模版链接如下:
https://mp.weixin.qq.com/mp/profile_ext?action=home&__biz=xxxxxx
找一篇公众号文章,通过浏览器打开,按F12获取biz=MzkyNDY2OTgzOQ%3D%3D
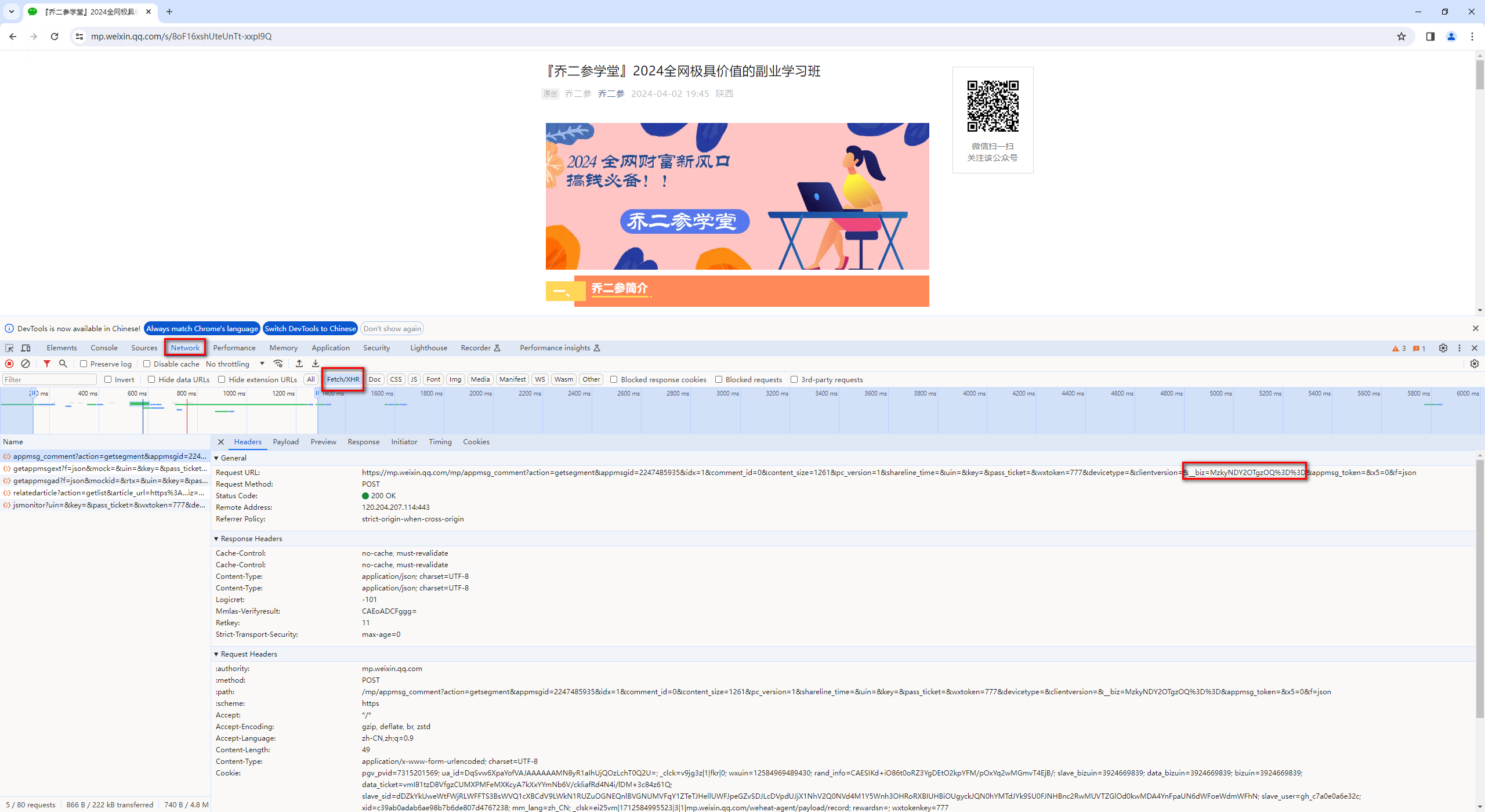
替换模版链接中的biz使用微信浏览器打开
https://mp.weixin.qq.com/mp/profile_ext?action=home&__biz=MzkyNDY2OTgzOQ%3D%3D
下载地址:
https://reqable.com/zh-CN/
代理配置:打开工具后一般会自动配置这个,如果没有的话自己配置一下
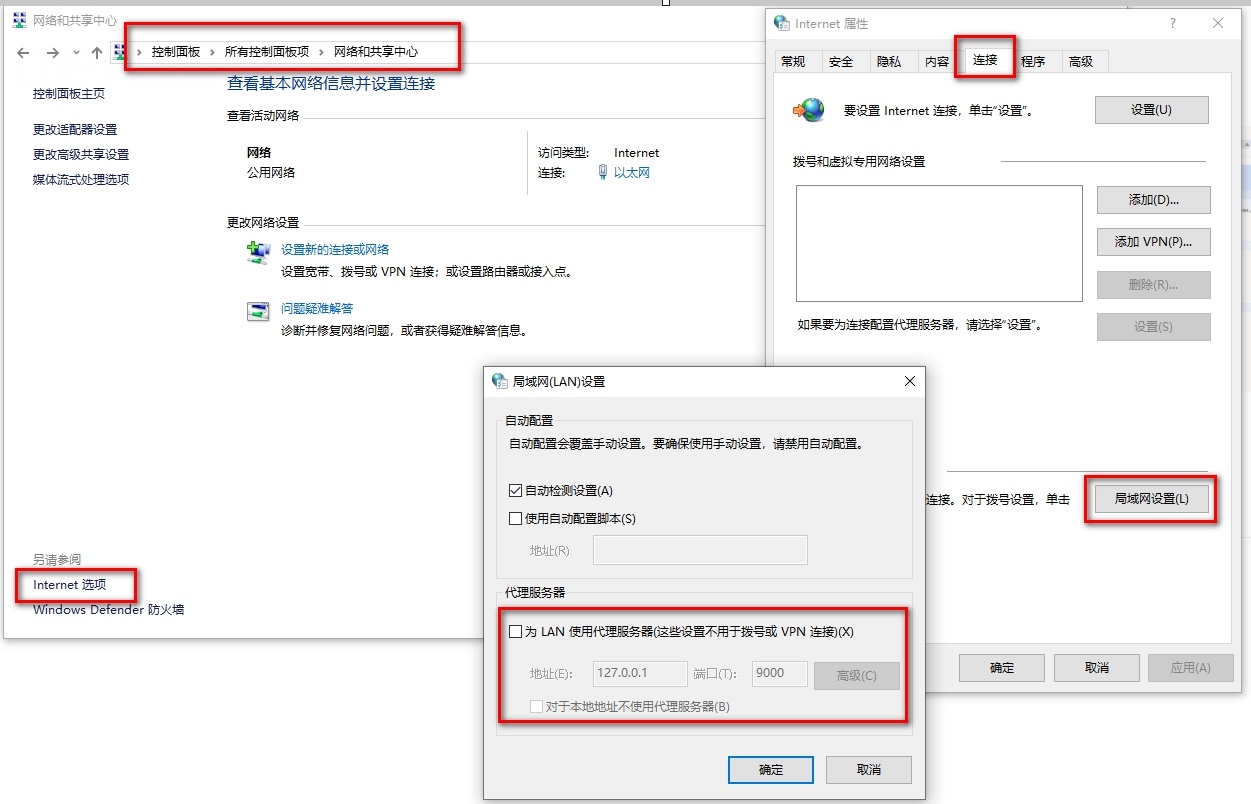
打开抓包工具之后,点击启动。
关注目标公众号,并在微信中打开目标公众号的首页地址
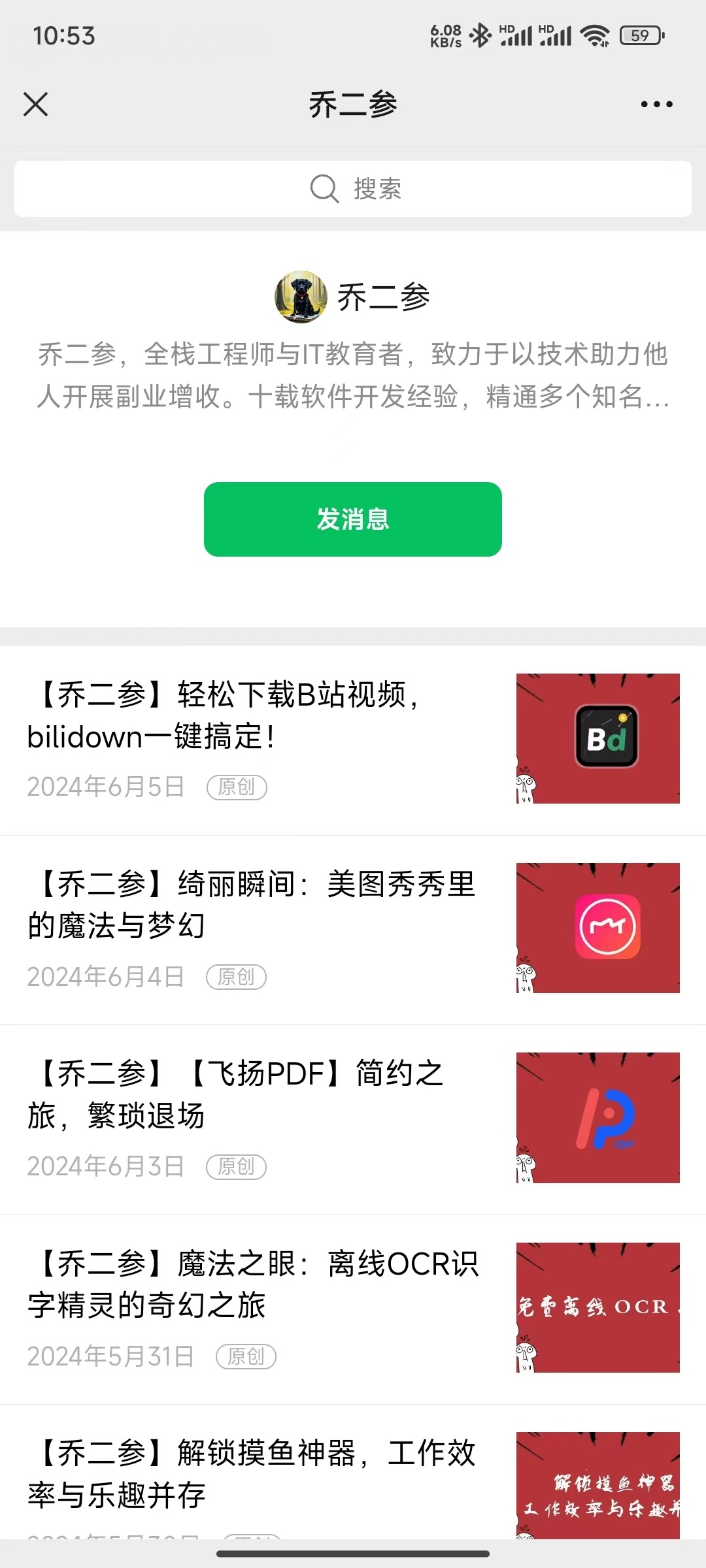
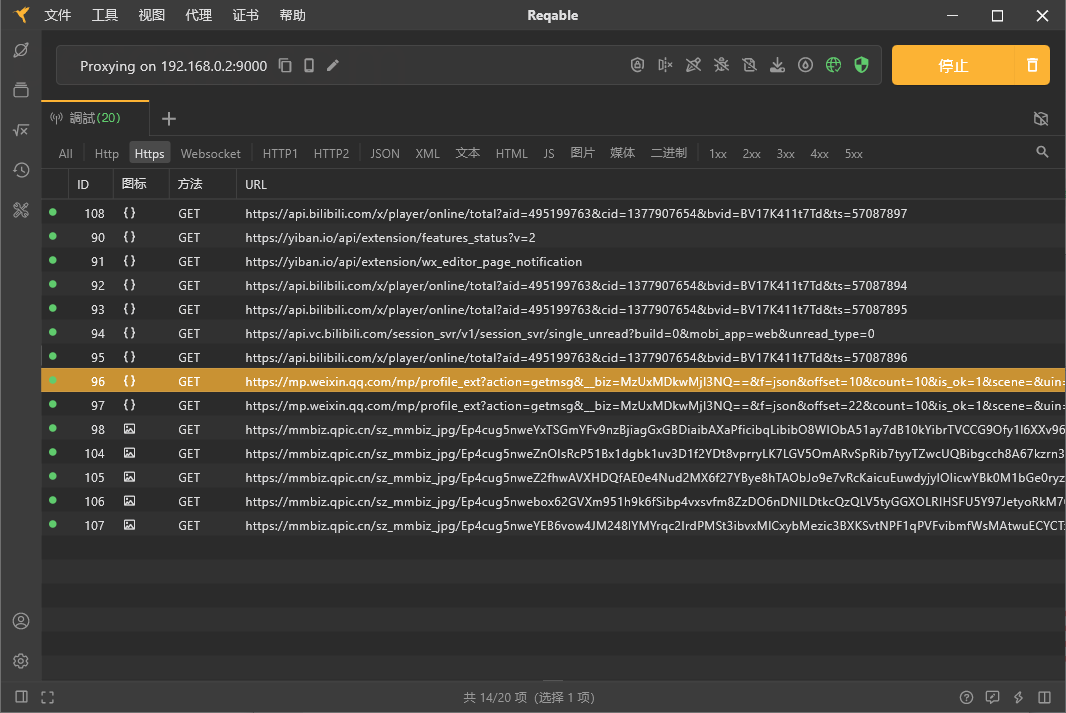
下拉浏览公众号历史文章,在抓包工具中获取公众号历史文章接口
offset=0&count=10 这两个参数是抓取数据的关键
使用在线格式化工具
https://kgtools.cn/compression/header
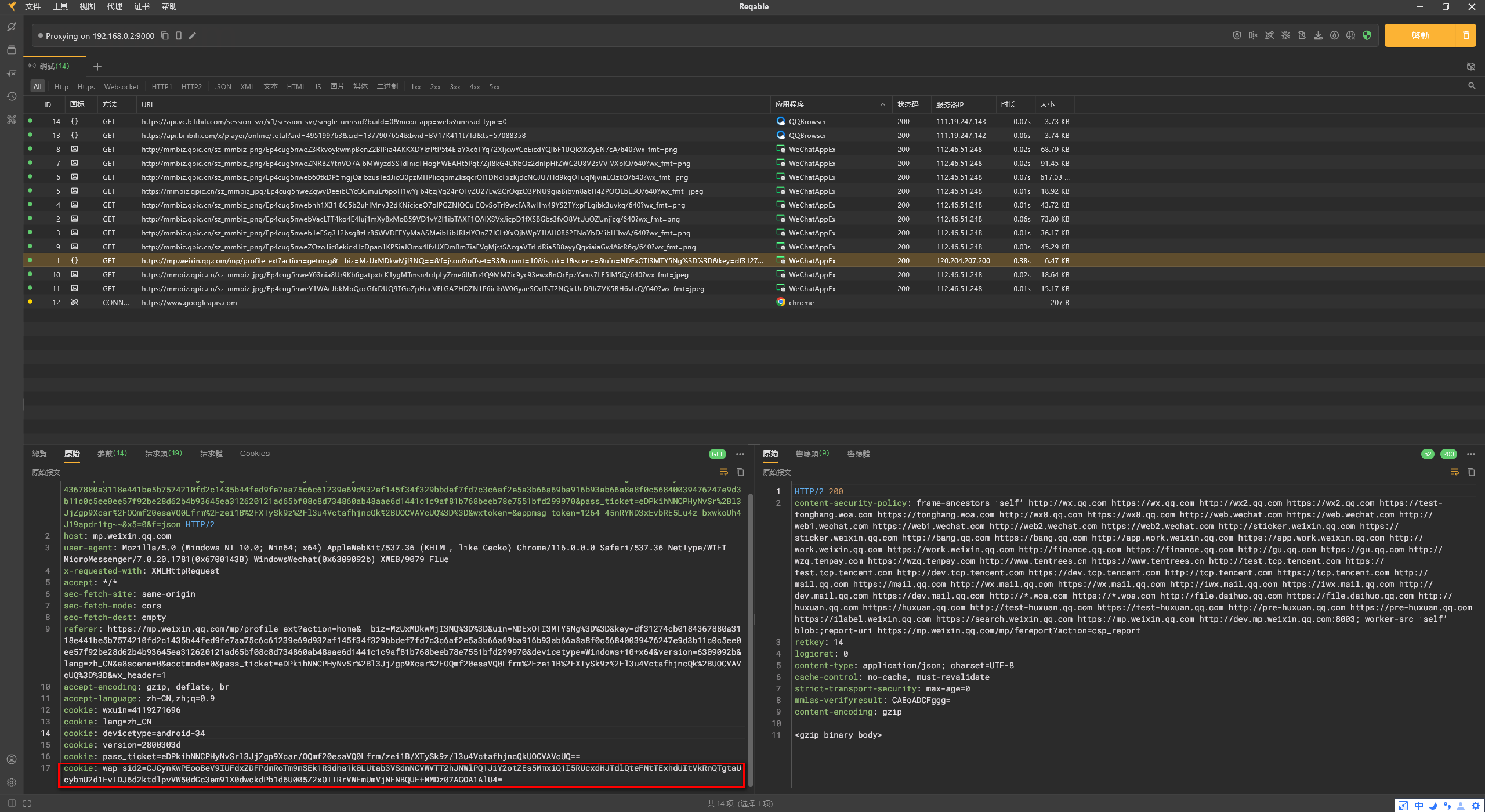
使用则表达式替换
(.*?):(.*) 替换为 '1':'$2',由于抓包工具的cookie显示成多个,header处理的时候先不管cookie
两种cookie内容不一样,任意选一种就可以了
抓包工具的最后一行cookie值也可以使用
使用浏览器打开目标URL,按F12获取cookie
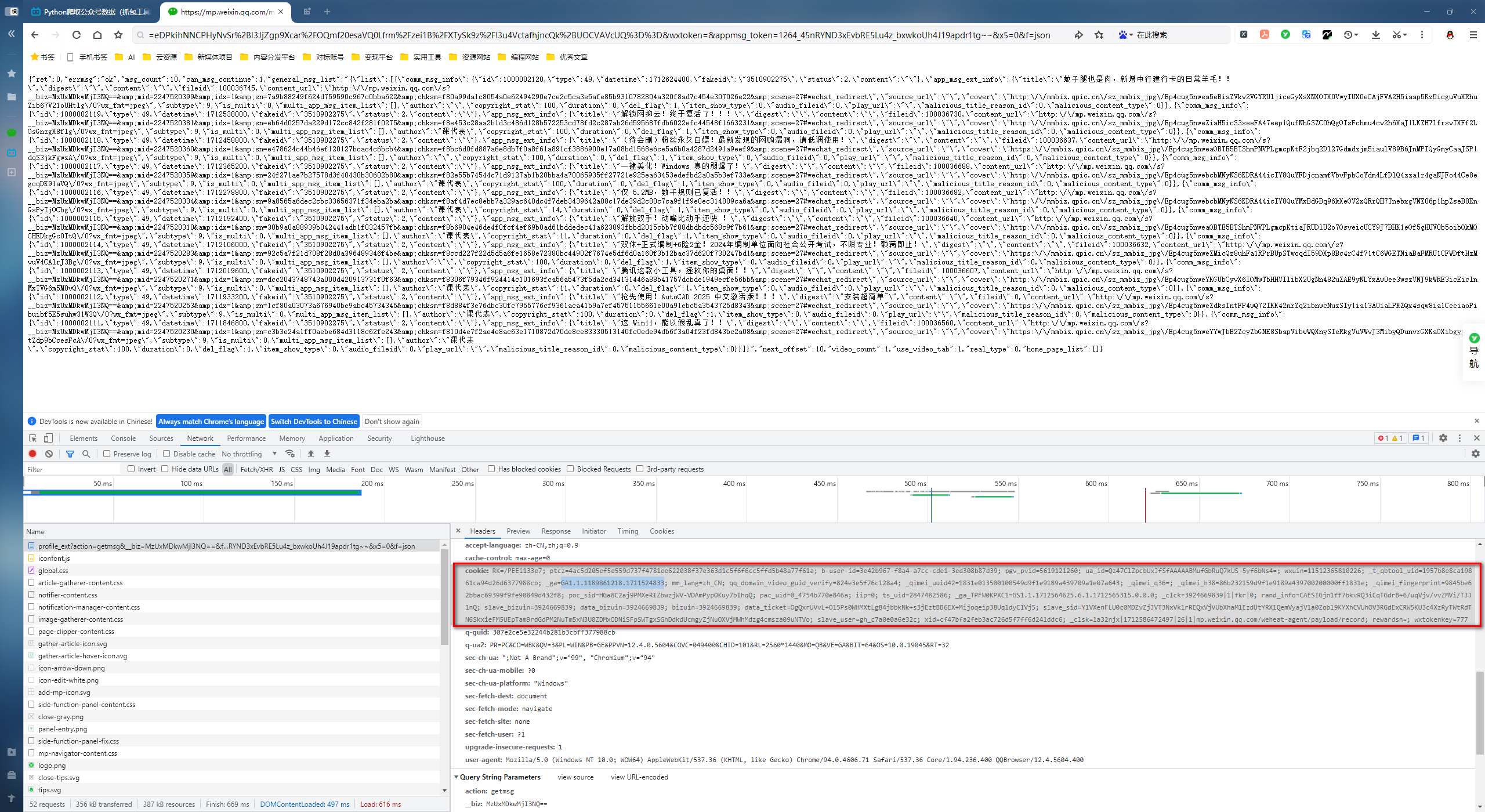
由于cookie有时效性,当失效的时候需要重新抓包获取cookie
获取到原始数据之后就可以根据自己的业务逻辑进行处理了
