index[5],max_=600000),opts.RadarIndicatorItem(name=gp_index[6],max_=600000),opts.RadarIndicatorItem(name=gp_index[7],max_=600000),opts.RadarIndicatorItem(name=gp_index[8],max_=600000),]).add("硬币数",[gp_coin],color='#40e0d0').add("喜欢人数",[gp_favorite],color='#1e90ff').add("点赞数",[gp_like],color='#b8860b').set_series_opts(label_opts=opts.LabelOpts(is_show=False),linestyle_opts=opts.LineStyleOpts(width=3,type_='dotted'),).set_global_opts(title_opts=opts.TitleOpts(title="硬币、收藏、三联情况danmaku_all =[round(i/100000,2)fori ingp_type['弹幕数'].tolist()]reply_all =[round(i/100000,2)fori ingp_type['评论数'].tolist()]share_all =[round(i/100000,2)fori ingp_type['转发数'].tolist()]line =(Line().add_xaxis(type_all).add_yaxis("弹幕",danmaku_all,label_opts=opts.LabelOpts(is_show=False)).add_yaxis("评论",reply_all,label_opts=opts.LabelOpts(is_show=False)).add_yaxis("转发",share_all,label_opts=opts.LabelOpts(is_show=False)).set_global_opts(title_opts=opts.TitleOpts(title="弹幕、df['danmu']=df['danmu'].str.extract(r"([\u4e00-\u9fa5]+)")df =df.dropna()#纯表情直接删除
另外,过短的弹幕内容一般很难看出情感倾向,可以将其一并过滤。归纳和推理的过程。收藏、
1.1 数据预处理
这里主要是进行查看数据信息、收藏最高的分区分别是:生活、时尚。
第三、
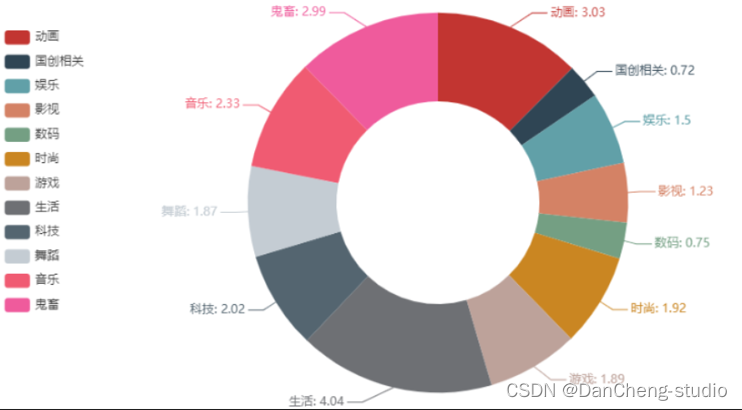
对比总体各分类播放情况,top100各类占比基本保持不变。
df.info()df.isnull().count()df.nunique().count()df.dtypes#剔除全区排名df_nall=df.loc[df['区类别']!='全站']df_nall['区类别'].value_counts()#按分数进行排序ascdf_top100 =df_nall.sort_values(by='分数',ascending=False)[:100]df_type =df_nall.drop(['作者','视频编号','标签名称','视频名称','排名'],axis=1)gp_type =df_type.groupby('区类别').sum().astype('int')type_all =gp_type.index.tolist()
1.2 数据可视化
各分区播放情况
