


























chatGPT开源的whisper音频生成字幕
1、前言。
好了,接下来看一看。whisper。介绍开源库。
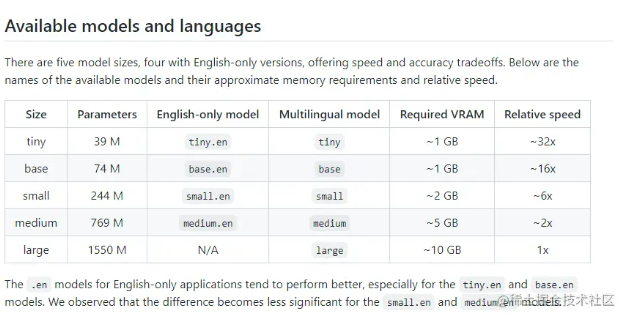
有五种模型大小,四种只支持英语权衡速度和准确性。以上是可用模型的名称、一般内存需求和相对速度。如果是英文版的语音,直接想转换成英语。
本来想直接在本地电脑上安装环境,也就是说,无非是安装python、ffmpeg、以及whisper,但是发现电脑配置太低,而且我想测试一下。large。模型,CPU。肯定不行,但是如果使用本机的话。 GPU。也快不到哪里去了。 所以我想到了谷歌的colab.research.google.com 免费在线运行并且我可以使用GPU硬件加速,感觉还是很快的,如果需要的话,当然也可以买。
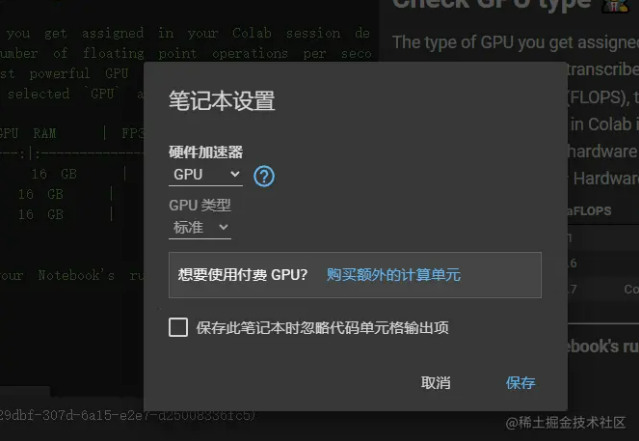
以下是我的免费配置 colab.research.google.com。
操作还是很流畅的,真的很香真的很好吃c;如果需要的话,我想付钱。
适用于这些场景。
- 会议记录: 将录音直接转换成文字。
- 个人视频制作: 很多时候,我希望有字幕效果,听说剪映效果不如这个。
- 课堂记录转写:记录课堂上的内容,直接查看文字版本也很方便。
- 通话记录:一些重要的电话可以录音,以后查询转换成文字也很好。
- 字幕组:不用说 也有可能涉及多语言如果准备率很高 它可以节省很多东西。
- 实时语音翻译:如果服务器配置足够高,,理论上很快。
2、开始实践。
2.1、检查colab环境。
!nvidia-smi -L!nvidia-smi。
两个指令的运行结果如下::
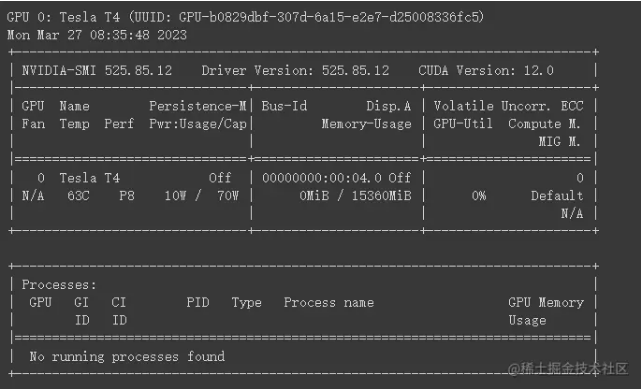
1.!nvidia-smi -L。:-L。列出系统上安装的所有参数 NVIDIA GPU 设备。运行此命令后您将看到关于可用性的信息 GPU 信息,包括它的型号和型号 UUID。
2.!nvidia-smi。:运行无任何参数。 nvidia-smi。会显示有关 NVIDIA GPU 详细信息,包括:
- GPU 设备的编号、名称、总内存和温度。
- GPU 使用率(例如,内存和视频内存的利用率)。
- 运行在 GPU 过程及其相关信息(如进程 ID、#xff09显示器占用等;。
只是我还没有开始在这里使用GPU,因此显示的是空的。
2.2、安装whisper。
!pip install requests beautifulsoup4!pip install git+https://github.com/openai/whisper.gitimport torchimport sysdevice = torch.device('cuda:0')print('使用的设备:', device, file=sys.stderr)print('Whisper已经安装,请执行下一个单元')。这里主要是安装。这里主要是安装。