# 导入依赖importrequests# 找到数据来源# https://mp.weixin.qq.com/mp/profile_ext?action=getmsg&__biz=MzUxMDkwMjI3NQ==&f=json&offset=22&count=10&is_ok=1&scene=&uin=NDExOTI3MTY5Ng%3D%3D&key=df31274cb01843671e8924a1ddb0a0a019eb5018d8976a8aefea0104e84a7ae9df90e2f5abebb9424c6420632271e97a016875dcabb2fc9d509edcd59cde65ebb5d23422f65fb76a9911b898014cb76988c544c5242d64293df6438604eef0c05de8c2b0c4f8a674ebb545444525579e9bc0f30e4cd0b85361851acc9a6e36d2&pass_ticket=eDPkihNNCPHyNvSr%2Bl3JjZgp9Xcar%2FOQmf20esaVQ0IQTviLsLUlgUAGpS06V0703%2FF9NCSRL2zsHv0HTKxkDQ%3D%3D&wxtoken=&appmsg_token=1264_uk0unMYho0t%252BNC3mb7IM_h5C5gDYjLX19ZGflw~~&x5=0&f=json# 目标链接url ='https://mp.weixin.qq.com/mp/profile_ext?action=getmsg&__biz=MzUxMDkwMjI3NQ==&f=json&offset=0&count=10&is_ok=1&scene=&uin=NDExOTI3MTY5Ng%3D%3D&key=df31274cb0184367880a3118e441be5b7574210fd2c1435b44fed9fe7aa75c6c61239e69d932af145f34f