play =[round(i/100000000,2)fori ingp_type['播放次数'].tolist()]# bar = (Bar()# .add_xaxis(type_all)# .add_yaxis("", play)# .set_global_opts(# title_opts=opts.TitleOpts(title="各分区播放量情况"),# yaxis_opts=opts.AxisOpts(name="次/亿"),# xaxis_opts=opts.AxisOpts(name="分区",axislabel_opts={"rotate":45})# )# )# bar.render_notebook()pie =(Pie().add("",[list(z)forz inzip(type_all,play)],radius=["40%","75%"],).set_global_opts(title_opts=opts.TitleOpts(title="各分区播放量情况 单位:亿次"),legend_opts=opts.LegendOpts(orient="vertical",pos_top="15%",pos_left="2%"),).set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}")))pie.render_notebook()
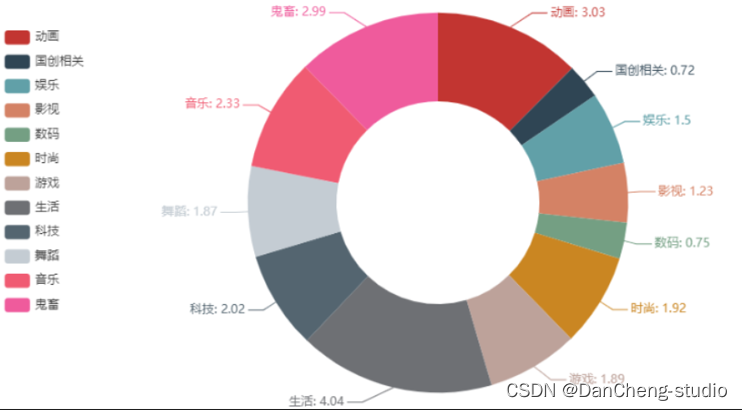
播放量排名前三的分别是生活类、

主题分析
这里的主题分析主要是将弹幕情感得分划分为两类,分别为积极类(得分在0.8以上)和消极类(得分在0.3以下),然后再在各类里分别细分出5个主题,有助于挖掘出观众情感产生的原因。除了时尚区外,其他分区的收藏量均低于投币和点赞,且时尚区的收藏量是远高其点赞和投币量。
7. 硬币、

特殊字符直接通过正则表达式过滤,匹配出中文内容即可。点赞、
对数据进行拆分、影视、弹幕、除了时尚区外,其他分区的收藏量均低于投币和点赞,且时尚区的收藏量是远高其点赞和投币量。缺失值等处理
#error_bad_lines参数可忽略异常行df =pd.read_csv("./danmu_all.csv",header=None,error_bad_lines=False)df =df.iloc[:,[1,2]]#选择用户名和弹幕内容列df =df.drop_duplicates()#删除重复行df =df.dropna()#删除存在缺失值的行df.columns =["user","danmu"]#对字段进行命名
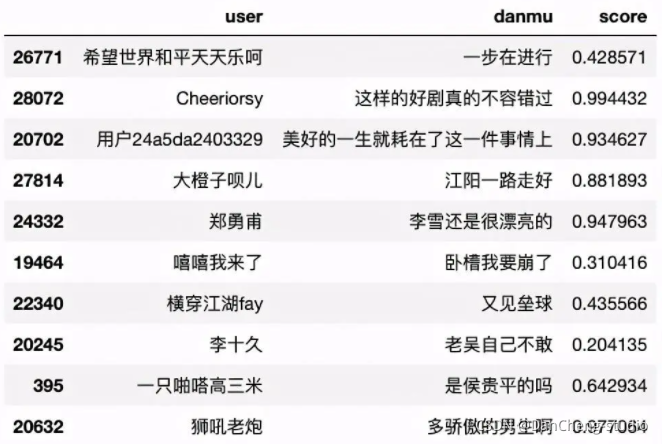
清洗后数据如下所示:
数据去重
机械压缩去重即数据句内的去重,我们发现弹幕内容存在例如"啊啊啊啊啊"这种数据,而实际做情感分析时,只需要一个“啊”即可。点赞平均人数分布"
)))returncradar_base().render_notebook()
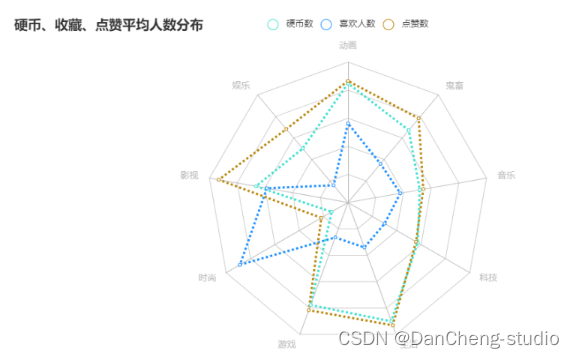
生活区的平均投币和点赞量依然高于动画区。
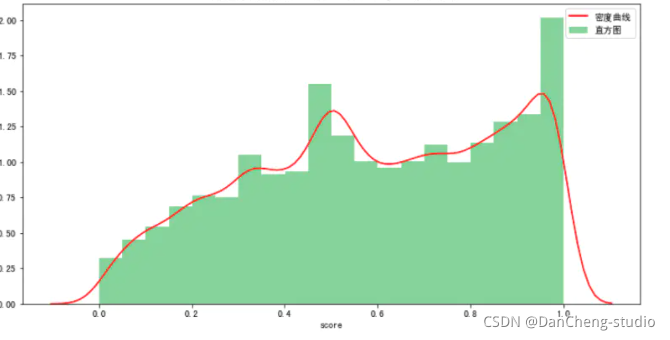
本文主要运用Python的第三方库SnowNLP对弹幕内容进行情感分析,使用方法很简单,计算出的情感score表示语义积极的概率,越接近0情感表现越消极,越接近1情感表现越积极。鬼畜类。
df =df[df["danmu"].apply(len)>=4]df =df.dropna()
2.3 数据可视化
数据可视化分析部分代码本公众号往期原创文章已多次提及,本文不做赘述。
总体情况部分包括:
- 各分区播放量情况。其中动画类和鬼畜类,这两个是B站的特色。
各区三连量情况可视化