whisper。
2.3、 选择whisper模型。
#@markdown # ** whisper Model选择** 🧠Model = 'large-v2' #@param ['tiny.en', 'tiny', 'base.en', 'base', 'small.en', 'small', 'medium.en', 'medium', 'large', 'large-v2']import whisperfrom IPython.display import Markdownwhisper_model = whisper.load_model(Model)if Model in whisper.available_models(): display(Markdown( f"**{ Model} model is selected.**" ))else: display(Markdown( f"**{ Model} model is no longer available.** Please select one of the following: - { ' - '.join(whisper.available_models()}" ))。 我在这里选择最大的模型。我在这里选择最大的模型。
large-v2。
,因为我想转换中文字幕前四个只支持英语,文章开头也提到了这一点。
2.4、 开始将音频转换为字幕。
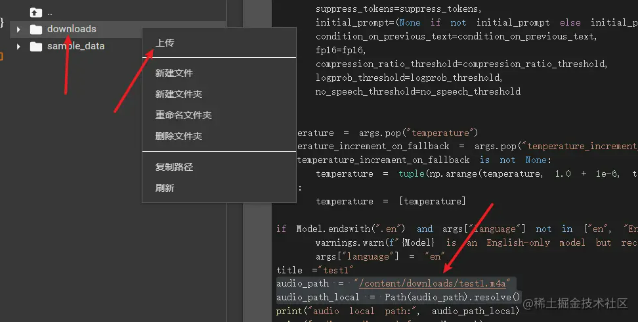
audio_path = "/content/downloads/test1.m4a"audio_path_local = Path(audio_path).resolve()transcription = whisper.transcribe( whisper_model, str(audio_path_local), temperature=temperature, **args,)# Save outputwhisper.utils.get_writer( output_format=output_format, output_dir=audio_path_local.parent)( transcription, title)。首先要准备m4a的音频文件,可直接上传到colab。首先要准备m4a的音频文件,这里可以直接上传到colab
左边目前的目录是 content,然后右键新建文件夹。
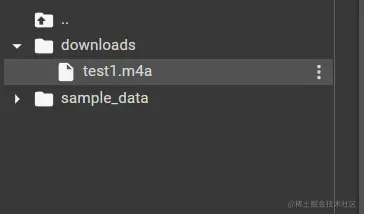
downloads。,然后在downloads文件夹上点击上传m4a文件。
上传后可以看到m4a文件已经在目录下了。whisper.transcribe。该方法有许多参数。whisper_model。主要设置model模型。output_format。文件格式主要设置字幕输出。temperature。低值设置,所以表达相对准确,表达价值越大,可能就越抽象。args。language语言,例如,在这里我要把音频转换成中文字幕 设置为。cn。