329bbdef7fd7c3c6af2e5a3b66a69ba916b93ab66a8a8f0c56840039476247e9d3b11c0c5ee0ee57f92be28d62b4b93645ea312620121ad65bf08c8d734860ab48aae6d1441c1c9af81b768beeb78e7551bfd299970&pass_ticket=eDPkihNNCPHyNvSr%2Bl3JjZgp9Xcar%2FOQmf20esaVQ0Lfrm%2Fzei1B%2FXTySk9z%2Fl3u4VctafhjncQk%2BUOCVAVcUQ%3D%3D&wxtoken=&appmsg_token=1264_45nRYND3xEvbRE5Lu4z_bxwkoUh4J19apdr1tg~~&x5=0&f=json'# 定义请求头cookie ='wap_sid2=CJCynKwPEooBeV9IUFdxZDFPdmRoTm9mSEk1R3dha1k0LUtab3VSdnNCVWVTT2hJNWlPQ1JiY2otZEs5MmxiQ1I5RUcxdHJTdlQteFMtTExhdUItVkRnQTgtaUcybmU2d1FvTDJ6d2ktdlpvVW50dGc3em91X0dwckdPb1d6U005Z2xOTTRrVWFmUmVjNFNBQUF+MMDz07AGOA1AlU4='headers ={ 'host':'mp.weixin.qq.com','user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36 NetType/WIFI MicroMessenger/7.0.20.1781(0x6700143B) WindowsWechat(0x6309092b) XWEB/9079 