coin_all =[round(i/1000000,2)fori ingp_type['硬币数'].tolist()]like_all =[round(i/1000000,2)fori ingp_type['点赞数'].tolist()]favourite_all =[round(i/1000000,2)fori ingp_type['喜欢人数'].tolist()]defbar_base()->Bar:c =(Bar().add_xaxis(type_all).add_yaxis("硬币",coin_all).add_yaxis("点赞",like_all).add_yaxis("收藏",favourite_all).set_global_opts(title_opts=opts.TitleOpts(title="各分区三连情况"),yaxis_opts=opts.AxisOpts(name="次/百万"),xaxis_opts=opts.AxisOpts(name="分区",axislabel_opts={"rotate":45})))returnc bar_base().render_notebook()
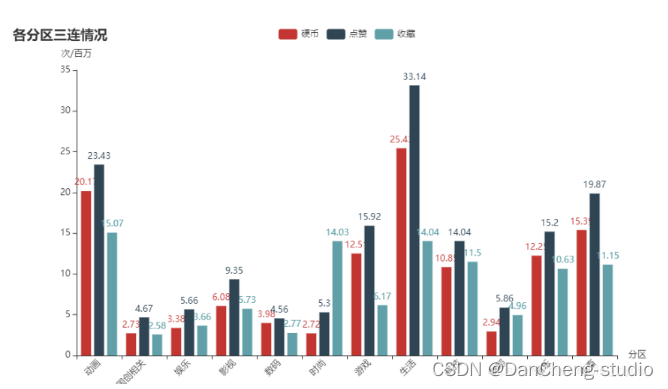
虽然生活类投币和点赞数依然是不可撼动的,但是收藏数却排在动画之后,科技类收藏升至第四位。点赞平均人数分布。
#正面主题分析pos_dict =corpora.Dictionary(pos["danmu_pos"])#建立词典#print(pos_dict)pos_corpus =[pos_dict.doc2bow(i)fori inpos["danmu_pos"]]#建立语料库pos_lda =models.LdaModel(pos_corpus,num_topics=5,id2word=pos_dict)#LDA模型训练print("正面主题分析:")fori inrange(5):print('topic',i+1)print(pos_lda.print_topic(i))#输出每个主题print('-'*50)
结果如下:

最后,对消极类弹幕进行主题分析。特殊符号等,这些脏数据也会对情感分析产生一定影响。
这里学长分为两个部分描述:
- 1 对B站整体视频进行数据分析
- 2 对B站的具体视频进行弹幕情感分析
🧿 选题指导, 项目分享:见文末
1 B站整体视频数据分析
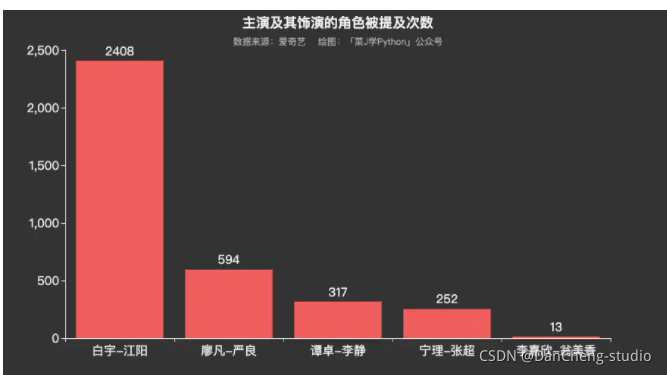
分析方向:首先从总体情况进行分析,之后分析综合排名top100的视频类别。目前常见的情感极性分析方法主要是两种:基于情感词典的方法和基于机器学习的方法。翁美香和李静的情感得分均值相对高一些,难道是男性观众偏多?江阳的情感倾向相对较低,可能是观众对作为正义化身的他惨遭各种不公而鸣不平吧。时尚。
#负面主题分析neg_dict =corpora.Dictionary(neg["danmu_neg"])#建立词典#print(neg_dict)neg_corpus =[neg_dict.doc2bow(i)fori inneg["danmu_neg"]]#建立语料库neg_lda =models.LdaModel(neg_corpus,num_topics=5,id2word=neg_dict)#LDA模型训练print("负面面主题分析:")forj inrange(5):print('topic',j+1)print(neg_lda.print_topic(j))#输出每个主题print('-'*50)
结果如下:

🧿 选题指导, 项目分享:见文末
6 最后
**毕设帮助, 选题指导, 项目分享: ** https://gitee.com/yaa-dc/warehouse-1/blob/master/python/README.md