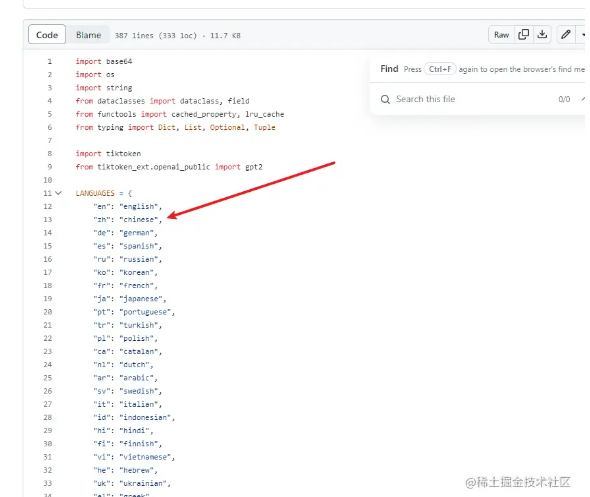
或者。
chinese。
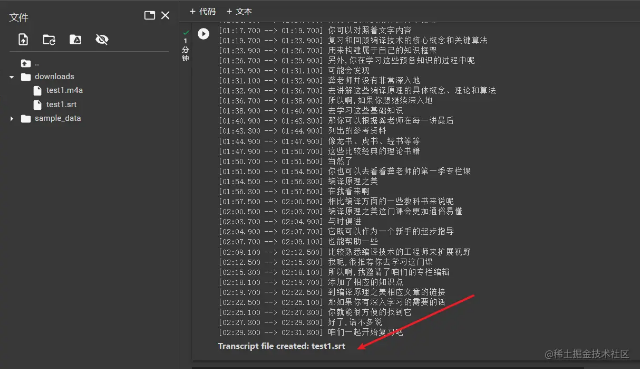
主要可以在这里查看 whisper/tokenizer.py at main · openai/whisper · GitHub。2.4、操作检查效果。点击操作后,可以看到一段一段的执行转换,整体感觉操作还是很流畅的,这比其他人在当地运行要快得多。
最后,我们可以看到srt字幕文件已经生成,点击左侧文件直接下载即可。 生成的。
srt。
文件如下。
3、总结。
这个whisper相当于离线版本,可自行部署到本地或服务器,供自己使用,相信后续OpenAI应该会更新,提供更多精彩的功能使用。
from:。5、whisper音频生成字幕可以本地建设环境运行阿里云开发者社区的效果质量很好。远程控制kkview 手机电脑看屏幕和摄像头。分享让更多人看到 
热门排行
- 1你用过吗 50多家银行暂停了自动取款机的扫码和取款业务
- 2英语不见了!特斯拉FSD在中国正式命名为智能辅助驾驶!
- 3【大语言模型的漏洞与“越狱”】GPT、Llama等模型全部中招!
- 4亚信科技入选中国信通院计算服务业图谱 “产品名录”入选系列产品
- 5javax.servlet 和 jakarta.使用tomcat部署servlet与servlet的关系 jakarta.servlet
- 6玩转云计算:教你Akamai IT架构构构建在Linode上–定义项目
- 7JetBrains AI Asssistant使用指南(1)
- 8联想GeekPro14代酷版游戏台机超值
- 9Web⾃动化测试及常用函数
- 10java web的中小型人力资源管理系统 源码+论文
人民日报社概况| 关于人民网| 报社招聘| 招聘英才| 广告服务| 合作加盟| 供稿服务| 数据服务| 网站声明| 网站律师| 信息保护| 联系我们
人民日报违法和不良信息举报电话:010-65363263 举报邮箱:jubao@people.cn
人民网服务邮箱:kf@people.cn 违法和不良信息举报电话:010-65363636 举报邮箱:rmwjubao@people.cn
互联网新闻信息服务许可证10120170001 | 增值电信业务经营许可证B1-20060139 | 广播电视节目制作经营许可证(广媒)字第172号 | 京ICP备12004265号-13
信息网络传播视听节目许可证0104065 | 网络文化经营许可证 京网文[2023]4961-141号 | 网络出版服务许可证(京)字121号 | 京ICP证000006号 | 京公网安备11000002000008号
人 民 网 股 份 有 限 公 司 版 权 所 有 ,未 经 书 面 授 权 禁 止 使 用
Copyright © 1997-2024 by www.people.com.cn. all rights reserved