Flue','x-requested-with':'XMLHttpRequest','accept':'*/*','sec-fetch-site':'same-origin','sec-fetch-mode':'cors','sec-fetch-dest':'empty','referer':'https://mp.weixin.qq.com/mp/profile_ext?action=home&__biz=MzUxMDkwMjI3NQ%3D%3D&uin=NDExOTI3MTY5Ng%3D%3D&key=df31274cb01843671e8924a1ddb0a0a019eb5018d8976a8aefea0104e84a7ae9df90e2f5abebb9424c6420632271e97a016875dcabb2fc9d509edcd59cde65ebb5d23422f65fb76a9911b898014cb76988c544c5242d64293df6438604eef0c05de8c2b0c4f8a674ebb545444525579e9bc0f30e4cd0b85361851acc9a6e36d2&devicetype=Windows+10+x64&version=6309092b&lang=zh_CN&a8scene=0&acctmode=0&pass_ticket=eDPkihNNCPHyNvSr%2Bl3JjZgp9Xcar%2FOQmf20esaVQ0IQTviLsLUlgUAGpS06V0703%2FF9NCSRL2zsHv0HTKxkDQ%3D%3D&wx_header=1','accept-encoding':'gzip, deflate, br','accept-language':'zh-CN,zh;q=0.9','cookie':cookie}# 获取网页res =requests.get(url=url,headers=headers)# 打印内容print(res.text){ "base_resp":{ "ret":-3,"errmsg":"no session","cookie_count":0},"ret":-3,"errmsg":"no session","cookie_count":0}{ 'ret': 0, 'errmsg': 'ok', 'msg_count': 0, 'can_msg_continue': 0, 'general_msg_list': '{ "list":[]}', 'next_offset': 5000, 'video_count': 1, 'use_video_tab': 1, 'real_type': 0, 'home_page_list': []}{ 'ret': -6, 'errmsg': 'unknown error', 'home_page_list': []}# 导入依赖import requestsimport jsonimport urllib.parseimport datetimeimport timeimport random# 获取url参数def extract_url_params(url): params = { } parsed_url = urllib.parse.urlparse(url) query_string = parsed_url.query if query_string: query_params = urllib.parse.parse_qs(query_string) for key, value in query_params.items(): params[key] = value[0] return params# 判断值是否为空def is_value_empty(value): return value is None or value == "" or value == [] or value == { }# 将文章列表写入csv文件def write_article_list_to_csv(article_list): with open('article_list.csv', 'a', encoding='utf-8') as f: f.write('文章标题,文章地址,发布时间\n') for article in article_list: f.write(f'{ article["title"]},{ article["content_url"]},' f'{ datetime.datetime.fromtimestamp(article["datetime"])}\n')# 获取公众号文章列表def get_article_list(refer): # 定义文章列表 article_list = [] # 目标链接 url = 'https://mp.weixin.qq.com/mp/profile_ext' # 定义请求头 headers = { 'host': 'mp.weixin.qq.com', 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36 NetType/WIFI MicroMessenger/7.0.20.1781(0x6700143B) WindowsWechat(0x6309092b) XWEB/9079 Flue', } # 获取refer链接中的参数 refer_params = extract_url_params(refer) # 定义请求参数 params = { 'action': 'getmsg', '__biz': refer_params['__biz'], 'offset': 0, 'count': 10, 'uin': refer_params['uin'], 'key': refer_params['key'], 'pass_ticket': refer_params['pass_ticket'], 'f': 'json' } while True: # 随机时间20-30S time.sleep(random.randint(20, 30)) # 发送请求 res = requests.get(url=url, headers=headers, params=params) # 获取json数据 json_data = res.json() if json_data['ret'] == -6: print(json_data) print('爬虫速度太快被封了...') break elif json_data['ret'] == -3: print(json_data) print('会话过期了...') break elif json_data['ret'] == 0: if 'can_msg_continue' in json_data: # 获取general_msg_list 这是一个字符串需要格式化成json数据 general_msg_list = json.loads(json_data['general_msg_list']) # 遍历list数据 for msg in general_msg_list['list']: if 'app_msg_ext_info' in msg and 'comm_msg_info' in msg: # 获取标题 title = msg['app_msg_ext_info']['title'] # 获取链接 content_url = msg['app_msg_ext_info']['content_url'] # 获取发布时间 datetime = msg['comm_msg_info']['datetime'] # 标题 链接 发布时间 有一个为空就不处理 if is_value_empty(title) or is_value_empty(content_url) or is_value_empty(datetime): continue article_list.append({ 'title': title, 'content_url': content_url, 'datetime': datetime}) print(title, content_url) # 没有数据退出 can_msg_continue = json_data['can_msg_continue'] if can_msg_continue == 0: print('数据读取完毕!') print(json_data) break # 获取下一次的偏移 params['offset'] = json_data['next_offset'] # 将文章列表写入csv文件 write_article_list_to_csv(article_list)if __name__ == '__main__': refer = 'https://mp.weixin.qq.com/mp/profile_ext?action=home&__biz=MzkzOTIwMjkyMg==&uin=MjI4OTEzMzMwMQ%3D%3D&key=0e25620c5de632befc36897216780fd24f1198cfede94a6e8a9f71139b940c2a2338bb0ea32efc7069b32659ab29f038474583a26a9446e010603f6662787f2b6fcd81a432d8530af7f2acdba318632b557b97cd65e9bfa716f542d87f30578f6bff657b611e0a7587f3864942fd46ab4ee37ed36a623418028c89e67fe327ee&devicetype=Windows+10+x64&version=6309092b&lang=zh_CN&a8scene=0&acctmode=0&pass_ticket=TzBKMHSun3KkQLaEApYHnWfMot5QQXiQSTLU0VYg4xN3LWA0wbcJ0O6HjSR9W4tnT3z5JIM9a73asCxiskMLbQ%3D%3D&wx_header=1' start_time = time.time() get_article_list(refer) end_time = time.time() print("爬取数据耗时:", end_time - start_time)